
MMRL: Multi-Modal Representation Learning for Vision-Language Models
Contents
- Abstract
- MMRL
- Previous Works vs. MMRL
- Training & Inference of MMRL
- Introduction
- VLMs
- Prompt-based approaches
- Adapter-style learning methods
- Proposal: MMRL
- Related Works
- VLMs
- Efficient Transfer Learning
0. Abstract
Large-scale pre-trained VLMs
- Essential for transfer learning
- Adapting with “limited” few-shot data \(\rightarrow\) Overfitting!
(1) MMRL
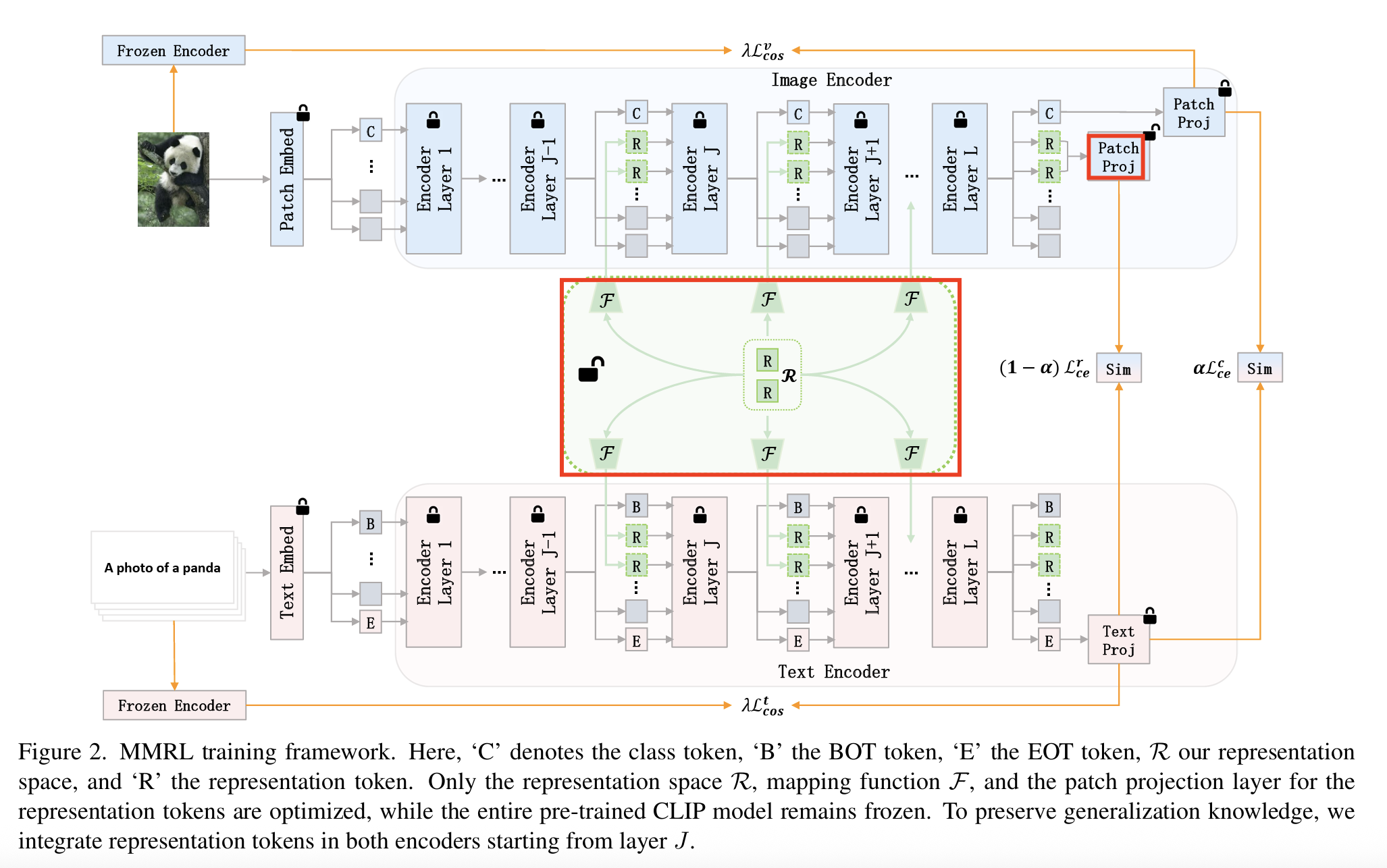
Proposal: Multi-Modal Representation Learning (MMRL)
- (1) Shared + (2) Learnable + (3) Modality-agnostic representation space
- Projects the “space” tokens \(\rightarrow\) “text & image” representation tokens
\(\rightarrow\) Facilitating more effective multi-modal interactions
(2) Previous works vs. MMRL
