
Exploiting Language Power for Time Series Forecasting with Exogenous Variables (WWW 2025)
- https://openreview.net/pdf?id=dFapOK8Rhb
- 인용 수 (2025-08-27): 2회
1. Abstract
(1) 기존 TS 연구
- 기존 TS 예측: “endogenous” variable에만 집중
- 현실 TS 세계: “exogenous” variable의 영향
(2) LLM의 등장
- LLM은 “복잡한 외부 환경”에 대한 사전 지식을 포함
- 그럼에도 FEV (Forecasting with Exogenous Variables)에 직접 활용하기 어려움.
(3) Proposal: ExoLLM
-
LLM 기반 FEV 프레임워크
-
주요 기법:
- Meta-task Instruction
- Multi-grained Prompt
- Dual TS-Text Attention
(4) Experiments
-
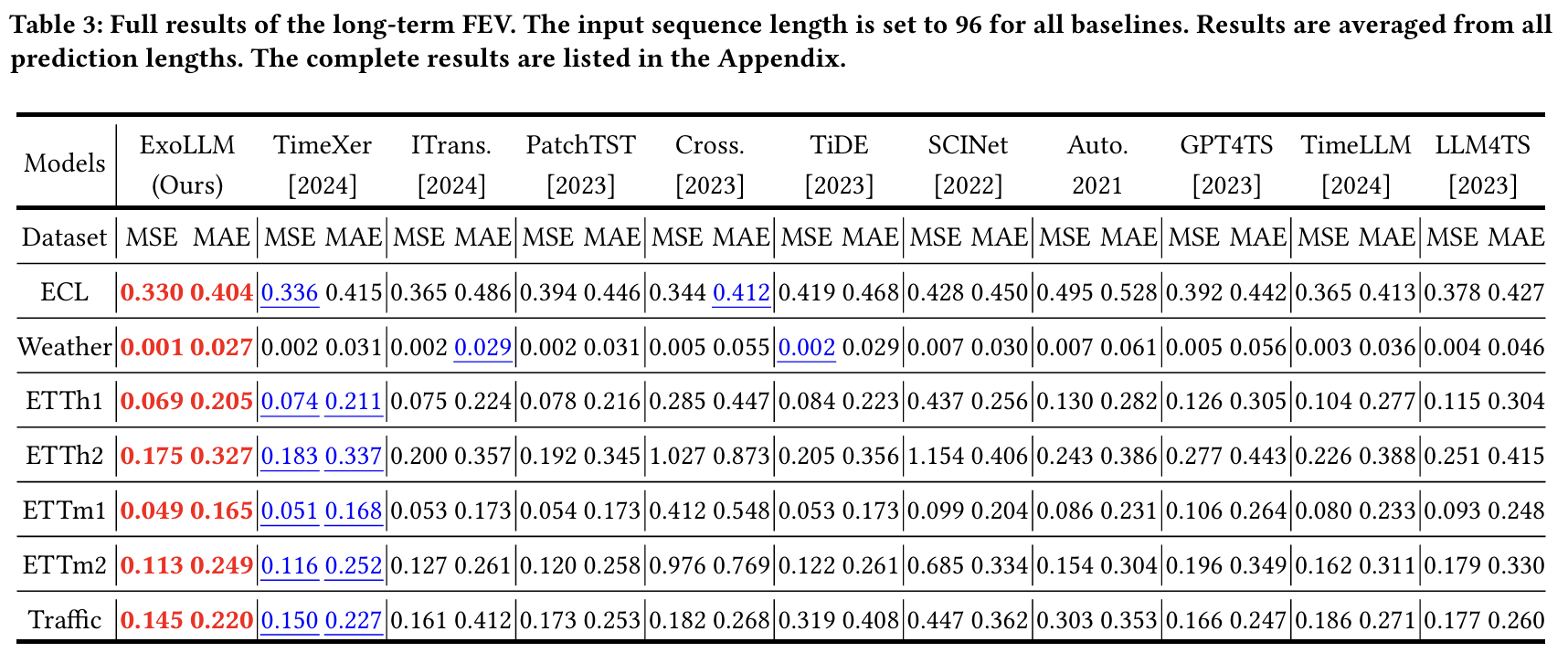
다양한 실제 데이터셋에서 ExoLLM이 우수한 예측 성능을 달성함.
