
LIMA: Less Is More for Alignment
Zhou, Chunting, et al. "Lima: Less is more for alignment." NeurIPS 2023
( https://arxiv.org/pdf/2305.11206 )
참고:
- https://aipapersacademy.com/lima/
Contents
- Abstract
- LLM Training Stages
- How LIMA can improve LLMs training process?
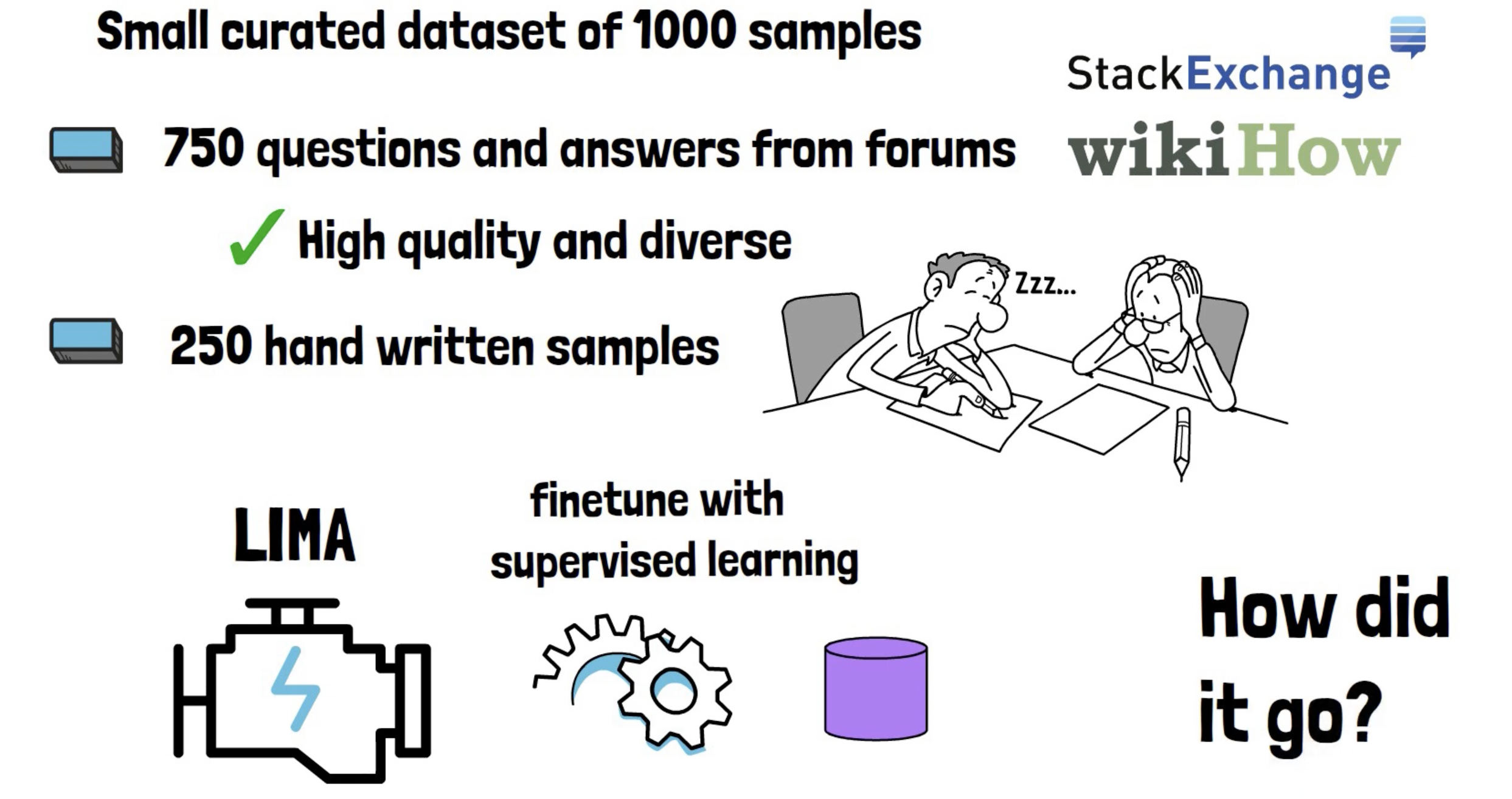
- Small datasets with 1000 samples
- Experiments
1. Abstract
LIMA = Less Is More for Alignment ( by Met AI)