[Previous] Solely optimize class token features
[MMRL] Integrates representation tokens at higher layers of the encoders
- Higher layers = Dataset-specific features
- Lower layers = Generalized knowledge
(3) Training & Inference of MMRL
a) Training
Both (1) representation features & (2) class features are optimized
- (1) Representation tokens: with “trainable” projection layer
- (2) Class token: with “frozen” projection layer
Regularization term
- To align the class features & text features with the zero-shot features from the frozen VLM
- Safeguarding the model’s generalization capacity
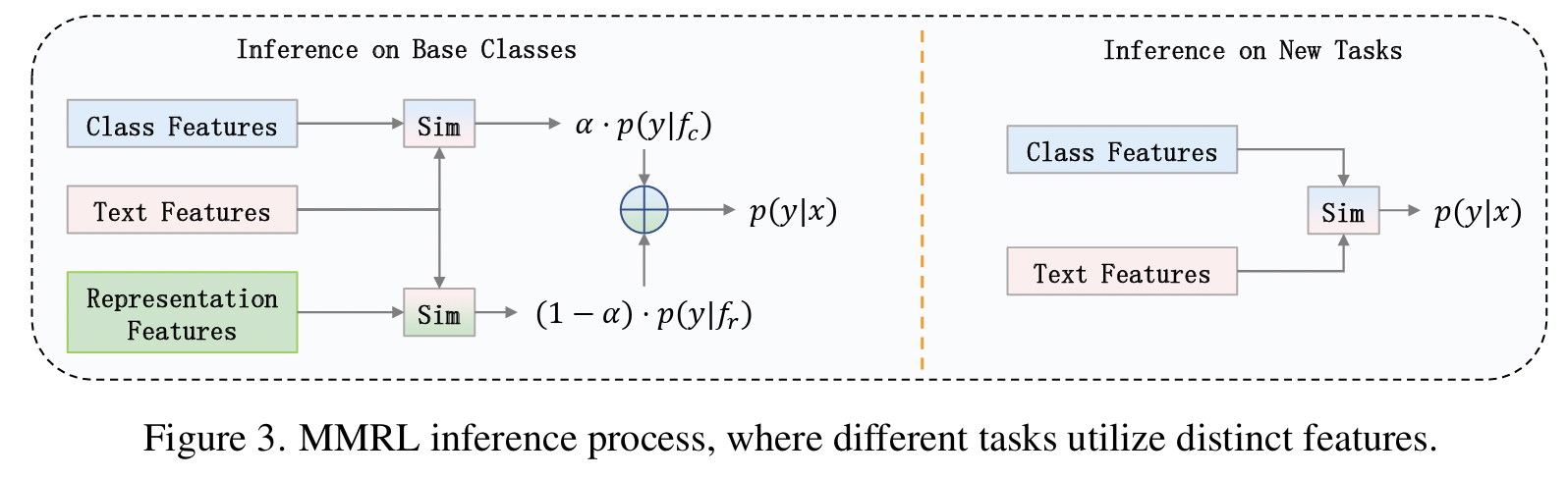
b) Inference
**Decoupling strategy **
- [For “base” class] Both representation & class features
- [For “new” task] Only the class features
- which retain more generalized knowledge
https://github.com/yunncheng/MMRL
