
Towards Time-Series Reasoning with LLMs (NeurIPSW 2024)
1. Abstract
기존의 TS 관련 LLM 연구는 forecasting 중심
\(\rightarrow\) 자연어 기반 reasoning은 미개척 분야.
Proposal: Zero-shot generalizable한 “TS reasoning 모델”을 제안
- LLM 위에 lightweight TS encoder
- Chain-of-thought (CoT)이 포함된 reasoning task로 fine-tuning
Experiment
- 모델이 slope, frequency 등의 특징을 잘 학습
- GPT-4o를 능가하는 zero-shot reasoning 성능을 달성
2. Introduction
(1) Motivation
-
TS 정보를 "”인간처럼 이해하고 해석”“하는 능력은 (의료, 금융, 환경 분야에서) 매우 중요!!
-
기존 MLLM은 vision 등에서 성공
\(\rightarrow\) But, TS에 대한 자연어 reasoning은 아직 구현되지 않음.
-
기존 방식은 TS를 Text로 변환 → 패턴 손실 발생!
(2) Proposal
LLM이 TS reasoning을 가능케 하는 구조 설계!
3단계: Perception → Contextualization → Deductive Reasoning
- Perception 병목: LLM에 부착된 TS 전용 encoder 학습 통해 해결
- 이후 CoT 기반 fine-tuning을 통해 reasoning 능력을 강화
3. Related Works
(1) Time-Series Forecasting with LLMs
한계점 2가지
- (1) 기존 연구는 forecasting에 집중
- LLM은 단순히 (Text가 아닌) TS forecasting을 위한 backbone으로만 활용
- (2) 대부분은 text output 불가능!!
- language modeling head 없음.
(2) Time-Series Question Answering
- TS을 문자열로 변환해 LLM에 입력 → 정보 손실 발생.
- Merrill et al. (2024)은 LLM이 여전히 TS reasoning에는 약하다고 지적함 .
4. Methodology
(1) Architecture
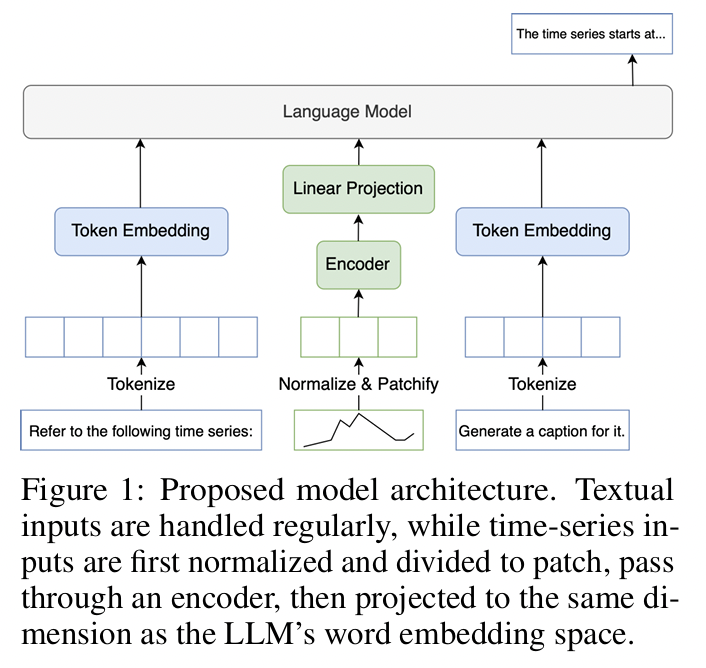
- TS 입력을 patch 단위로 분할 → MHSA → LLM의 임베딩 차원에 맞춰 투영.
- TS의 mean, std 정보는 text로 변환하여 prefix로 입력.
- [TS embedding, Prompt text embedding]을 함께 LLM에 입력.
- Mistral-7B를 LLM으로 사용.
- multivariate, multi-domain, interleaved format 지원 가능함.
(2) Training
- Stage 1:
- Encoder warm-up (LLM은 freeze 상태)
- Synthetic QA → captioning으로 점진적 curriculum 학습.
- Stage 2:
- LoRA를 통한 full model fine-tuning
- CoT 포함 downstream task 학습
5. Experiments
(1) Perception 평가
Captioning task
- e.g., 모델이 생성한 caption을 GPT-4o에게 입력 → etiological reasoning task 수행.
결론:
-
Mistral-7B + encoder 조합은 기존 text-only보다 정보 반영력이 큼 (0.387 vs 0.272) .
-
t-SNE 분석 결과, slope, freq 등 특성이 encoder를 통해 latent space에 잘 반영됨 (p.4, Fig.3 참조).
(2,3) Contextualization & Deductive Reasoning

-
UCR Archive 기반 zero-shot classification 평가 (11개 binary dataset 선정).
-
GPT-4o보다 다수 데이터셋에서 성능 우수:
- 예: Chinatown (Ours: 0.698 vs GPT-4o-text: 0.347, plot: 0.287)
- ItalyPowerDemand (Ours: 0.701 vs GPT-4o-text: 0.564)
-
GPT-4o는 TS encoder 부재로 추론 성능 미흡 !!
6. Conclusion
-
TS reasoning을 위한 핵심 능력을 정의 & 이를 구현하는 LLM 기반 framework 제안.
-
Encoder + CoT fine-tuning을 통해 Mistral-7B 같은 소형 모델도 GPT-4o를 초과하는 추론 성능 달성 가능함을 입증.
-
인간 논리와 유사한 자연어 기반 TS 해석을 제공
\(\rightarrow\) Complex decision-making 및 multimodal agent로 확장 가능성을 시사