
1. Pretraining Objectives
- ITC (Image-Text Contrastive)
- ITM (Image-Text Matching)
- MLM/MIM/MRM (Masked Language/Image/Region Modeling)
- Prefix-LM
(1) ITC (Image-Text Contrastive)
- 정의: InfoNCE/CLIP 식 Contrastive Learning (CL)
- 수식 (InfoNCE)
- 배치 크기 \(N\), 정규화된 임베딩 \(v_i, t_j\), 온도 \(\tau\)
- \(\mathcal{L}_{i\to t} =-\frac{1}{N}\sum_{i=1}^N \log\frac{\exp(\mathrm{sim}(v_i,t_i)/\tau)} {\sum_{j=1}^N \exp(\mathrm{sim}(v_i,t_j)/\tau)}\).
- \[\mathcal{L}_{t\to i} =-\frac{1}{N}\sum_{i=1}^N \log\frac{\exp(\mathrm{sim}(t_i,v_i)/\tau)} {\sum_{j=1}^N \exp(\mathrm{sim}(t_i,v_j)/\tau)}\]
- \(\mathcal{L}_{\text{ITC}}=\tfrac{1}{2}(\mathcal{L}{i\to t}+\mathcal{L}_{t\to i})\).
(2) ITM (Image-Text Matching)
- 정의: Image–Text 쌍이 매칭/불매칭인지 binary CLS
- 종종 ITC로 찾은 hard negative를 섞어 학습
- 수식 (Logistic): Multimodal encoder의 [CLS] 벡터 \(z\)에 대해
- (참고: \(z\)에는 Image-Text pair의 정보가 모두 들어가 있음)
- \(p(y{=}1\mid z)=\sigma(w^\top z+b)\).
- \(\mathcal{L}_{\text{ITM}}=-\frac{1}{N}\sum_i\big[y_i\log p_i+(1-y_i)\log(1-p_i)\big]\).
- 주로 ITC + ITM 섞어서 함께 사용
(3) MLM/MIM/MRM (Masked Language/Image/Region Modeling)
- MRM 정의: 감지된 객체 RoI의 라벨/속성/특징 회귀를 맞춤
- 대표: LXMERT(MLM + 객체라벨/속성/특징 + ITM + VQA 프리텍스트).
MRM details
(1) 개념
- 이미지 안의 영역(region/patch/RoI) 을 가림
- 모델이 가려진 시각 정보를 맞히도록 학습
- MRM vs. MIM
- MRM: Pretrained detector (e.g., Faster R-CNN 등) 가 뽑은 RoI(region of interest, 객체 영역) 특징을 사용
- MIM: 주로 random masking
- 텍스트와 시각 특징의 정밀 정렬(alignment) 을 강화해 VQA·캡셔닝·검색에 도움.
(2) Masked Region Classification (MRC)
- Detector (예: Faster R-CNN)로 얻은 객체 분류 분포를 정답으로 사용
- Notation
- \(q\)는 Detector의 soft label (= Detector의 pred prob)
- \(p_\theta\)는 모델 예측
- Hard label이면 Cross-Entropy
- \(\mathcal{L}_{\text{MRC-CE}}=-\sum_k y_k \log p_\theta(k)\).
- Soft label이면 KL-divergence
- \(\mathcal{L}_{\text{MRC-KL}}=\sum_k q_k \log\frac{q_k}{p_\theta(k)}\).
(3) Masked Region Feature Regression (MRFR)
- “Data space”가 아닌 “Feature space”에서 맞춤
- \(\mathcal{L}_{\text{MRFR}}=\mid \mid f_\theta(\text{masked region}) - \hat{v}\mid \mid _2^2\).
- \(\hat{v}는\) Detector/Vision backbone이 제공한 타깃 특징.
(4) Prefix-LM
- 정의: 이미지(또는 비디오) 조건 하에 자연어 생성
- 수식: \(\mathcal{L}_\text{NLL}=-\sum_t\log p_\theta(w_t\mid w_{<t}, \text{Image/Video})\).
Prefix-LM details
-
Procedures
-
Step 1) Image를 vision token(예: 패치/ROI 임베딩)으로 바꾸고
-
Step 2) 이를 (Text) Decoder 앞에 접두(prefix) 로 붙여 문장을 생성.
-
- Conditional LM:
- \(p_\theta(y\mid x)\) 을 (Teacher forcing 방법으로) 학습
- 수식:
- Caption: \(y=(w_1,\dots,w_T)\)
- Image input: \(x\)
- Loss function: \(\mathcal{L}_{\text{NLL}}=-\sum_{t=1}^T \log p_\theta(w_t \mid w_{<t},\; \text{prefix}(x))\).