1. Introduction
(1) VLMs
CLIP-based models
- “Distinct” encoders for images & text
- Employ CL on over 400 million image-text pairs
Limitation of VLMs: Adapting to new tasks
\(\rightarrow\) \(\because\) Fine-tuning requires considerable computational resources
Efficient adaptation of VLMs
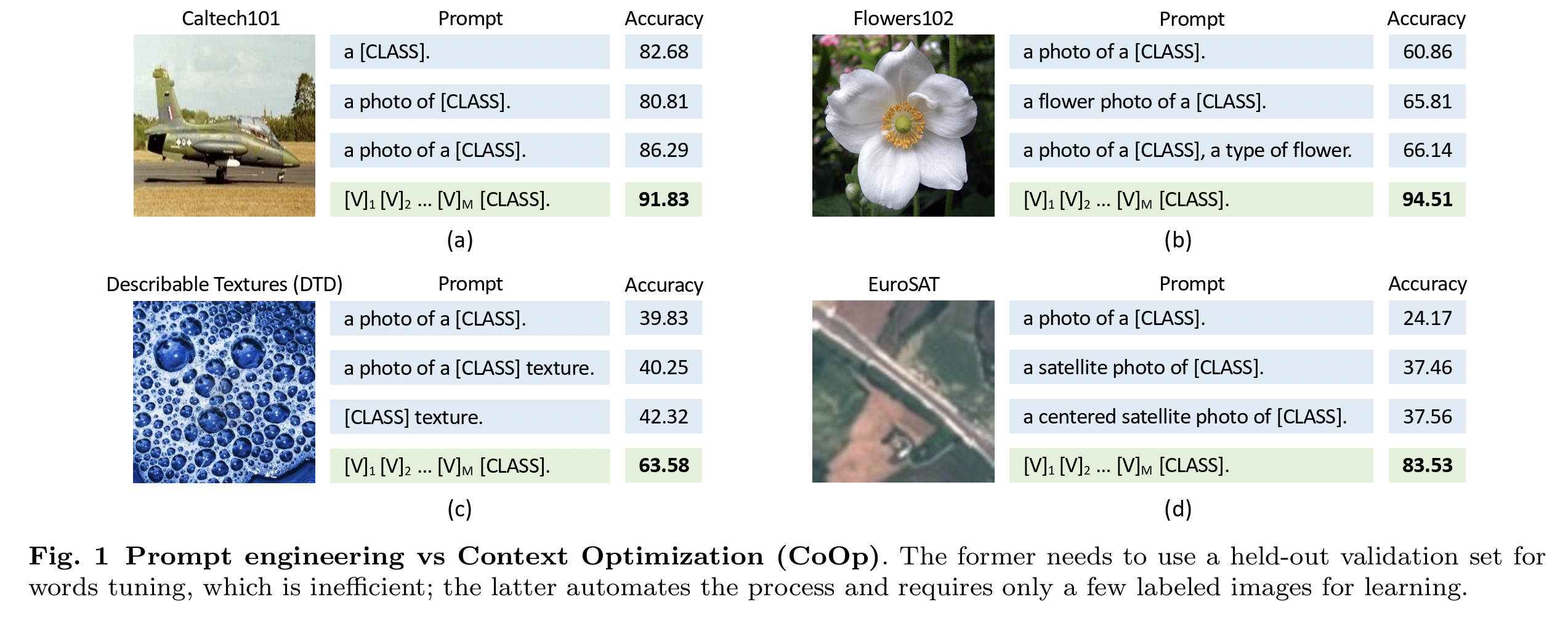
- a) Prompt engineering
- Involves crafting dataset-specific prompts
- e.g., “A photo of a [CLASS], a type of pet.”*
- Involves crafting dataset-specific prompts
- b) Ensembling
- Integrate multiple zero-shot classifiers by varying context prompts
- e.g., “A photo of a big [CLASS].” and “A photo of a small [CLASS].”
- Integrate multiple zero-shot classifiers by varying context prompts
(2) Prompt-based approaches
(1) CoOp
-
[Background] Manual prompt design is time-consuming!!