-
코드 공개: ExoLLM Repo
2. Introduction
(1) Motivation
-
현실 TS는 외부 요인 (exogenous variables)의 영향을 크게 받음.
-
Uni-modality로는 복잡한 외부 요인을 포착하기 어려움
\(\rightarrow\) spurious correlation이 발생할 수 있음.
-
LLMs는 open-world knowledge를 통해 이러한 외부 영향력을 이해할 수 있는 잠재력을 가짐!
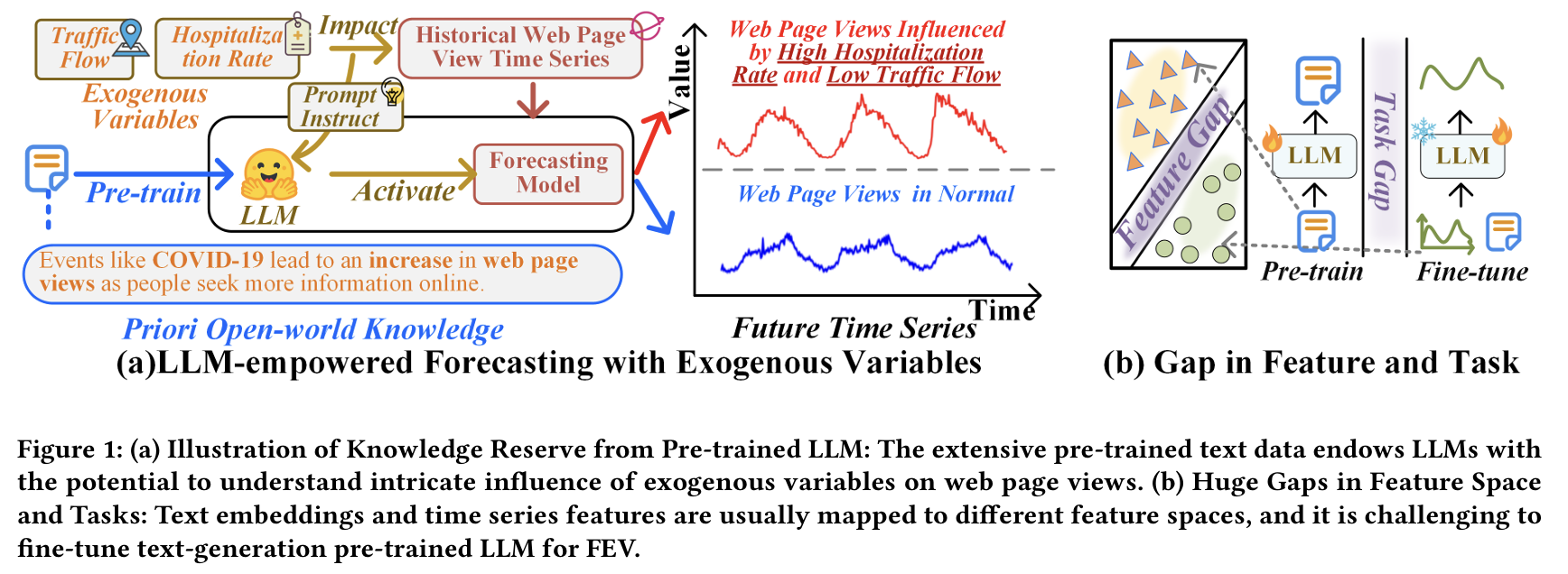
(2) Proposal: ExoLLM
LLM의 언어 기반 지식을 활용하여 FEV 문제를 해결
Main contributions
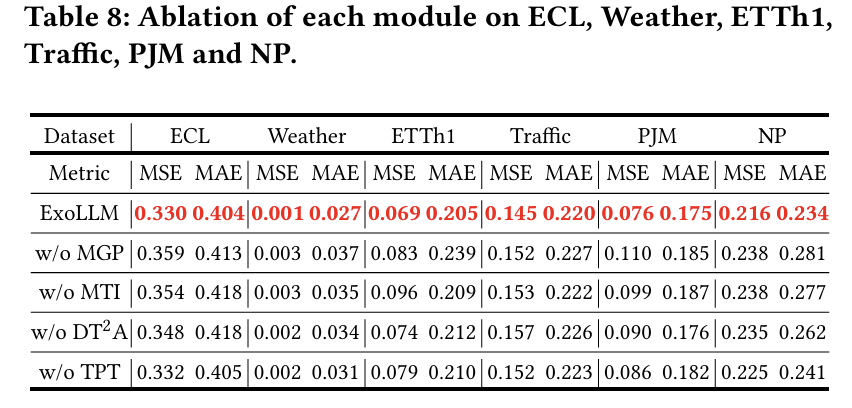
- a) Meta-task Instruction: LLM에게 FEV task를 명확히 인식시킴.