-
Fine-tune the LLaMa model on only 1000 samples
\(\rightarrow\) Achieve competitive results with top large language models (such as GPT-4, Bard and Alpaca)
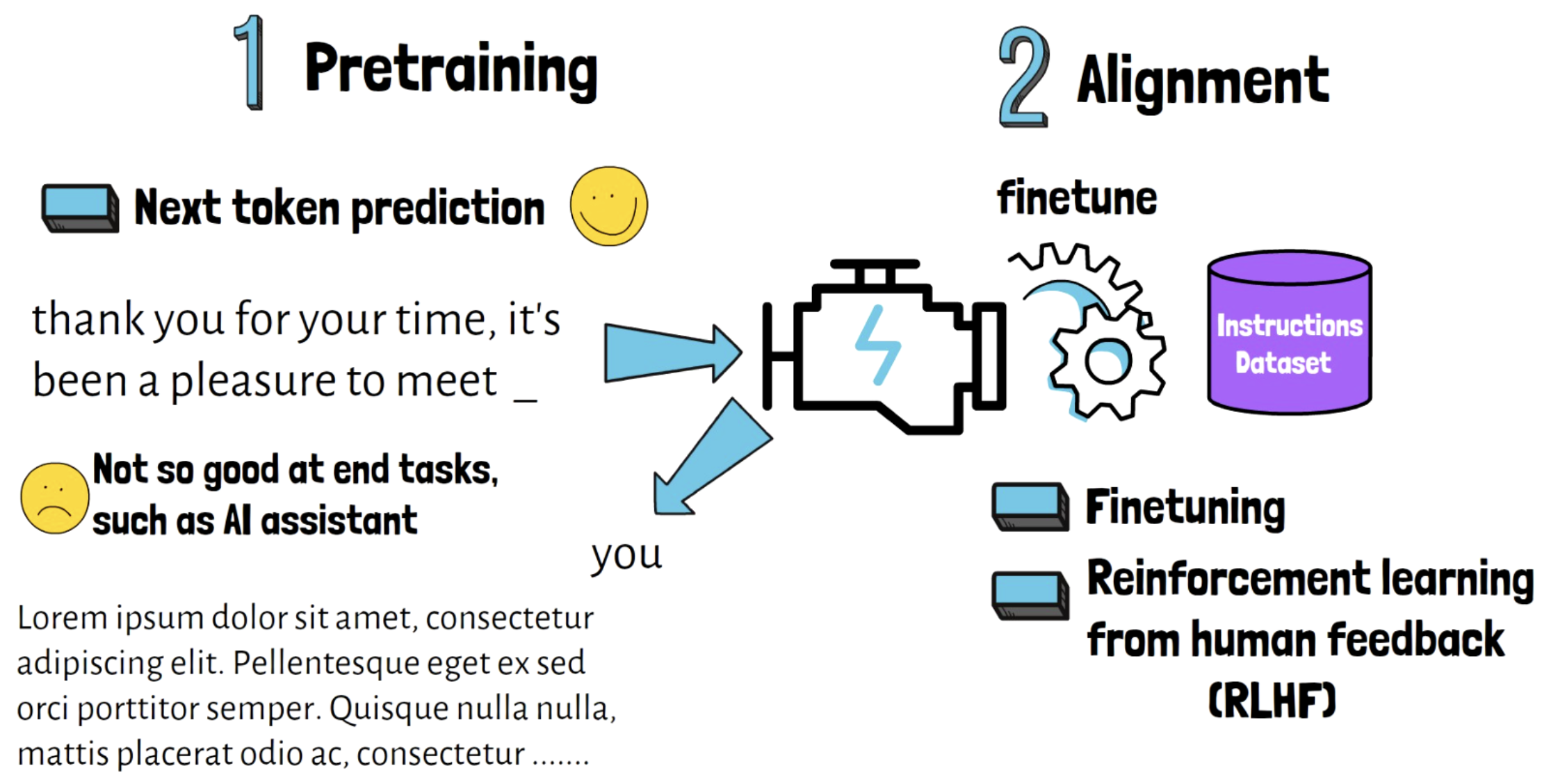
2. LLM Training Stages
Stage 1) Pre-training stage: NSP task
Stage 2) Alignment stage
-
Not very good with helping in concrete tasks that LLMs are often used for
\(\rightarrow\) Need alignment!
