Masked Autoencoders Are Effective Tokenizers for Diffusion Models (ICML 2025 Spotlight)
1. Introduction
Background: Diffusion models
- 초창기: Pixel space
- 이후: Latent space (feat. LDM)
- LDM: Tokenizers (보통 VAE 기반)로 차원 축소된 latent space에서 학습/생성
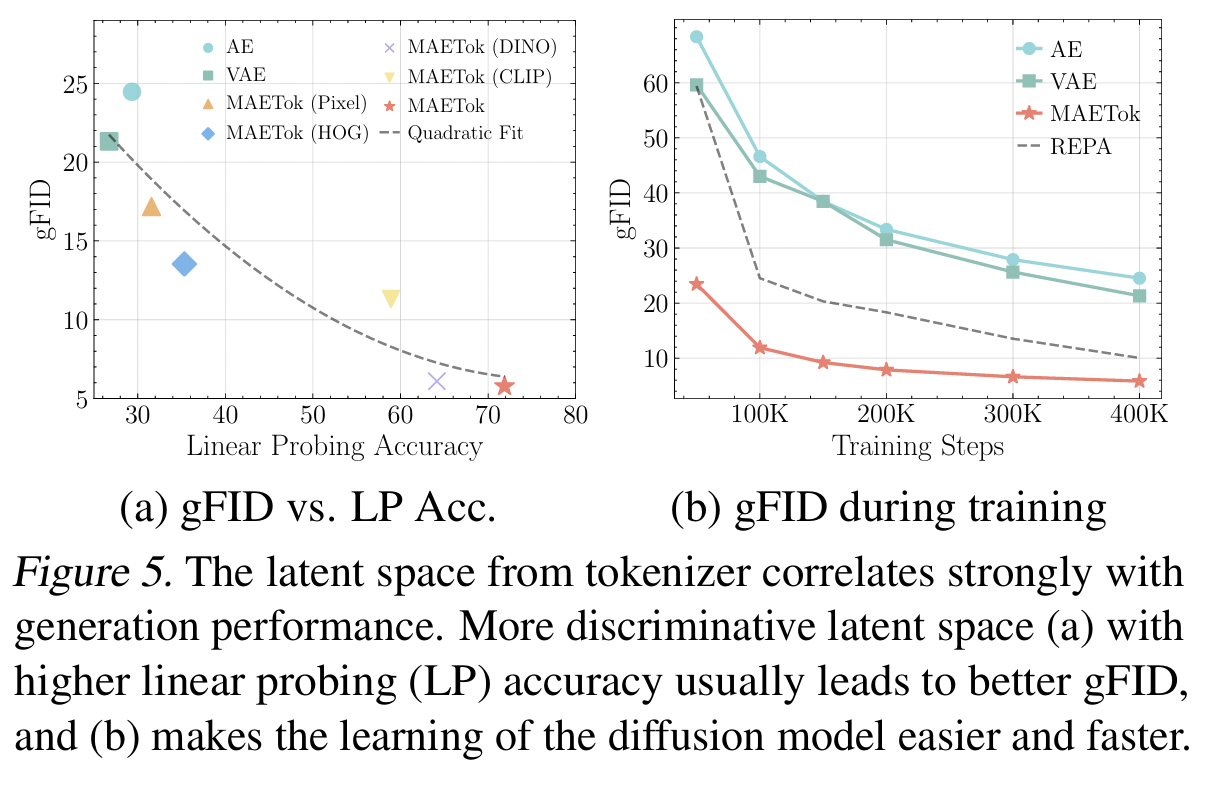
Question: 어떤 latent space가 diffusion 학습에 좋은가?
- VAE: smooth distribution은 만들지만 pixel fidelity가 떨어짐.