- b) Multi-grained Prompt: Exogenous variable의 다양한 속성 (추세, 주기성 등)을 포함.
- c) Dual TS-Text Attention: TS & Text embedding 간의 feature space alignment
3. Related Works
(1) Forecasting with Exogenous Variables
a) 통계적 접근: ARIMAX, SARIMAX.
b) DL 기반: N-BEATSx, TiDE, TimeXer – numeric correlation 기반의 보조 정보만 활용.
\(\rightarrow\) 한계: textual world knowledge를 활용한 exogenous modeling 부재
(2) LLM-based Forecasting
기존 연구: GPT4TS, LLM4TS, TimeLLM, Tempo, UniTime.
- 대부분 endogenous 중심. Exogenous modeling은 없음
\(\rightarrow\) ExoLLM은 최초로 LLM을 통해 FEV에 적용한 프레임워크!

4. Methodology
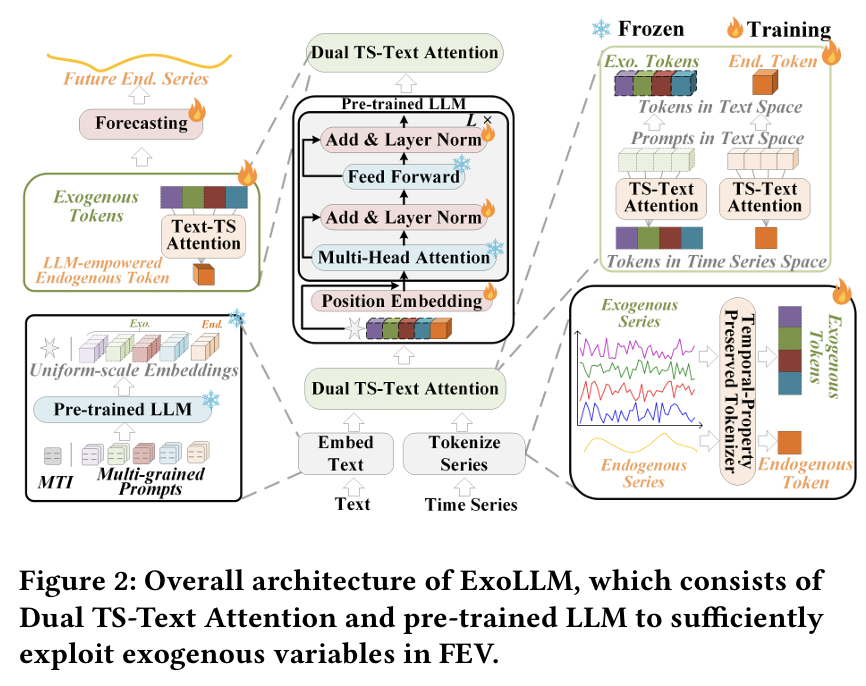
- Meta-task Instruction (MTI):
- 도메인 설명, 변수 요약, FEV task 소개
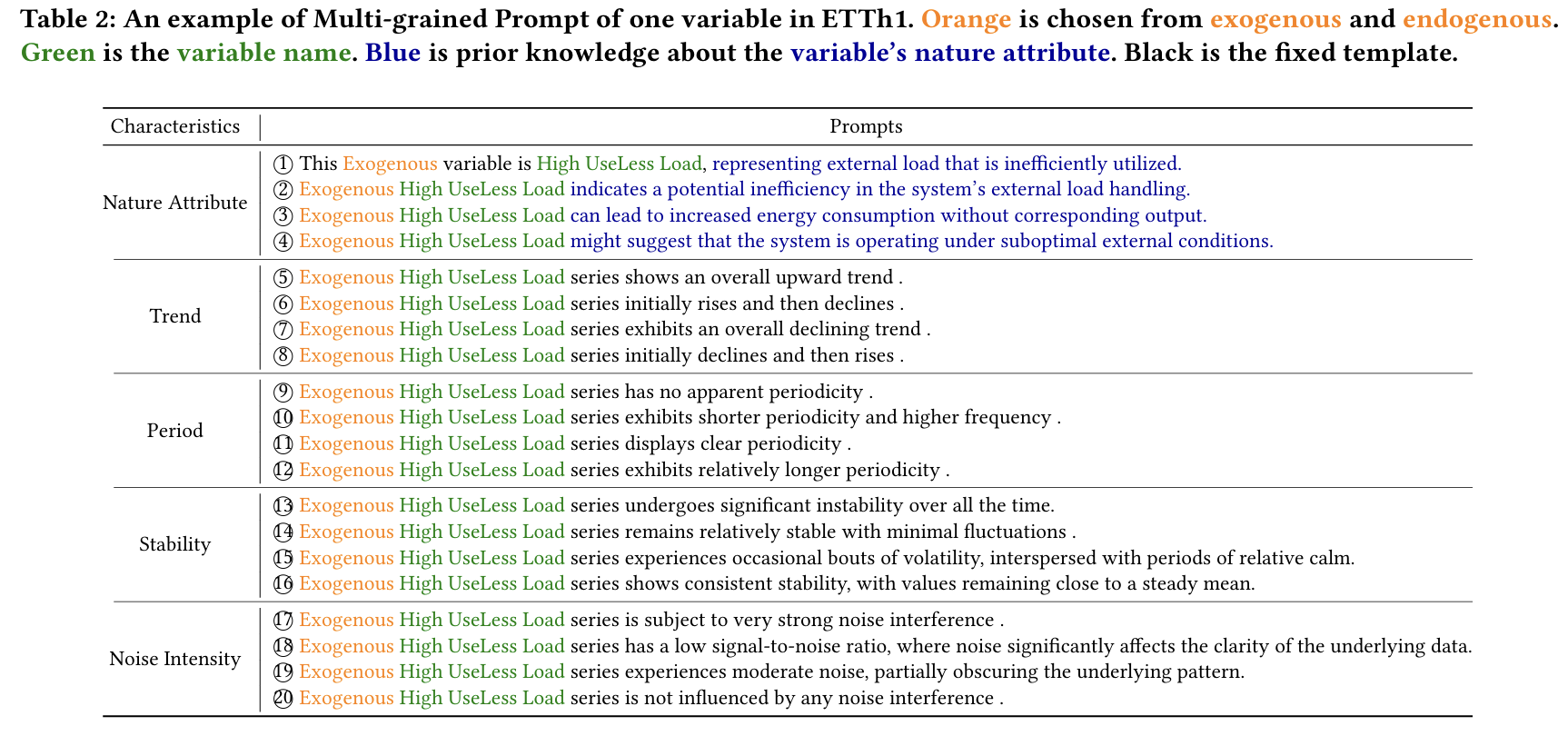
- Multi-grained Prompt (MGP):
- 각 변수의 속성 (자연속성, 추세, 주기, 안정성, 노이즈 등)을 다양한 문장 형태로 생성.
- Knowledge-retained LLM Encoder:
- task + exo + endo를 시퀀스로 구성하여 LLM encoding.
- Temporal-property Preserved Tokenizer (TPT):
- TS Patch 단위로 token화 후, 마지막 Patch 사용.
- Dual TS-Text Attention (DT2Attention):
- TS → Text attention: TS token을 Text embedding과 정렬
- Text → TS attention: LLM output을 다시 TS 도메인으로 역변환
- Forecasting Head:
- 최종 token을 Linear layer로 mapping하여 예측 수행 .

