
Beyond Numbers: A Survey of Time Series Analysis in the Era of Multimodal LLMs
- 인용 수 (2025-08-27): 2회
- https://www.techrxiv.org/users/906388/articles/1281390-beyond-numbers-a-survey-of-time-series-analysis-in-the-era-of-multimodal-llms
- https://mllm-ts.github.io/
1. Abstract
- Multimodal LLMs (MLLMs)의 발전
- Survey: TS를 다양한 modality (text, image, audio, graph, table 등)로 표현
- 이에 적합한 MLLM 구조들을 체계적으로 정리함.
- Data 측면: 시계열 modality 6가지 분류 제시.
- Model 측면: modality별 대표 MLLM 구조와 적용 사례 제시.
- 향후 연구 방향: video 기반 시계열, reasoning, agents, interpretability, hallucination 등 .
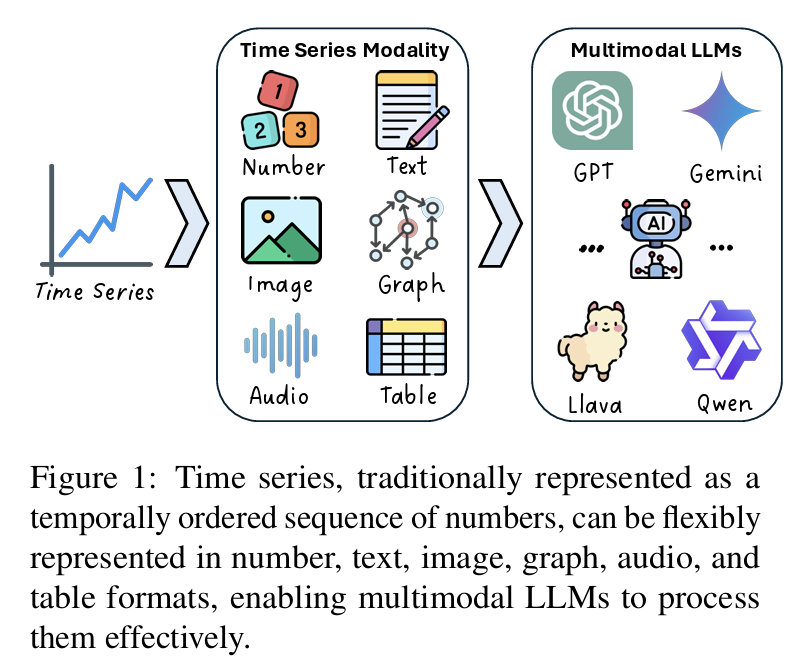
2. Introduction
(1) Motivation & Proposal
-
TS는 단순 숫자 배열을 넘어서 다양한 modality로 표현 가능 → MLLM과 궁합이 좋음.
-
본 논문은 시계열을 6가지 modality로 분류
& 각 modality에 적합한 MLLM 구조/적용 예를 총정리
-
정리 프레임워크:
- 데이터 기반 분류: Number, Text, Image, Graph, Audio, Table
- 모델 기반 분류: 각 modality에 맞는 MLLM 구조 (encoder, adapter, LLM)
3. Related Works
기존 survey의 한계점
- LLM만을 다루거나, multimodal 적용은 부족.
\(\rightarrow\) 본 논문은 시계열 데이터를 multimodal 관점에서 확장하고, 해당 modality별로 적절한 MLLM 구조까지 포함한 최초의 서베이 .
