
VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks
https://arxiv.org/pdf/2410.05160
0. Abstract
Embedding models: Enabling various downstream tasks
- e.g., semantic similarity, information retrieval, and clustering.
Universal text embedding models
-
Generalize across tasks (e.g., MTEB)
-
Nonetheless, development is relatively slow despite its importance and practicality
Proposal
-
Explore the potential of building universal multimodal embeddings
- Capable of handling a wide range of downstream tasks
-
Two Contributions
-
(1) MMEB (Massive Multimodal Embedding Benchmark)
-
(2) VLM2Vec (Vision-Language Model → Vector)
-
(1) MMEB (Massive Multimodal Embedding Benchmark)
- Covers 4 meta-tasks & 36 datasets
- 4 meta-tasks
- a) Classification
- b) Visual question answering (VQA)
- c) Multimodal retrieval
- d) Visual grounding
- 36 datasets (covering both ID & OOD tasks)
- a) 20 training datasets
- b) 16 evaluation datasets
(2) VLM2Vec (Vision-Language Model → Vector)
- Contrastive training (CL) framework
- Converts any VLM into an embedding model via contrastive training on MMEB
- Comparison with CLIP/BLIP
- CLIP/BLIP:
- Encodes text or images independently
- W/o any task instruction
- VLM2Vec:
- Process any combination of images and text to generate a fixed-dimensional vector
- Based on the given task instructions
- CLIP/BLIP:
Experimental results
- Build a series of VLM2Vec models on SoTA VLMs
- e.g., Phi-3.5-V, LLaVA-1.6
- Evaluate them on MMEB’s evaluation split
- With LoRA tuning, VLM2Vec achieve an improvement of 10% to 20% over existing multimodal embedding models
1. Introduction
(1) Recent shift in research
Developing “universal embeddings” that can generalize across a “wide range of tasks”
- Example: MTEB (Massive Text Embedding Benchmark):
- To comprehensively assess text embeddings across tasks
- e.g., Classification and clustering
- Standard for evaluating universal text embeddings
- To comprehensively assess text embeddings across tasks
Progress in multimodal embeddings??
\(\rightarrow\) Lack of both benchmarks and methodologies in the multimodal embedding domain!
(2) Limitation of multimodal embeddings
-
(1) Existing studies typically evaluate visual embeddings on isolated tasks
- e.g., ImageNet classification, MSCOCO/Flickr retrieval
-
(2) Most existing models (e.g., CLIP, BLIP, SigLIP) either
-
a) Process text and images separately
-
b) Perform shallow fusion of visual and textual information
\(\rightarrow\) Limiting their ability to fully capture the relationships between text and image modalities!
-
Exhibit limited reasoning and generalization capabilities
- Particularly in zero-shot scenarios for complex reasoning tasks
-
(3) Proposal
Attempt to build an universal multimodal embedding framework!
a) MMEB (Massive Multimodal Embedding Benchmark)
- Novel benchmark consiting of “36 datasets” spanning “four meta-task” categories
- Classification, visual question answering, retrieval, and visual grounding
- Comprehensive framework for training/evaluating embedding models
- Across various combinations of text and image modalities
- All tasks are reformulated as “ranking tasks”
- Model follows instructions, processes a query, and selects the correct target from a set of candidates.
- Query & Target: Can be an image, text, or a combination of both.
- Divided into ..