5. Experiments
https://anonymous.4open.science/r/ExoLLM
(1) Dataset
총 12개 실세계 데이터셋 사용:
- Long-term: ETT(h/m), Weather, ECL, Traffic (7개)
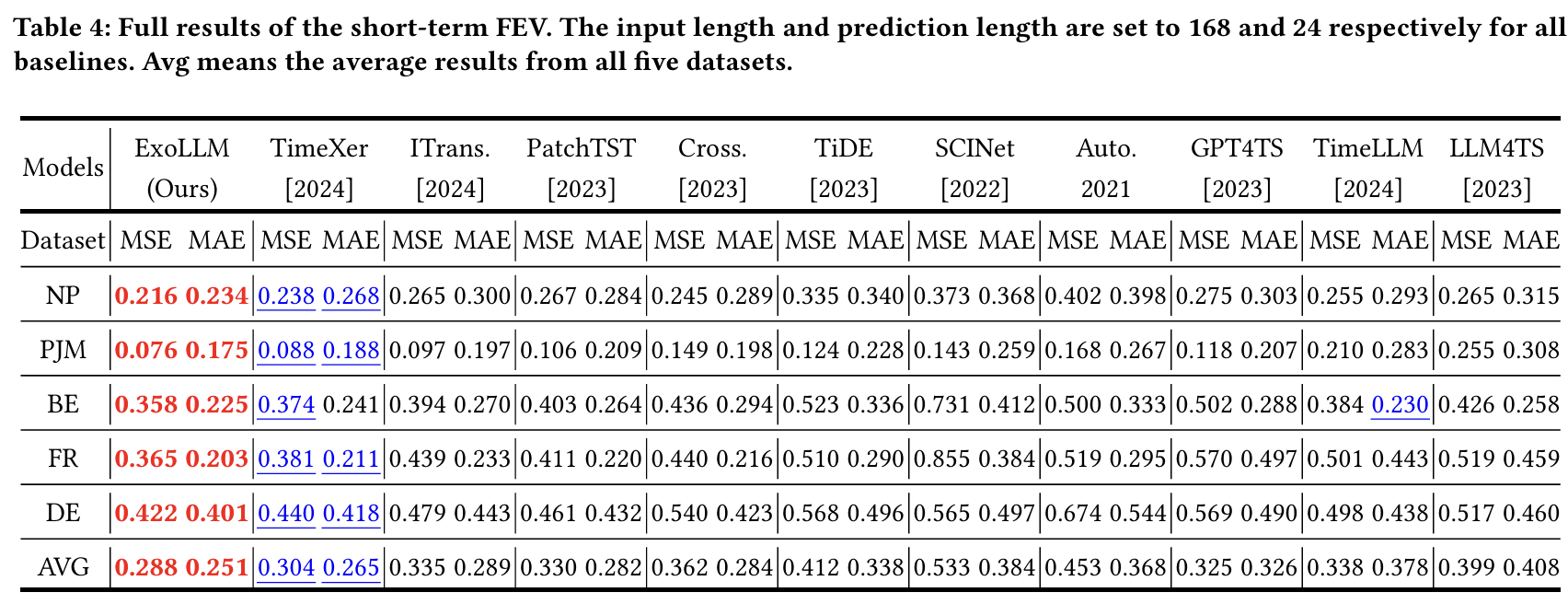
- Short-term (전력 가격): NP, PJM, BE, FR, DE (5개)
(2) Task
- Long-term Forecasting
- Short-term Forecasting
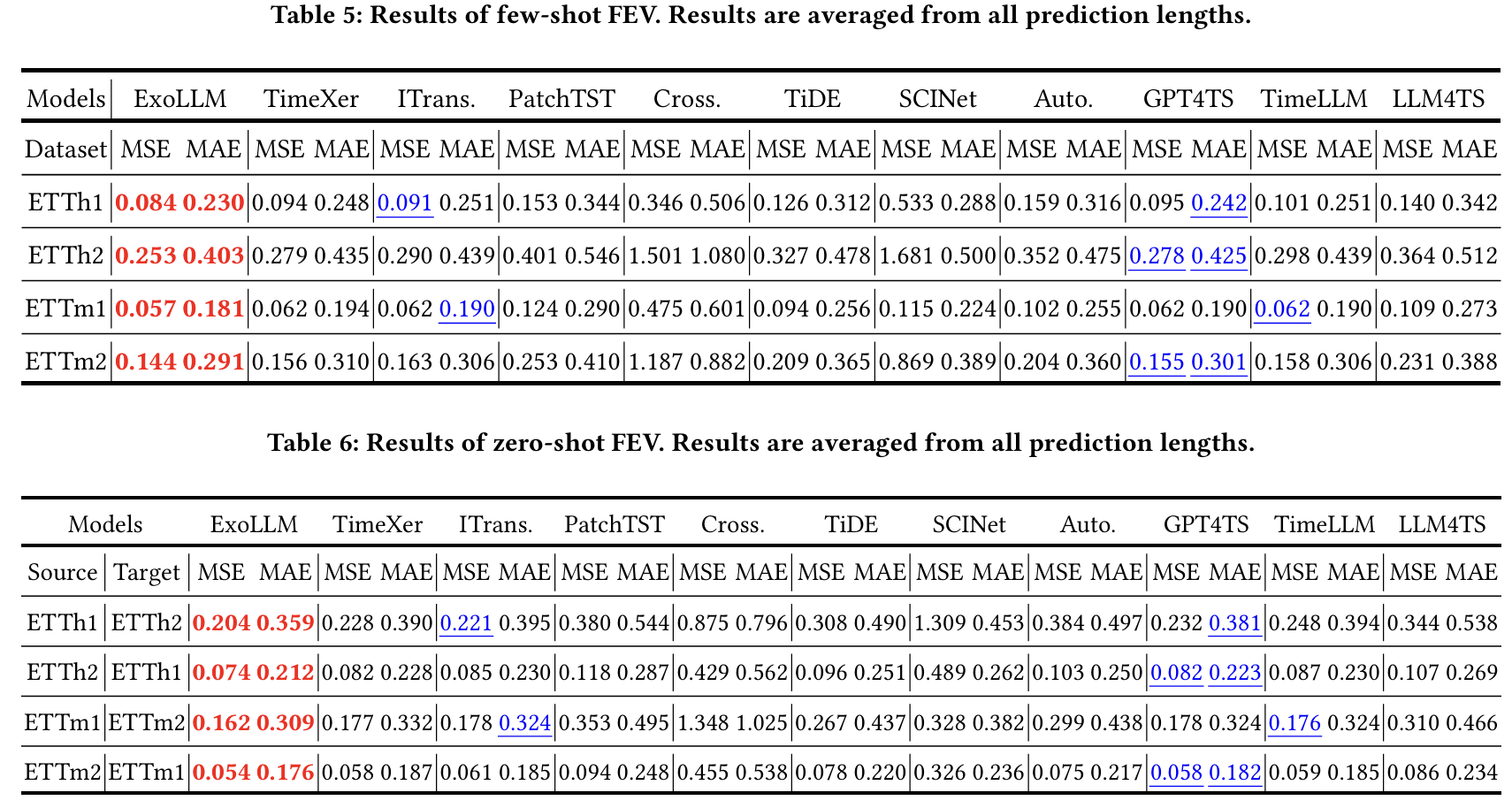
- Few-shot (10% data만 사용)
- Zero-shot (source→target transfer)
(3) 비교 Baseline
- LLM 기반: GPT4TS, LLM4TS, TimeLLM
- Transformer 기반: PatchTST, Autoformer, Crossformer, TimeXer, ITransformer