(+ Does not guarantee the discovery of optimal prompts )
-
[Proposal] “Prompt learning”
-
Prompts are modeled as continuous learnable vectors
-
Optimized during training while keeping VLM parameters fixed
\(\rightarrow\) Enable efficient dataset adaptation
-
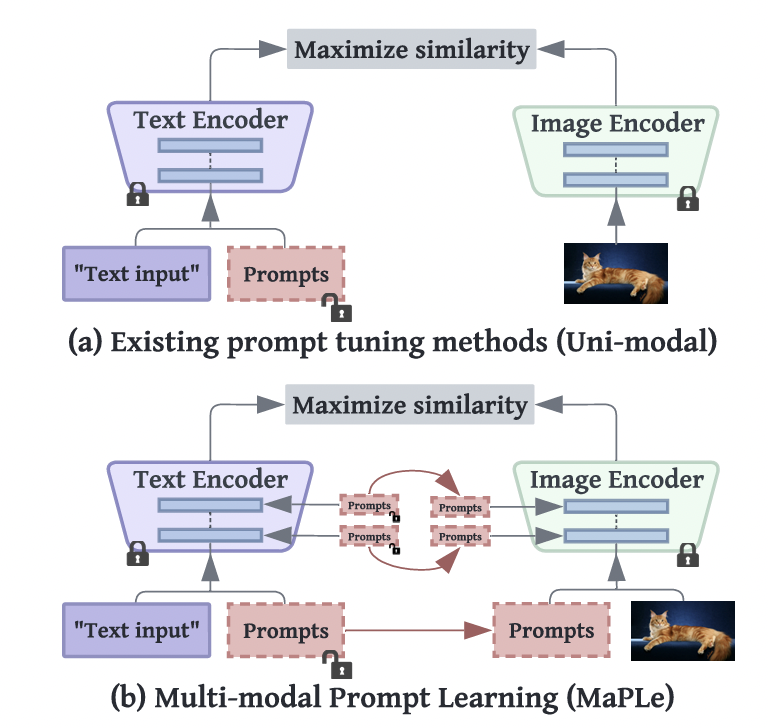
(2) MaPLe
- [Background] Identified that prompt learning solely within the TEXT modality may be sub-optimal
- [Proposal] Proposes a “Multi-modal prompt learning” approach
- Embed deep prompts into the lower layers of both VLM encoders
- Via a coupling function to enhance alignment between visual and textual representations.
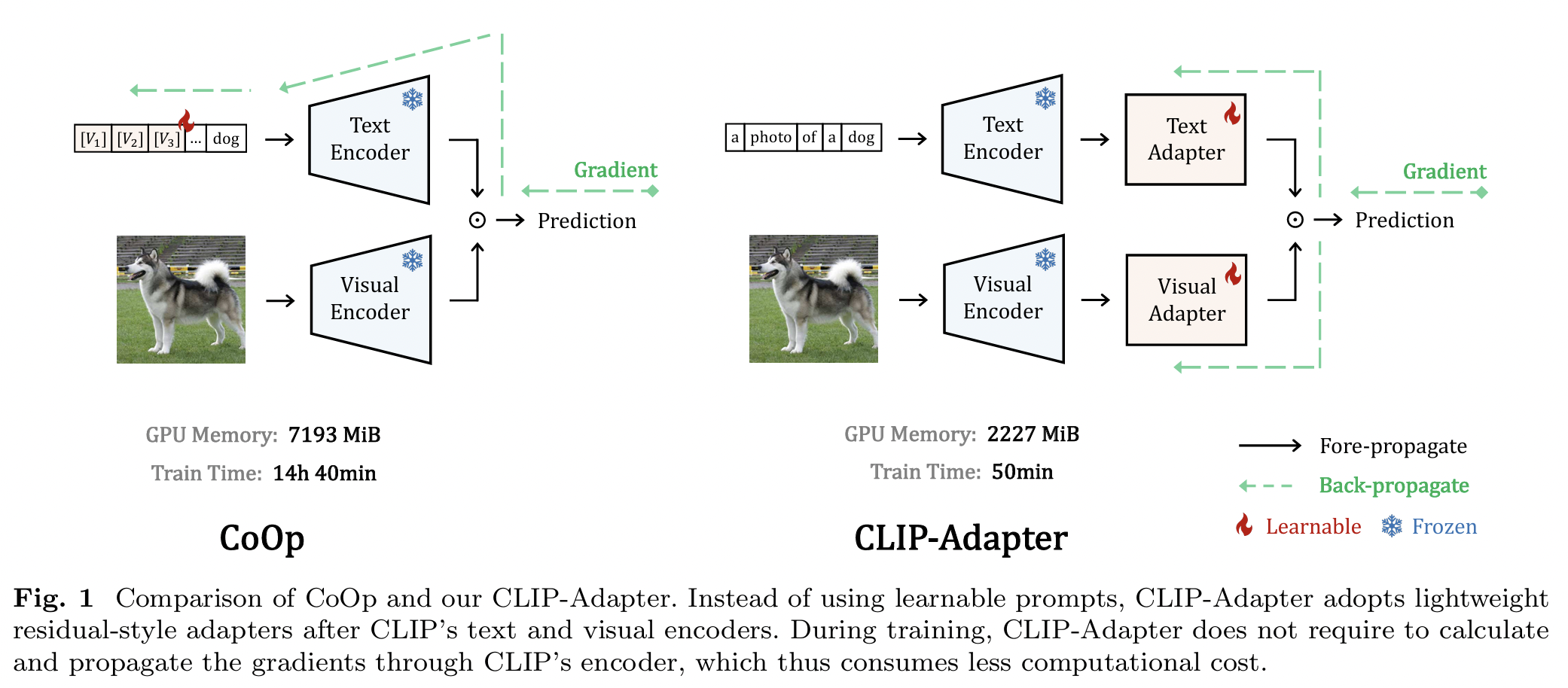
(3) Adapter-style learning methods
Lightweight modules (e.g., MLPs) are integrated within VLMs
$\rightarrow$ To adjust extracted features for downstream datasets
(1) CLIP-Adapter
-
Freeze VLM
-
Fine-tuning features via an MLP adapter added to the image encoder
(Incorporates residual connections for feature fusion)
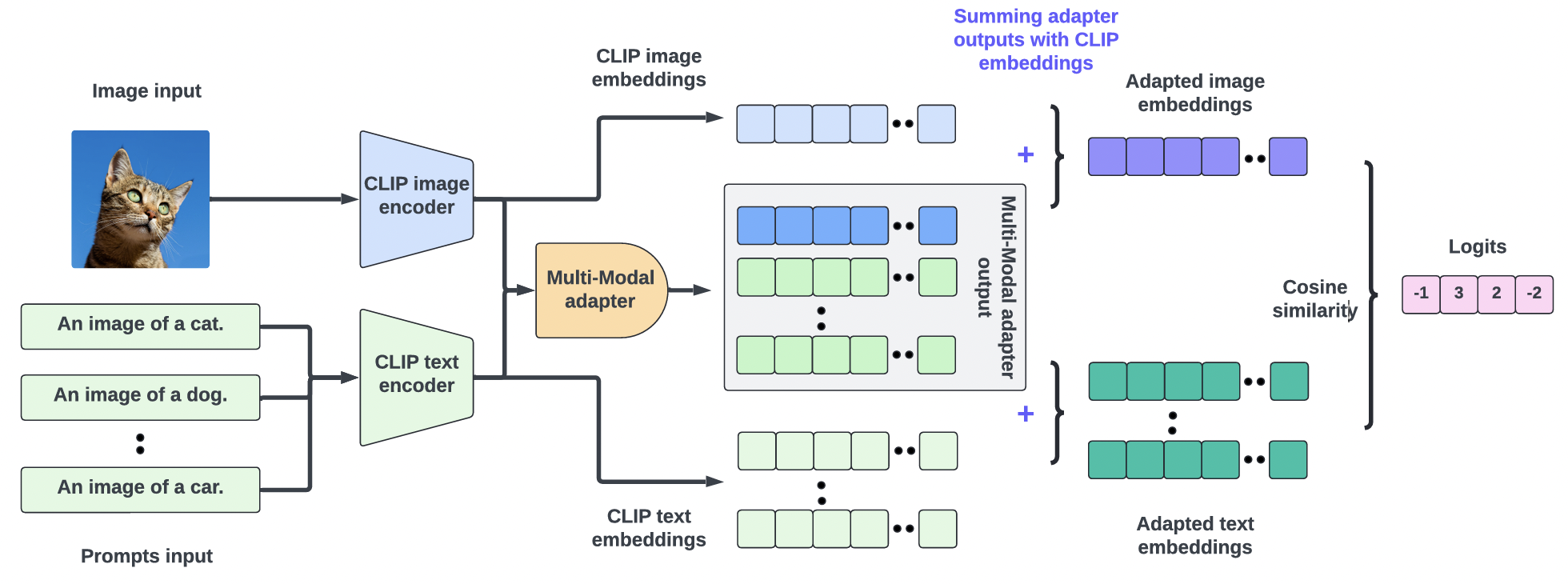
(2) MMA
- Multimodal adapter
- Refines the alignment between text & vision
- By aggregating features from diverse branches into a unified feature space
- Reveals that different layers within VLM encoders capture varying characteristics
- “Higher” layers = Discriminative, dataset-specific information
- “Lower” layers = Generalizable features
Current multimodal deep prompt learning method
- Applies prompt concatenation at shallow layer
\(\rightarrow\) May compromise generalizable knowledge
Limitation of previous works
-
[Prompting] Map visual prompts from text prompts
-
Incorporate visual information via gradient propagation but ultimately remaining text-centric
\(\rightarrow\) Updates focused mainly on text prompts
-
-
[Prompting & Adapter-style] Solely optimize class token features using task-specific objectives
\(\rightarrow\) Vulnerable to overfitting to specific data distributions or task categories