- AE: pixel fidelity는 높지만 latent space 구조가 복잡하고 entangled
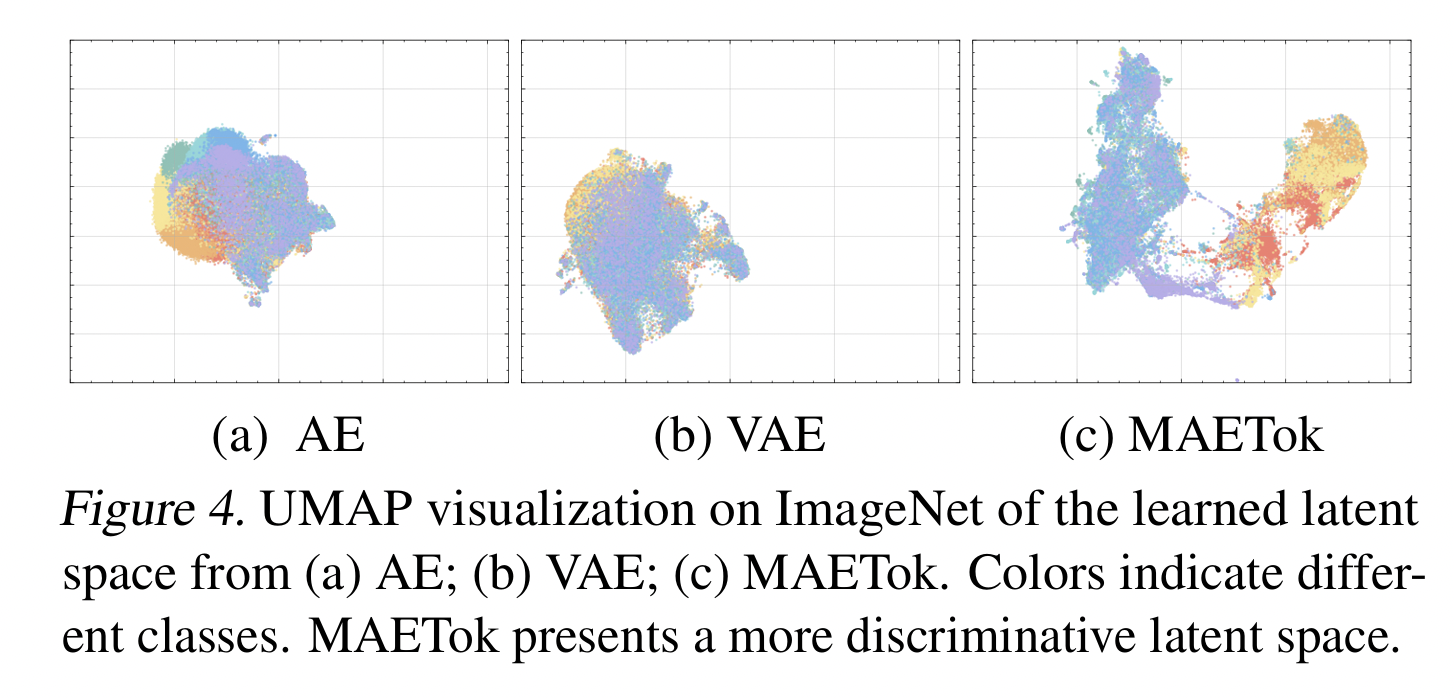
Proposal: Masked Autoencoder(MAE) 방식을 tokenizer로 활용
- discriminative latent space 제공
- variational constraint 불필요
- 더 효율적이고 성능 좋은 diffusion 모델 학습 가능
2. On the Latent Space and Diffusion Models
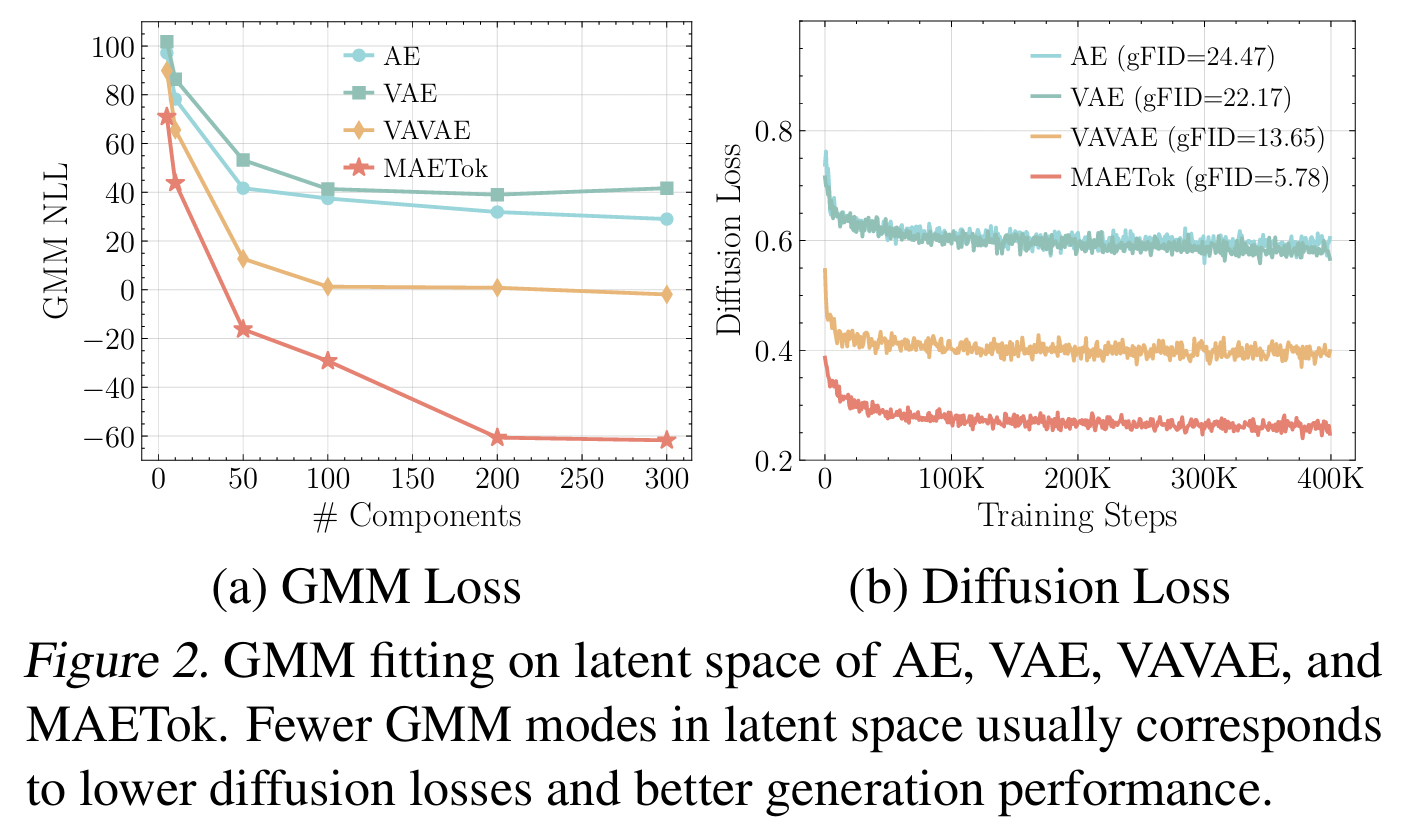
[Empirical analysis]: Latent space의 구조를 GMM으로 fitting.
-
Latent space의 mode 수가 많으면….
\(\rightarrow\) (Entangled) diffusion loss ↑ & gFID(생성 품질) ↓.
-
Fewer modes → More discriminative → Diffusion 학습 쉬워지고 생성 품질 높음!
- Q) mode가 많으면, 오히려 클래스별로 구분된다는 뜻 아닌지?
- A)
- No! 같은 클래스가 이곳저곳에 흩어져있다는 뜻
- Class별로 구분이 아니라 class 내부적으로도 더 많은 모드가 생기니, entangled 구조
[Theoretical analysis]:
- GMM 모드 수 \(K\)가 많을수록 diffusion training에 더 많은 sample 필요.