- CNN 기반: SCINet
- Linear 기반: TiDE
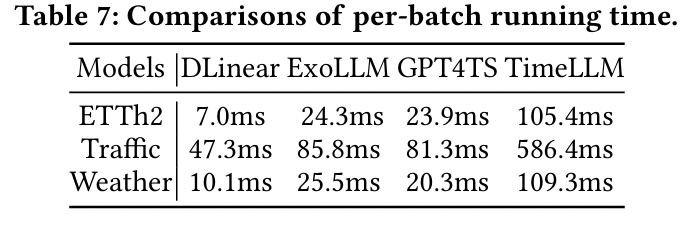
(4) Resource
- GPU: 2×NVIDIA H100 (80GB)
- LLM: GPT-2 (Text encoding에만 사용, 학습은 하지 않음)
- Patch length: 8, Max epoch: 50
- 모든 LLM 블록은 freeze 상태
6. Conclusion
- LLM의 언어 지식을 통해 시계열 예측에서의 외부 요인을 모델링
- Details
- Meta-task Instruction
- Multi-grained Prompt
- Dual TS-Text Attention
- Task: long-term, short-term, few-shot, zero-shot forecasting
- ExoLLM은 다양한 분야에서 structural/tabular data 학습에도 확장 가능성을 가짐 .