- Training & Inference
- Training: Teacher Forcing)
- Inference: Greedy/Beam/샘플링
-
Examples
-
입력 이미지: 강아지가 잔디에서 뛰는 사진
-
비전 인코더 → 토큰 \(v_{1:M}\) 생성 → 디코더 입력: \([v_{1:M};\ \text{BOS}]\)
-
모델이 순차적으로 “A brown dog is running on the grass.”를 생성
-
2. Downstream Tasks - Image
(1) Image \(\leftrightarrow\) Text Retrieval
- 입·출력: 질의 (Text→Image or Image→Text)
- 지표: Recall@K, mAP.
- 데이터셋: COCO, Flickr30k (Karpathy split).
- 모델 팁:
- Dual Encoder (+ITC)로 빠른 검색
- Reranking 시 cross encoder (+ITM) 병행.
a) Recall@K (R@K)
- Step 1) Prediction (multiple):
- Query에 대해 \(K\) 번 predict
- \(K\)개의 prediction에 대해 ranking
- Step 2) GT vs. \(K\) Preds:
- \(K\) Preds 안에 정답이 하나라도 있으면 성공 (hit)
- Step 3) \(\mathrm{R@K}\) 계산:
- 전체 질의 수 \(Q\) 개 (i.e., \(Q\) 개의 query) 중, 성공한 비율
- \(\mathrm{R@K}=\frac{1}{Q}\sum_{q=1}^{Q}\mathbf{1}\{\text{Top-}K \text{ 내에 정답 존재}\}\).
-
보통 K=1, 5, 10을 보고 텍스트→이미지(T2I), 이미지→텍스트(I2T)를 각각 계산
- 사용 이유
- “상위 몇 개 안에 정답이 뜨는가”를 바로 보여주므로 사용자가 원하는 검색 품질 체감을 잘 반영
- 단, 정답이 여러 개일 때 몇 개를 가져왔는지(재현율의 양적 측면)와 정답의 세밀한 순서는 반영이 약함
Examples (T2I)
- 질의 3개(캡션 3개) → 각 질의의 GT image는 하나.
- Model ranking에서 정답 순위가 각각 2위, 7위, 12위
- R@1 = 0/3 = 0%
- R@5 = 1/3 ≈ 33.3% (2위만 성공)
- R@10 = 2/3 ≈ 66.7% (2위, 7위 성공)
b) mAP (mean Average Precision)
- 상황: 정답이 “1개”가 아니라 “여러 개”일 수 있음!
- mAP: “순위-민감” 지표
- 정답이 여러 개일 수 있는 Ranking에서, 정답을 어느 위치들에 배치했는지까지 반영
- AP \(\rightarrow\) mAP
- 한 질의 \(q\)에 대한 AP(평균정밀도) 를 계산
- 모든 질의에 대해 평균한 값이 mAP
Procedure
- Notation
- (질문 \(q\)에 대한) GT 정답의 개수: \(M_q\) 개
- (Model의) Multiple pred 개수: \(N\) 개
- (Sorted된) \(N\)개의 multiple prediction에 대해 Ranking을 위에서부터 내려오며,
- 정답을 만나는 지점에서의 정밀도(Precision@k) 들을 정답 개수 \(M_q\) 로 평균
- \(k\): Predefined된 값이 아니라, 내 예측이 정답을 다 만날때까지 내려오게 되면서 정해짐.
\(\mathrm{AP}(q)=\frac{1}{M_q}\sum_{k=1}^{N}\mathrm{Prec@}k \cdot \mathrm{rel}_k\).
-
\(\mathrm{rel}_k\in\{0,1\}\): 순위 k가 정답이면 1.