- 따라서 finite data setting에서 K가 많으면 generation 품질이 나빠짐.
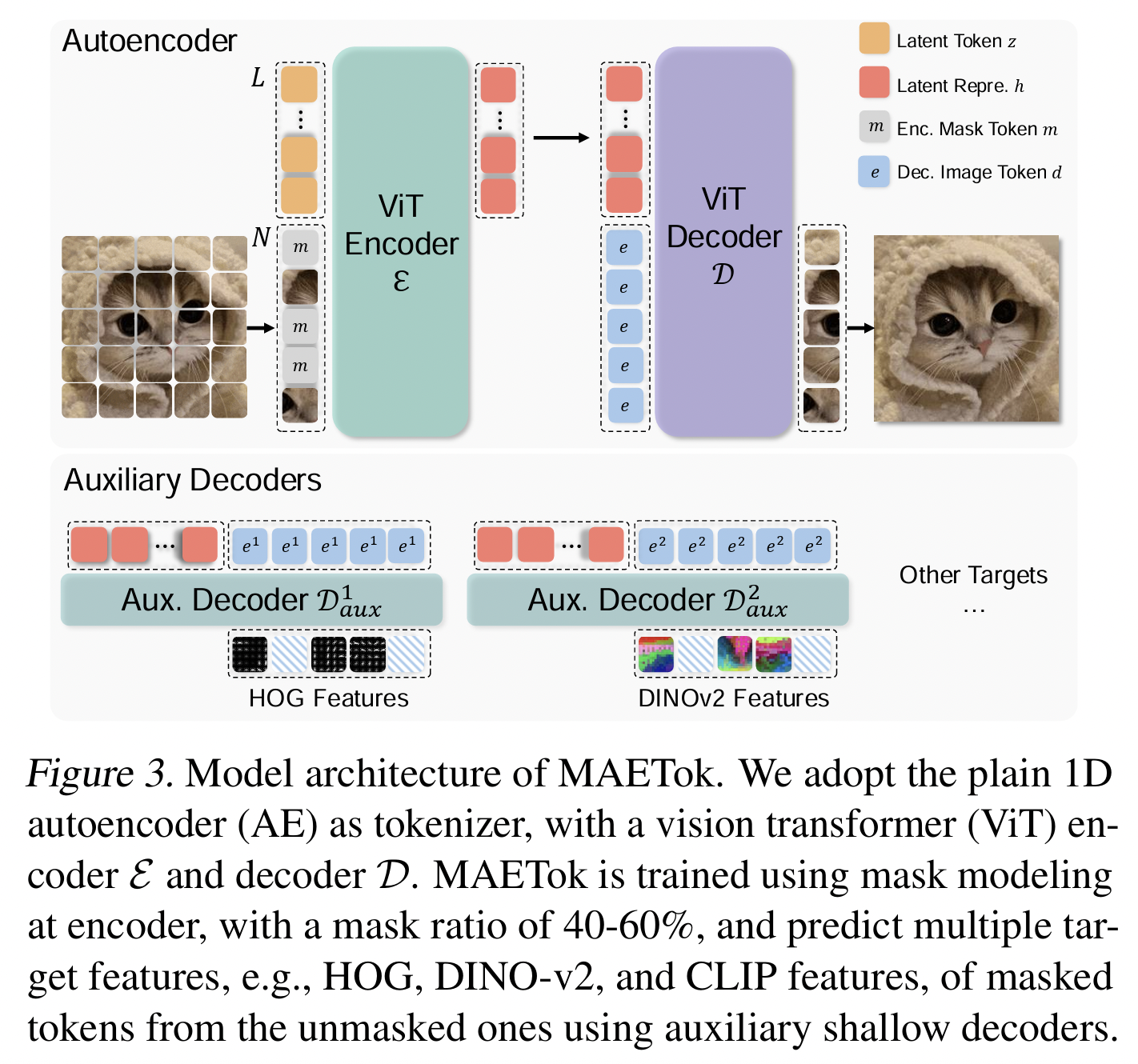
3. Method (MAETok)
Overview
- Idea: AE를 MAE 방식으로 훈련시켜 “더 구조화된 latent space”를 학습
-
Architecture
- Encoder: ViT 기반, 이미지 패치 + learnable latent tokens 입력 → latent representation \(h\) 출력.
- Decoder: Masked tokens + latent representation 입력 → 픽셀 reconstruction
- Auxiliary shallow decoders: HOG, DINOv2, CLIP 등의 feature를 예측하도록 추가 supervision .
-
Training objectives:
- \(L = L_{recon} + \lambda_1 L_{percep} + \lambda_2 L_{adv}\).
- a) pixel MSE
- b) perceptual loss
- c) adversarial loss
- Mask Modeling:
-
Encoder 입력에서 40–60% 패치 mask.
-
Encoder가 더 discriminative feature를 학습하게 유도.
-
- Pixel Decoder Fine-tuning: Encoder freeze, Decoder만 fine-tune → high fidelity reconstruction 회복.
(1) Architecture
-
Encoder:
- Vision Transformer (ViT) 기반.
- Patchify 후 일부 masking
- MaskingX patch: w/ learnable latent tokens
-
Decoder:
-
이미지 reconstruction
-
단순히 픽셀만 복원하는 게 아니라 (이 경우는 masked 된 부분만)
후술할 auxiliary objectives를 통해 feature-level 복원 (이 경우네는 모든 부분에 대해) 도 수행
-
-
Auxiliary shallow decoders:
-
Encoder latent representation으로부터 CLIP, DINOv2, HOG 등 semantic feature를 예측
-
의미:
- Pixel fidelity만 맞추는 것이 아니라
- Semantic feature도 복원하도록 유도
→ Latent space가 더 Discriminative하게 됨.
-
(2) Training Objectives
\(L = L_{recon} + \lambda_1 L_{percep} + \lambda_2 L_{adv}\).
- Reconstruction Loss
- Mask된 영역을 복원할 때 pixel 단위 MSE
- Perceptual Loss:
- DINOv2, CLIP 같은 pretrained model의 feature space에서 distance 최소화.
- 즉, “복원 이미지가 인간 지각적 의미에서도 비슷한가?”를 측정
- Adversarial Loss:
- PatchGAN 스타일 discriminator로 복원 이미지가 자연스러운지 판별.