- a) 20 in-distribution datasets (used for training)
- b) 16 out-of-distribution datasets (used for evaulation)
b) VLM2Vec
-
Adopt the pre-trained VLMs (e.g., Phi-3.5-V, LLava-1.6) as the backbone
-
vs. multimodal embedding models
- e.g., UniIR (Wei et al., 2023) and MagicLens (Zhang et al., 2024)
- Rely on late fusion of CLIP (Radford et al., 2021) features
- VLM2Vec: Leverages the deep integration of vision and language features within a transformer architecture
- e.g., UniIR (Wei et al., 2023) and MagicLens (Zhang et al., 2024)
-
Advantanges:
-
(1) Trained on massive multimodal datasets & Handle any combination of images and text
-
(2) Vision and language features are deeply fused in the transformer model
\(\rightarrow\) Improving the model’s ability to capture cross-modal relationships
-
(3) Well-suited for generalizing across diverse tasks
- Particularly those requiring instruction-following capabilities
-
Summary
- Extensive contrastive training
- Handle any combination of images & text
- Evaluate VLM2Vec against a wide array of multimodal embedding models
- Compared to the best baseline model **without fine-tuning **…
- 18.2 point improvement (from 44.7 to 62.9) across all 36 MMEB datasets
- 15.4-point increase (from 41.7 to 57.1) on 16 OOD datasets (for zero-shot evaluation)
- Achieve competitive zero-shot T2I (Text-to-Image) and I2T (Image-to-Text) performance on Flickr30K
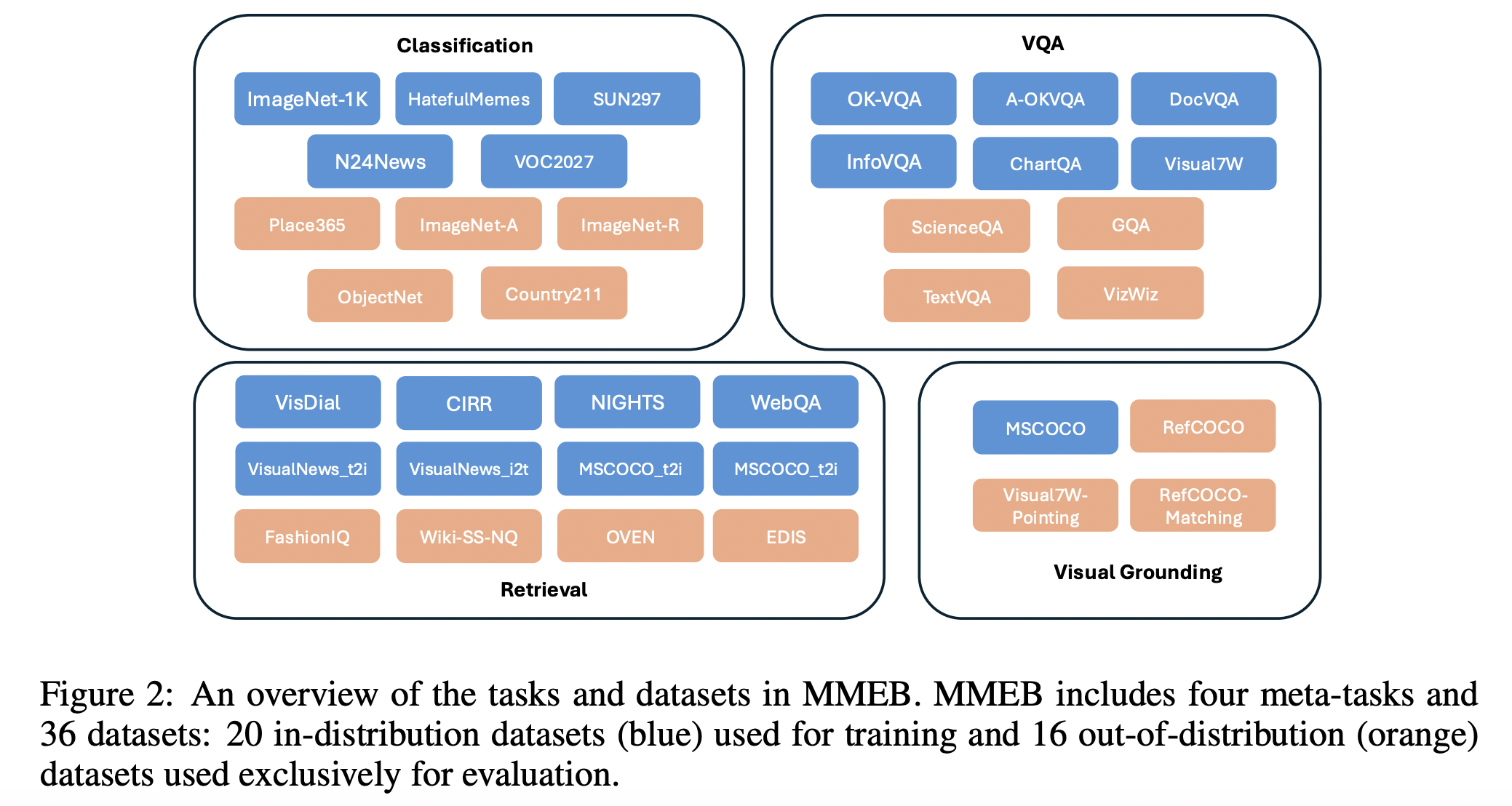
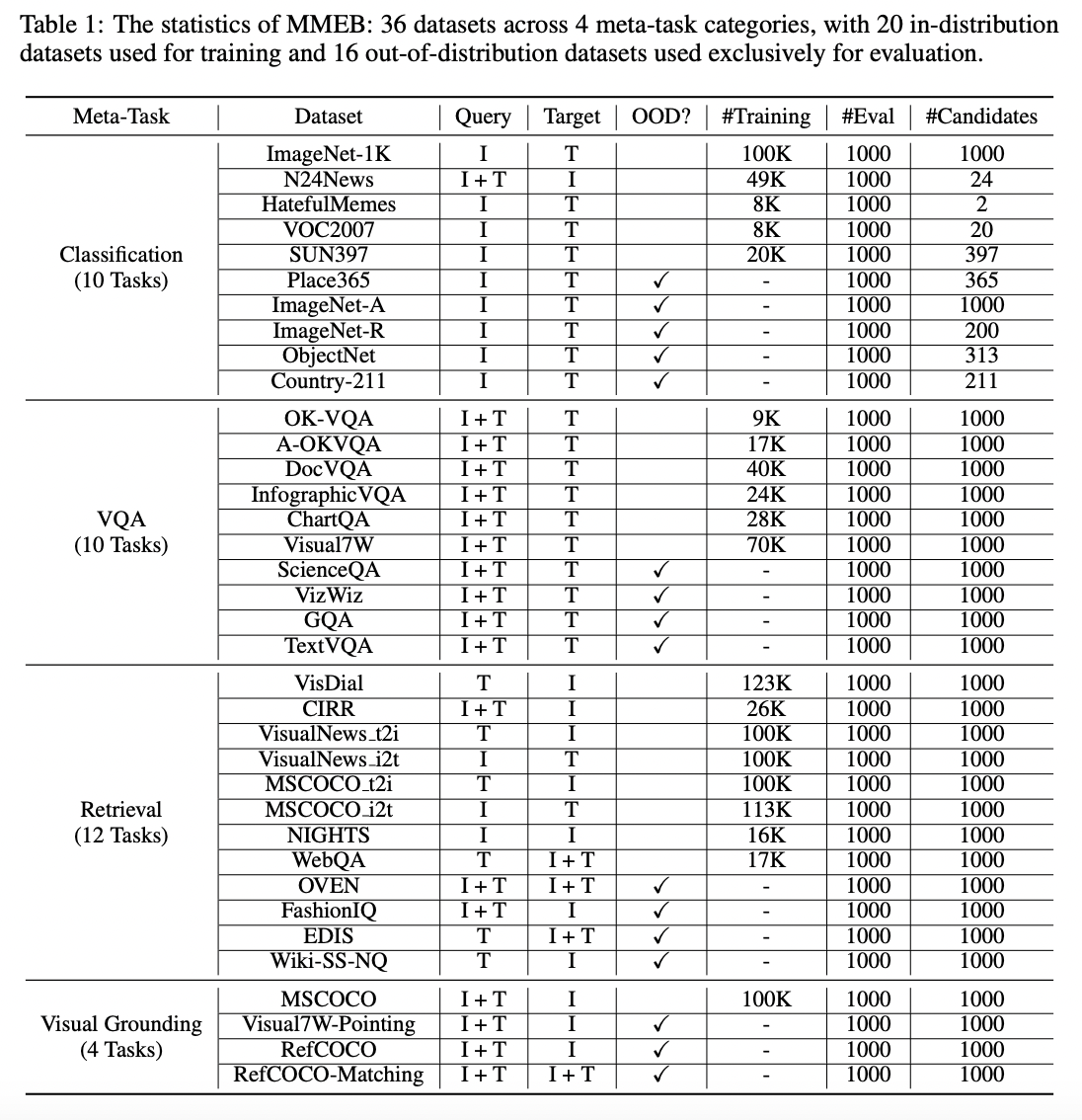
2. MMEB: A Benchmark for Multimodal Embeddings
(1) Dataset Overview
Comprehensive benchmark designed to evaluate “multimodal embeddings” across a diverse set of tasks
-
a) Consists of 36 datasets
- 20 in-distribution datasets \(\rightarrow\) for training
- 16 out-of-distribution datasets \(\rightarrow\) for evaluation
-
b) Organized into 4 meta-tasks
- Classification
- Visual question answering
- Retrieval
- Visual grounding
-
c) Each task is reformulated as a “ranking problem”
- Model is provided with an instruction & query (which may consist of text, images, or both)
- Tasked with selecting the correct answer “from a set of candidates”
Embedding models: Compress the …
- Query side into a “vector”
- Target candidates into a “set of vectors”
Candidate with the highest dot-product
