
TRACE: Grounding Time Series in Context for Multimodal Embedding and Retrieval (arxiv 2025)
- 인용 수 (2025-08-27 기준): 1회
- https://arxiv.org/pdf/2506.09114
1. Abstract
Limitaion
- 실세계 TS은 종종 Text 설명과 함께 나타남 (예: 기상 보고, 의료 차트).
- 기존 TS 모델은 “cross-modal alignment”와 “retrieval” 능력이 부족.
Proposal: TRACE
- TS과 Text 간의 “fine-grained” “dual-level” alignment
- Results
- 강력한 cross-modal retrieval
- 뛰어난 downstream forecast/classification 성능
- Details
- CIT(Channel Identity Token)
- Channel-biased Attention
- Hard Negative Mining
- Retrieval-Augmented Generation(RAG) 구조
Experiments:
- Forecasting error 최대 4.55% 감소
- Classification 정확도 최대 4.56% 증가 .
- [GitHub 링크 미공개]
2. Introduction
(1) Motivation
- 실세계를 반영한 TS은 종종 Text와 결합된 multimodal 형태.
- 예: 날씨 뉴스 → 해당 날의 온도, 습도, 풍속 등 TS 정보 연계 가능.
- 단순한 numeric matching은 semantic grounding 부족으로 실세계 reasoning에 미흡!!
(2) Proposal
TRACE는
-
TS과 Text를 channel-level + sample-level로 정렬
\(\rightarrow\) Cross-modal embedding을 학습함.
-
RAG 기반 forecasting도 지원 가능.
-
두 가지 역할:
- General-purpose retriever
- Standalone encoder (classification/forecasting용)
3. Related Works
Limitation
- TS Forecasting: 대부분 Unimodal
- e.g., Transformer, Linear, Frequency 기반
- TS + Language: 대부분 text는 global context, channel 단위 정렬은 미흡.
- e.g., ChatTS, ChatTime, TimeXL 등
- TS Retrieval: text 모달리티 부재 또는 alignment 부족.
- e.g., TS2VEC, TS-RAG
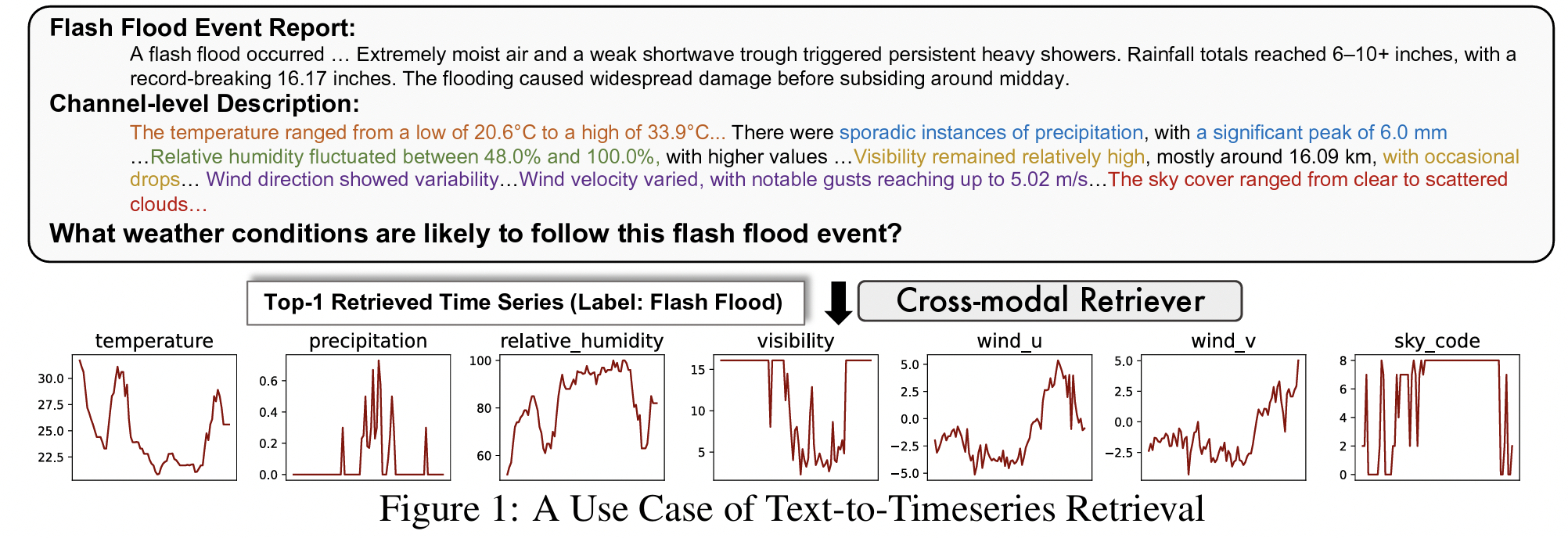
4. Methodology
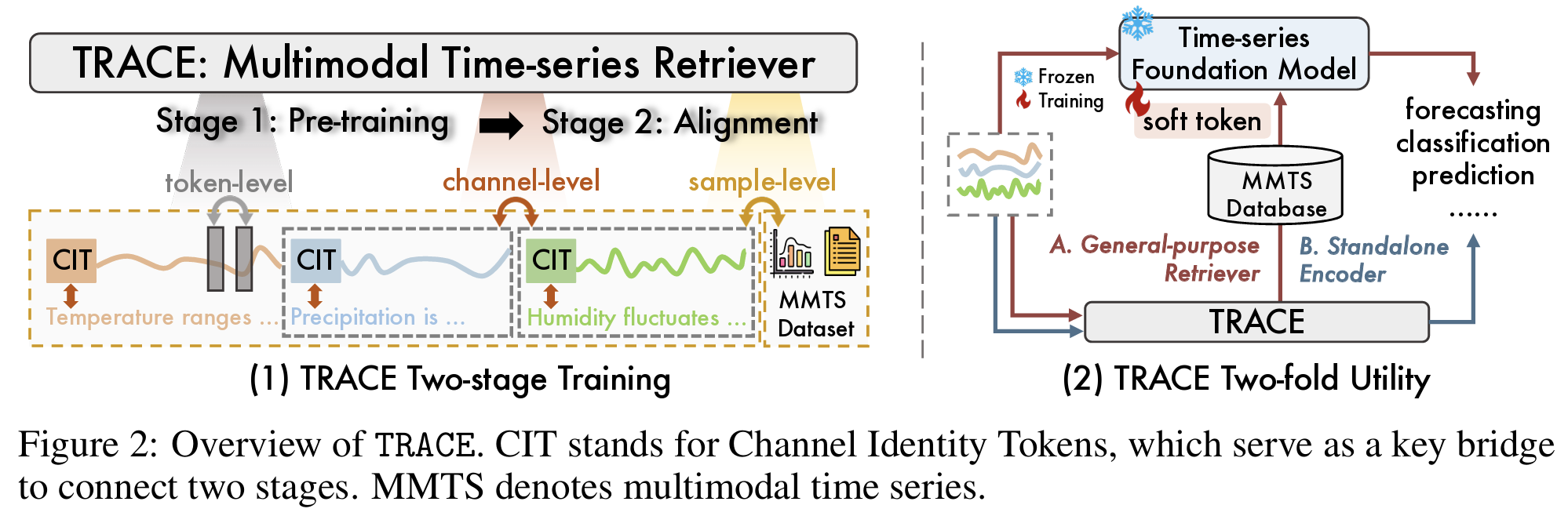
(1) Procedures
Stage 1 (Pretraining):