- Auxiliary Loss:
- Shallow decoder를 통한 CLIP/DINO/HOG feature 예측 loss.
(3) Masked Modeling
MM이 latent space를 discriminative하게 하는 핵심 역할
- MAE에서 핵심: 입력 이미지를 Patch 단위로 random masking
- Encoder는 masking 상황에서 정보를 압축해야 하므로,
- “어떤 feature가 중요한지”를 더 잘 구분하도록 학습.
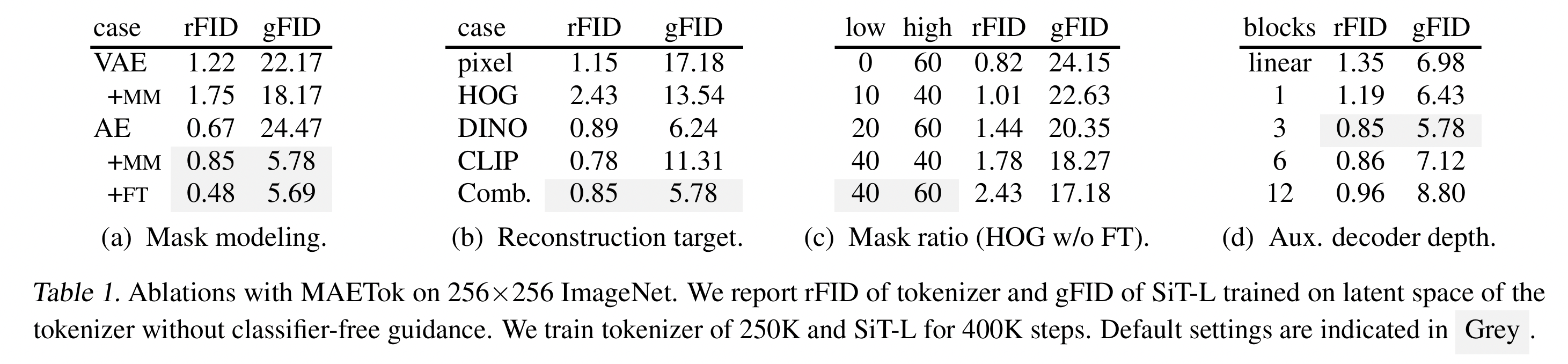
- Mask ratio 실험: 40–60%가 가장 효율적.
- 너무 낮으면: latent가 덜 구조화
- 너무 높으면: 복원 fidelity가 떨어짐
3.4 Pixel Decoder Fine-tuning
기존 MM의 문제점:
- (장) Latent space를 discriminative하게 만들지만
- (단) Pixel fidelity(세밀한 복원력)는 조금 떨어짐
해결: Pretrained encoder는 freeze, pixel decoder만 따로 fine-tuning.
- 이렇게 하면 latent space의 구조는 그대로 두고, decoder의 픽셀 복원력만 끌어올릴 수 있음.
4. Summary (Procedure)
Step 1: Tokenizer 학습 (MAE 기반 AE)
Step 1-1: Encoder + Decoder 공동 학습
- 목표: Encoder가 discriminative latent space를 만들고, Decoder가 기본적인 복원 능력을 가지도록.
- 방법: Masked Modeling(MAE-style)로 학습.
- Encoder는 unmasked patches와 latent tokens을 받아 feature를 뽑음.
- Decoder는 masked 부분을 복원.
- Loss:
- Reconstruction loss (masked 영역)
- Perceptual loss
- Adversarial loss
- Auxiliary feature loss(CLIP/DINO/HOG) 등.
- 결과: Encoder는 “semantic하게 구분 잘 되는 latent space”를 학습, Decoder는 기본 복원력 확보.
Step 1-2: Decoder Fine-tuning (Encoder freeze)
- 문제: Step 1-1만 하면 latent space는 좋지만 pixel fidelity(세밀한 복원력)이 부족.
- 해결: Encoder를 고정(freeze)하고 Decoder만 따로 학습.
- 이 단계에서는 주로 pixel reconstruction loss를 통해 디테일 회복에 집중.
-
목적: Latent space의 구조(semantic separability)는 그대로 유지하면서, Decoder의 디테일 복원 능력만 개선.
- 결과: Encoder+Decoder 쌍이 완성된 Tokenizer.
Step 2: Diffusion 학습
- Encoder: 이미지 → latent tokens
- Diffusion: latent tokens 공간에서 학습/샘플링
- Decoder: latent tokens → 최종 이미지
5. Experiments