- \[\mathrm{Prec@}k=\frac{\text{상위 }k\text{ 내 정답 수}}{k}\]
mAP vs. R@K
- 모든 정답의 위치를 고려하므로, 정답을 위쪽에 많이 몰아놓을수록 AP가 커짐
- R@K보다 까다로운 지표라 모델 간 순위 차이를 더 세밀하게 드러냄
Example 1: T2I
- GTs: \(\{i_2,i_4\}\)
- Preds: \([i_3,\ i_2,\ i_4,\ i_1]\)
- 정답을 만난 순위와 Precision:
- \(k=2\): 정답( \(i_2\) ) → Prec@2 = 1/2
- \(k=3\): 정답( \(i_4\) ) → Prec@3 = 2/3
- \[\mathrm{AP}=\frac{1}{2}\Big(\frac{1}{2}+\frac{2}{3}\Big)=\frac{7}{12}\approx 0.583\]
- (1개의 문제(q)이므로) AP = mAP
Example 2: I2T
- 랭킹에서 정답 캡션이 나온 순위: 1, 3, 6
- Prec@1 = 1/1
- Prec@3 = 2/3
- Prec@6 = 3/6
- \[\mathrm{AP}=\frac{1}{3}\Big(1+\frac{2}{3}+\frac{1}{2}\Big)=\frac{13}{18}\approx 0.722\]
Comparison
| 항목 | Recall@K | mAP |
|---|---|---|
| 초점 | Top-K 안에 정답 존재 여부 | 모든 정답의 순위와 정밀도 |
| 장점 | 해석 직관적, 사용자 체감에 근접 | 순위 민감, 모델 차이 세밀히 드러남 |
| 단점 | 정답이 많아도 1개만 맞추면 성공 | 계산·해석이 상대적으로 복잡 |
| 보고 방식 | K=1/5/10 | 한 값 (mAP) |
COCO/Flickr30k 관행
- I2T: 한 이미지에 5개 GT 캡션 (1 image: 5 GTs)
- R@K: “Top-K 중 하나라도 GT 캡션이면 성공”
- mAP: 세 캡션 모두의 위치를 반영
- T2I: 한 캡션에 1개 GT 이미지 (1 text: 1 GTs)
- 구현 시 query 별로 계산한 후 평균 (macro)하는 게 표준


(2) Image Captioning
- 입·출력: Image→ Text
- 지표: CIDEr, SPICE, BLEU, METEOR, ROUGE-L.
- 데이터셋: MS-COCO Captions
Image Captioning vs. I2T
- 공통점:
- 입력: 하나의 Image
- 차이점:
- Image Captioning: 설명 문장(자연어 시퀀스) “생성”
- I2T: (여러 후보 텍스트 중) 해당 이미지를 가장 잘 설명하는 특정 문장 “선택”
(3) VQA (Visual Question Answering)
- 입·출력: (Image, Text(Q)) → A
- 지표: Accuracy
- 데이터셋: VQAv2, GQA,
- 특정 지식 필요 OK-VQA / A-OKVQA.
객관식 (MC) vs. 주관식 (Open-ended)
(1) Open-ended VQA (주관식)
-
Output: 텍스트(단어/짧은 구절)
-
Datasets: VQA v1/v2, GQA
-
Metric
-
VQA v1/v2: 한 질문에 대해 \(N\)명의 annotator 답변을 수집
→ 모델 답과 몇 명이 일치하는지에 따라 점수 산정
\(\text{Acc(ans)} = \min\left(\frac{\#\text{humans agree}}{3}, 1\right)\).
-
왜 \(3\)? 적어도 3명의 답과 같으면 정답으로 간주
-
-
Ex) 10 (\(N\))명 중 5명이 “dog”이라 답
→ 모델이 “dog” 출력하면 5/3=1.67 → min(1.67,1)=1.0 점
(2) Multiple-choice VQA (객관식)
- Output: (여러 후보 답변 중) 답변 하나 선택 (classification 문제처럼)
- Datasets:
- Visual7W: 4개 보기 중 정답 1개
- VQA-abstract 버전 일부
- Metric: Accuracy
(4) Referring Expression & Phrase Grounding
- 입·출력: Text로 지칭된 객체 위치 (Box/Mask)
- 지표: Acc@IoU(박스), mIoU(분할).
- 데이터셋:
- RefCOCO / RefCOCO+ / RefCOCOg
- Flickr30k Entities. (문구↔영역 정합)
Details
(1) 개념
- (공통) Text → Image 내 객체 위치를 찾아내는 task
- Referring Expression: Text에서 특정 객체를 지칭하는 표현 (예: “the man in a red shirt”).