- Task: Masked reconstruction
- Channel-biased Attention (CbA) + CIT(token-level/channel-level 구분)
Stage 2 (Cross-modal Alignment):
- Dual-level contrastive learning (channel-level + sample-level)
- Hard negative mining 적용
(2) Components
- CIT: Channel 별 semantic summary를 위한 token
- CbA: Cross-channel attention 방지 → Channel 독립적 구조 학습
- RoPE: Channel 내부 TS에 위치 정보를 부여
- Contrastive Loss: sample-level ([CLS]) + channel-level (CIT) 쌍별 정렬
- RAG Prompt: soft token으로 인코딩된 multimodal vector를 downstream에 연결
5. Experiments
(1) Dataset
-
자체 구축한 기상 TS + Text 설명 데이터셋 (NOAA 기반)
-
Text 종류:
- (1) Event-level: 보고서 원문
- (2) Channel-level: LLM 기반 생성 요약
-
총 74,337개 (TS + Text)쌍 포함
-
추가로 TimeMMD (Health, Energy, Env) 도 사용
(2) Tasks
- Cross-modal Retrieval (Text ↔ TS)
- Retrieval-Augmented Forecasting
- (Standalone) Forecasting / Classification
(3) Baselines
- TS Forecast: DLinear, PatchTST, TimesNet, iTransformer, FSCA, TimeMixer
- TS Foundation: Chronos, Timer-XL, TimesFM, Moment, Time-MoE
- TS Retrieval: DTW, ED, SAX-VSM, CTSR
- TS+Text: FSCA, TimeCMA, ChatTS
(4) Resource
- 6-layer Transformer, hidden dim 384, batch size 256
- GPU: A100 40GB
- Epochs: pretrain 400, align 300
- Inference 시 prompt만 학습, 본 모델은 freeze 상태 유지
6. Conclusion
-
TRACE는 multimodal TS + Text 정렬을 구조적으로 해결.
-
두 가지 용도로 강력함:
- Retriever: downstream task에 context 제공
- Encoder: 단독 forecast/classification에서도 SOTA 성능
-
한계: alignment된 Text 필요, 계산비용 증가
-
미래 방향: semi-supervised setting, 다른 modality 통합, autoregressive generation 확장 .