\(\rightarrow\) Selected as the prediction for evaluation! (Metric: Precision@1 )
Number of target candidates
- Higher count:
- Increase evaluation costs
- Hinder rapid model iteration
- Lower count:
- Make the benchmark too simple and prone to saturation
\(\rightarrow\) Choose 1,000 candidates!
Wide range of tasks from various domains
(e.g., common, news, Wikipedia, web, and fashion)
- Incorporates diverse combinations of modalities for both queries and targets
- e.g., text, images, and text-image pairs.
- Designed to follow different types of instructions
- Object recognition (e.g., “Identify the object shown in the image.”)
- Retrieval (e.g., “Find an image that matches the given caption.”)
- Visual grounding (e.g., “Select the portion of the image that answers the question.”)
(2) Meta-Task and Dataset Design
Four primary meta-task categories
a) Classification
- [Query] Instruction, Image
- [Target] Class
- Number of candidates equals the number of classes
b) Visual Question Answering (VQA)
- [Query] Instruction, Image, Text (as the question)
- [Target] Answer
- Each query has 1 ground truth and 999 distractors as candidates
c) Information Retrieval
- [Query] Combination of Text, Image, and Instructions
- [Target] Combination of Text, Image, and Instructions
- Each query has 1 ground truth and 999 distractors as candidates
d) Visual Grounding
(Adapted from object detection tasks)
- [Query] Instruction + Full image
- Instruction guides the model to focus on a specific object within the image
- [Target] Cropped regions (bounding boxes) of the image
- Including both the object of interest and distractor regions
- Each query has 1 ground truth and 999 distractors as candidates
3. VLM2Vec: Transforming LVMs to Embeddings
(1) Contrastive Learning
VLM2Vec = CL framework designed to convert any SoTA VLM into an embedding model
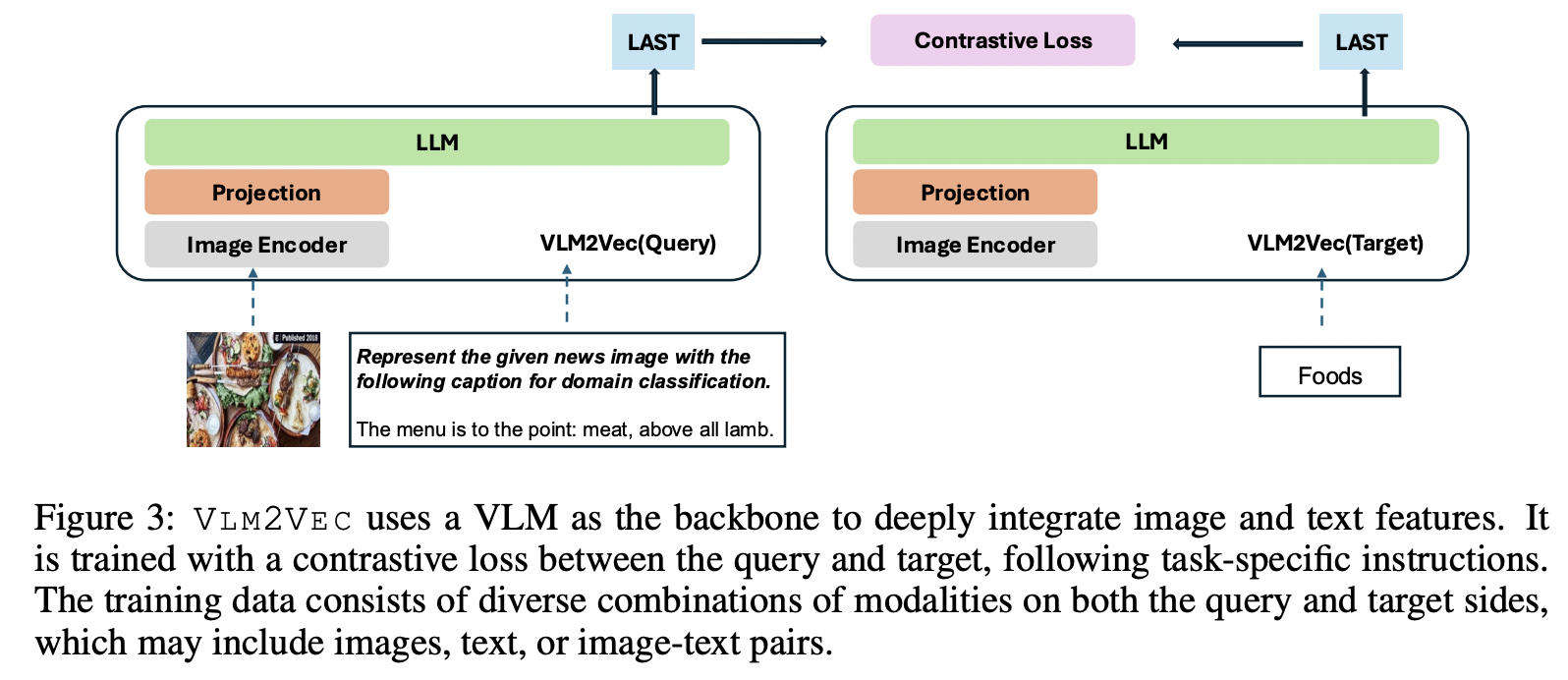
(1) Query-target pair: \((q,t^{+})\)
- Both could be either image / text / image + text
- \(q : (q_t, q_i)\) .
- \(t^{+} : (t_t^{+}, t_i^{+})\) .
(2) Query with instruction
-
Apply the instruction to the original query \(q\) to generate a new one \(q_{\text{inst}}\)
- \(q_{\text{inst}} = [\text{IMAGE\_TOKEN}] \ \text{Instruct:} \ \{ \text{task definition} \} \backslash n \ \text{Query:} \ \{ q \}\).