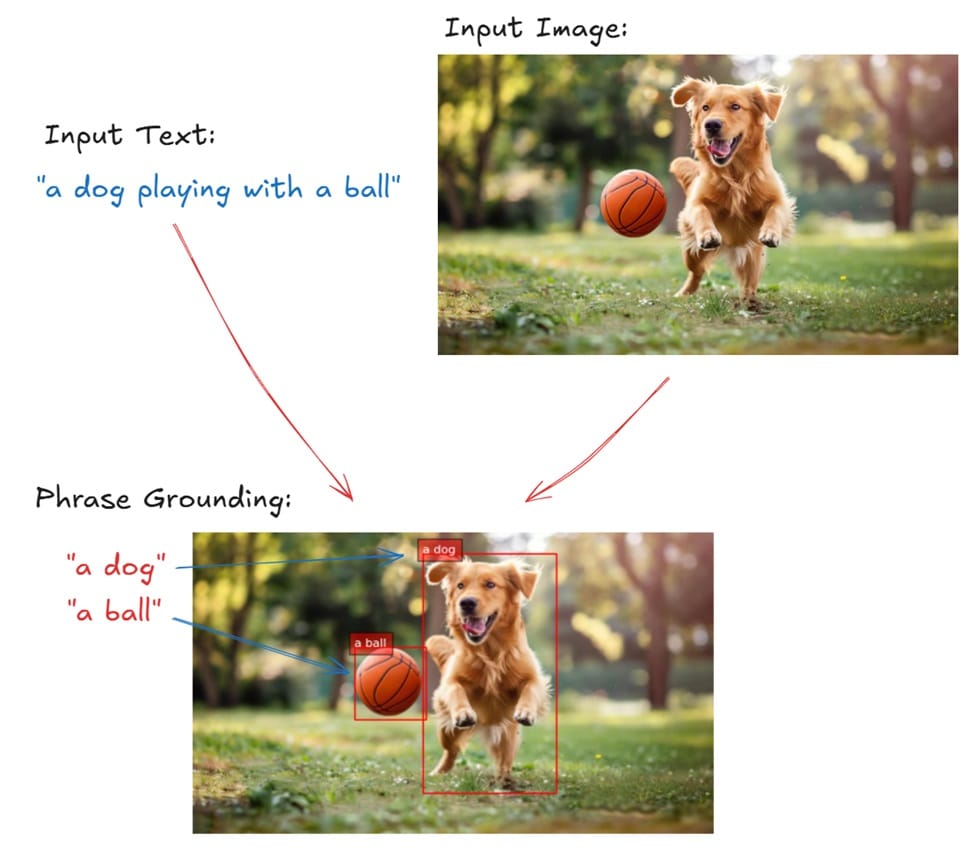
- Phrase Grounding: Text에서 언급된 특정 대상을 이미지 내 위치 (Box/Mask) 와 매칭
(2) Input & Output
- 입력(Input): Image + Text
- 출력(Output): Text가 가리키는 객체의 Image 내의 위치
- Bounding Box (좌표값)
- Segmentation Mask (픽셀 단위 영역)
(3) Metric
- Acc@IoU (Bounding Box)
- IoU (Pred box, GT box)가 일정 threshold (e.g., 0.5) 이상이면 성공
- Accuracy로 측정
- mIoU (Segmentation)
- IoU (Pred mask, GT mask): pixel level
(4) Dataset
- RefCOCO / RefCOCO+ / RefCOCOg
- MS-COCO 이미지 기반, 사람들에게 자연어로 특정 객체를 설명하게 하여 구축.
- RefCOCO: 위치 단서 포함 (“man on the left”).
- RefCOCO+: 위치 단서 제거, 주로 appearance만 (“man in red shirt”).
- RefCOCOg: 더 긴 문장, 복잡한 서술.
- Flickr30k Entities
- 각 문장에서 명사구(entity phrase)와 이미지 영역(박스)을 연결.
- 예: 문장 “A dog chasing a ball” → phrases “A dog”, “a ball” 각각 박스 매칭.
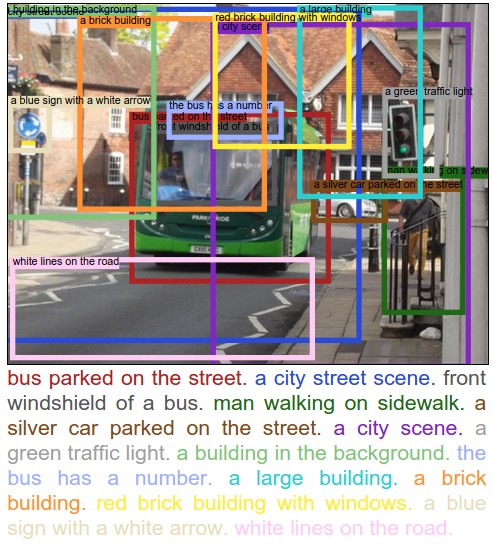
(5) Dense Captioning (영역 단위 설명)
- Input & Output
- Input: Image
- Output: 다수의 box + sentence.