4. Methodology
(1) Taxonomy of Time Series Modalities
| Modality | Advantage | Limitation | Example Domain |
|---|---|---|---|
| Number | Raw TS 그대로 | Interpretability 낮음 | General |
| Text | LLM과 호환성 높음 | Tokenizer 한계, context 제한 | Healthcare, Finance |
| Image | Vision encoder 활용 용이 | 해상도 민감, MTS 어려움 | Medical, IoT |
| Graph | Variate 간 관계 학습 가능 | UTS에 비적합 | Urban, Finance |
| Audio | 주파수 특성 표현 가능 | Preprocessing 부담 | Audio |
| Table | 채널 및 시간 정보 함께 표현 | 순서 정보 유지 어려움 | General |
(2) 각 modality 기반 대표 모델
- Number 기반: TimeGPT, TimesFM, Mantis, Chronos 등
- Text 기반: Time-LLM, ChatTime, GPT4MTS, PromptCast 등
- Image 기반: TimeSeriesExam, VisualTimeAnomaly, VisionTS, InsightMiner 등
- Graph 기반: STG-LLM, GATGPT, UrbanGPT 등
- Audio 기반: Voice2Series, AudioGPT, SpeechGPT
- Table 기반: TabPFN, TableTime, TableGPT2
(3) MLLM 구조 요소

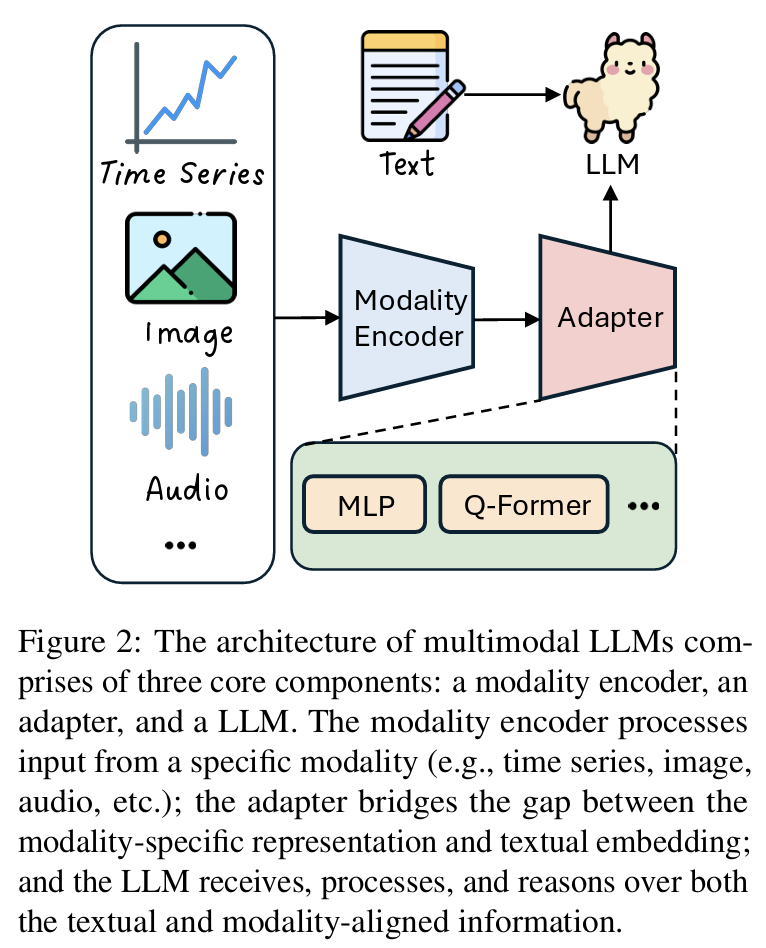
- Modality Encoder: 이미지, 오디오 등 입력 전처리
- Adapter: modality-specific → LLM input 정렬 (MLP, Q-Former 등)
- LLM: 일반적인 텍스트 기반 대형 언어 모델 (GPT, LLaMA 등)
5. Conclusion
-
MLLMs는 기존 TS 분석 패러다임을 넘어서는 큰 기회를 제공.
-
기존 LLM 기반 unimodal TS 연구를 넘어, cross-modal alignment, reasoning, generation까지 확장될 수 있음.
-
향후 연구 제안:
- Video 기반 시계열로의 확장
- Multimodal reasoning 및 agent 구조 설계
- Hallucination 완화 및 interpretability 개선
- Multimodal fine-tuning 기술 확립