- Especially when training data is scarce (e.g., few-shot setting)
(4) Proposal: MMRL
-
Novel multimodal representation learning framework
- Distinguishes from prompt learning and adapter-style methods
-
Shared, learnable representation space
- Independent of any modality within the higher layers of the encoder
- Serves as a bridge for multimodal interaction
- Mapping tokens from this space \(\rightarrow\) image and text tokens
- Concatenated with the original encoder tokens
-
Two types of tokens
- (1) Representation tokens
- Designed to learn dataset-specific knowledge from downstream tasks
- (2) (Original) Classification token
- Regularized to retain a significant amount of generalizable knowledge.
- (1) Representation tokens
-
Three key advantages
- (1) “Unbiased shared” representation space
- (2) Preservation of original “VLM generalization”
- By avoiding prompt integration at shallow encoder layers
- (3) “Decoupled inference” across classes
- Prompt learning & adapter-style methods: Refine only the class token features through learnable prompts or adapters
-
Prioritize optimizing “representation token” features,
- Projection layer: trainable
- Class token: fixed
-
Regularization term
- Goal: To further preserve the generalizability of the class token
- Aligns its features with the zero-shot features from the frozen VLM.
-
Inference
- [Base classes] Use both representation and class token features
- [Unseen classes] Use only the class token features
Main Contributions
- Multi-Modal Representation Learning (MMRL) framework
- Incorporates a shared, unbiased, learnable space that bridges image and text modalities
- Facilitate multimodal interaction at the high layers of the original encoder.
- **Decoupling strategy **
- Preserves VLM generalization by adapting representation tokens for downstream tasks
- Regularizing the original class token for new tasks.
- Extensive experiments