- Dataset: DenseCap (Visual Genome).
- 지표: 지역 캡션 mAP 계열 + 언어 지표
(6) Visual Entailment (SNLI-VE)
- 입·출력: (이미지=Premise, 문장=Hypothesis) → Entail / Neutral / Contradict 3-분류.
- 데이터셋: SNLI-VE.
Details
(1) 개념
- 입력: 이미지(Premise) + 문장(Hypothesis)
- 출력: 3-class CLS
- Entail(이미지가 문장을 뒷받침)
- Neutral(판단 불가)
- Contradict(이미지가 문장을 반박)
- 핵심 목표: Text의 자연어추론(NLI) 개념을 Vision-Language의 Multimodal로 확장.
(2) Dataset: SNLI-VE
-
SNLI: Flickr30k 이미지 캡션을 전제 (premise)로 만든 “Text”NLI data
-
SNLI-VE: 텍스트 전제(premise caption) 를 이미지 전제 (premise image)로 대체
\(\rightarrow\) (Image-premise) 쌍에 대해 3-class CLS를 수행하도록 구성.
-
주의점: 언어 편향(hypothesis-only bias) 이 존재할 수 있어, 순수 텍스트만으로도 어느 정도 맞출 수 있는 경우가 보고됨
→ 비전 신호의 기여를 분리 검증하는 설계가 중요.
(3) Metrics: Accuracy (3-클래스).

(7) VCR (Visual Commonsense Reasoning)
- 입·출력: Image 기반 (객관식) 답 + 근거 선택.
- 지표: Answer/ Rationale / Joint 정확도.
- 데이터셋: VCR
Details
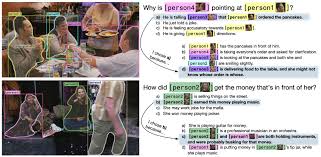
(1) 개념
- 입력: Image + Question (객체 태그 포함: 예 [person1], [book])
- 출력:
- (1) Answer 객관식 (4지선다)
- (2) Rationale 객관식 (4지선다)
- 목표:
- (1) 단순 인식(무엇이 있는가)을 넘어서
- (2) 상황 추론·상식(reasoning) 과 설명 가능한 정답 근거 선택까지 요구.
(2) 평가 지표
- Answer Acc.: 정답 선택 정확도(Q→A)
- Rationale Acc.: 정답을 가정한 상태에서 근거 선택 정확도(QA→R)
- Joint Acc.: 정답과 근거를 모두 맞춘 비율(실전 평가는 보통 여기에 주안점)
(3) 예시
-
이미지: [person1]이 책을 펼치고 [person2]에게 보여주는 장면
-
질문(Q): “Why is [person1] showing the book to [person2]?”
-
답변 후보(A):
- Because [person2] asked for help with reading.
- Because they are hiding the book.
- Because [person1] is angry.
- Because the book belongs to [person2].
-
근거 후보(R):
a) [person2] is pointing at the page.
b) The book is closed.
c) [person1] looks away.
d) There is no book.
-
올바른 선택 예: A=1, R=a → Joint 성공
(8) VisDial (시각 대화)
- 입·출력: (이미지, 대화 이력) → 다음 응답.
- 지표: NDCG, MRR 등(랭킹 기반).
- 데이터셋: Visual Dialog.
(9) OCR 계열 멀티모달
- 하위작업:
- TextVQA/ST-VQA(장면문자 질의)
- DocVQA(문서)
- ChartQA(차트 해석).
- 지표: 정확도/EM/F1.
3. Downstream Tasks - Video
(1) Video ↔ Text retrieval
- 지표: Recall@K.
- 데이터셋: MSR-VTT, MSVD(텍스트 다양, 규모 작음).
(2) Video Captioning
- 지표: CIDEr, BLEU 등(문장 지표).
- 데이터셋: MSVD, MSR-VTT. (프레임 샘플링/시간적 집계가 핵심)
(3) Video QA
- 입·출력: (비디오, 질문) → 답.
- 데이터셋: TGIF-QA(프레임/동작/반복), ActivityNet-QA(오픈도메인), NExT-QA(원인·결과 추론).
(4) Temporal Grounding / Moment Retrieval
- 정의: 문장이 가리키는 타임 스팬(start–end) 찾기.
- 지표: R@1/5@IoU(0.5 등), mAP.
- 데이터셋: DiDeMo, Charades-STA.