-
Pretrained model is being fine-tuned on a specific task dataset
- e.g., instructions dataset human feedback with reinforcement learning (RLHF)
3. How LIMA can improve LLMs training process?
Proposal: Alignment stage can be replaced with a much more lightweight process of fine-tuning on just a small dataset
\(\rightarrow\) Still achieve remarkable and competitive results!
Why does it work well?
\(\rightarrow\) Superficial alignment hypothesis
Superficial Alignment Hypothesis
Key point: A model has learned almost entirely during the pretraining stage!
Thus, alignment stage = simple! only requires to learn..
- What part of knowledge to use
- What is the correct format
\(\rightarrow\) SHORT fine-tuning can ruin less of the pretraining knowledge ( & avoid catastrophic forgetting )
4. Small datasets with 1000 samples
5. Experiments
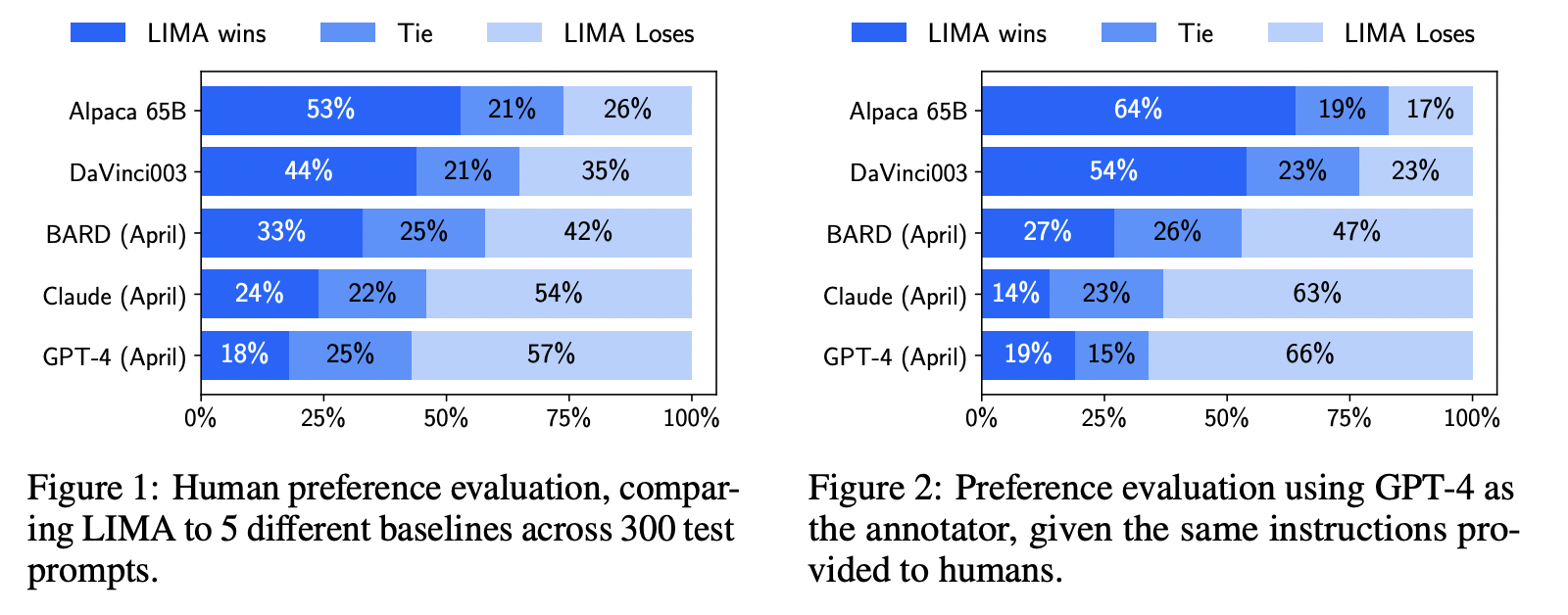
- Alpaca = LLaMa + fine-tune on LARGE instructions dataset
- LIMA= LLaMa + fine-tune on SMALL instructions dataset
- DaVinci003 = (based on InstructGPT) trained with RLHF