{task definition}: Placeholder for a one-sentence description of the embedding task
- To enhance the embedding model’s generalizability by better understanding instructions
(3) Input & Output of pretrained VLM
- [Input] Query & Target
- [Output] Query & Target embeddings \((\mathbf{h}_{q_{\text{inst}}}, \mathbf{h}_{t^+})\)
- By taking the last layer vector representation of the last token
(4) Loss function
- Standard InfoNCE loss \(\mathcal{L}\)
- Over the in-batch negatives and hard negatives
- \(\min \ \mathcal{L} = - \log \frac{\phi(\mathbf{h}_{q_{\text{inst}}}, \mathbf{h}_{t^+})} {\phi(\mathbf{h}_{q_{\text{inst}}}, \mathbf{h}_{t^+}) + \sum_{t^- \in \mathcal{N}} \phi(\mathbf{h}_{q_{\text{inst}}}, \mathbf{h}_{t^-})}\).
- \(\mathcal{N}\): Set of all negatives
- \(\phi(\mathbf{h}_q, \mathbf{h}_t)\) : Function that computes the matching score between query \(q\) and target \(t\).
- \(\phi(\mathbf{h}_q, \mathbf{h}_t) = \exp \left( \frac{1}{\tau} \cos(\mathbf{h}_q, \mathbf{h}_t) \right)\).
- Adopt the temperature-scaled cosine similarity function .
(2) Increasing Batch Size Through GradCache
Hard negatives are often difficult or ambiguous to collect for most multimodal datasets!
\(\therefore\) Using LARGER batch sizes becomes crucial!
\(\rightarrow\) Increases the number of in-batch random negatives!
(1) Bottleneck: “GPU memory”
-
Limits us from increasing the batch size :(
-
VLM2Vec: Apply GradCache!
- Gradient caching technique
- Decouples backpropagation btw contrastive loss & encoder
- Removing encoder backward pass data dependency along the batch dimension
(2) GradCache
- Divide large batch of queries \(\mathcal{Q}\) into a set of sub-batches
- \(\mathcal{Q} = \{\hat{Q}_1, \hat{Q}_2, \ldots \}\).
- Two major steps
- Step 1) Representation Gradient Computation & Caching
- Step 2) Sub-batch Gradient Accumulation
- Step 1) Gradient tensors within each subbatch are calculated & stored
- \(\mathbf{u}_i = \frac{\partial \mathcal{L}}{\partial f(q_i)}\).
- Step 2) Gradients are accumulated for encoder parameters across all sub-batches
- \(\frac{\partial \mathcal{L}}{\partial \Theta} = \sum_{\hat{Q}_j \in \mathcal{Q}} \sum_{q_i \in \hat{Q}_j} \frac{\partial \mathcal{L}}{\partial f(q_i)} \frac{\partial f(q_i)}{\partial \Theta} = \sum_{\hat{Q}_j \in \mathcal{Q}} \sum_{q_i \in \hat{Q}_j} \mathbf{u}_i \frac{\partial f(q_i)}{\partial \Theta}\).
4. Experiments
(1) Backbone VLMs
- Phi-3.5-V
- LLaVA-1.6
(2) Training
- Full FT
- PEFT (LoRA)
(3) Hyperparameters
- Temperature \(\tau\) = 0.02
- Batch size = 1024
- Maximum text length = 256 tokens
- Training steps = 2K
(4) Model configuration
- Rank of LoRA = 8
- VLM2Vec with Phi-3.5-V: Number of sub-image crops = 4
- VLM2Vec with LLaVA-1.6: Resize the input images to a uniform resolution, employing two setups
- (1) High-resolution configuration of 1344 × 1344
- (2) Low-resolution configuration of 336 × 336
(5) 20 Training datasets
-
If a dataset contains more than 50K samples
\(\rightarrow\) Randomly select 50K for consistency
\(\rightarrow\) Resulting in a total training set of 662K data points
(6) GradCache
-
Set a sub-batch size of 4 to enable full model tuning
\(\rightarrow\) Total batch size accumulated to 1,024
Resources
- 8 H100 GPUs
Metric: Precision@1
- Measures the ratio of positive candidates being ranked in the top place for all queries.