- Substantially improves downstream adaptation and generalization
2. Related Work
(1) VLMs
VLMs
- Typically learn joint image-language representations via SSL
- Leverage large-scale architectures & massive collections of image-text pairs
- e.g., CLIP [34], ALIGN [16], FILIP [50], KOSMOS [15, 33], and VILA [24]
Examples
- CLIP: Trained on a collection of 400 million image-text pairs
- ALIGN: Leverages an impressive 1.8 billion pairs
Pros & Cons
- Pros: Excel at learning generalized representations
- Cons: Efficiently adapting them to specific downstream tasks remains a challenge
(2) Efficient Transfer Learning
a) Prompt Learning
Effective for adapting VLMs
Examples
-
(1) CoOp: Prompt learning by replacing fixed templates with learnable continuous vectors
\(\rightarrow\) But compromising CLIP’s zero-shot and generalization capabilities.
-
(2) CoCoOp: Incorporates visual cues to generate instance specific prompts
\(\rightarrow\) Improve generalization to class distribution shifts
- (3) ProDA: Learns prompt distributions to enhance adaptability
- (4) PLOT: Optimal transport to align the vision and text modalities
- (5) KgCoOp: Retains general textual knowledge by minimizing divergence btw learned & crafted prompts
- (6) ProGrad: Selectively updates gradients aligned with general knowledge
- (7) RPO: Mitigates internal representation shifts using masked attention
Moving beyond text-focused approaches
- (8) MaPLe: Integrates visual prompts mapped from text prompts through a coupling function
- (9) ProVP: Employs single-modal visual prompts with contrastive feature re-formation
- To align prompted visual features with CLIP’s distribution
- (10) PromptSRC: Employs a self-regularization strategy to mitigate overfitting
- (11) MetaPrompt: Meta learning-based prompt tuning algorithm that encourages task-specific prompts to generalize across various domains orclasses
- (12) TCP: Adapts textual knowledge into class aware tokens