CAA (Contrastive Activation Addition) (ACL 2024)
논문: Steering Llama 2 via Contrastive Activation Addition
1. ACTADD vs. CAA
(공통점: 학습 없이 도출하는 방법론)
-
ACTADD는 단일 contrast prompt
-
CAA는 데이터셋 전체에서 여러 개의 contrast pairs
\(\rightarrow\) 더 일반화된 shift vector
2. Procedures
- 여러 contrast pairs 준비
- 예: (helpful vs harmful), (polite vs rude), (truthful vs hallucinated)
-
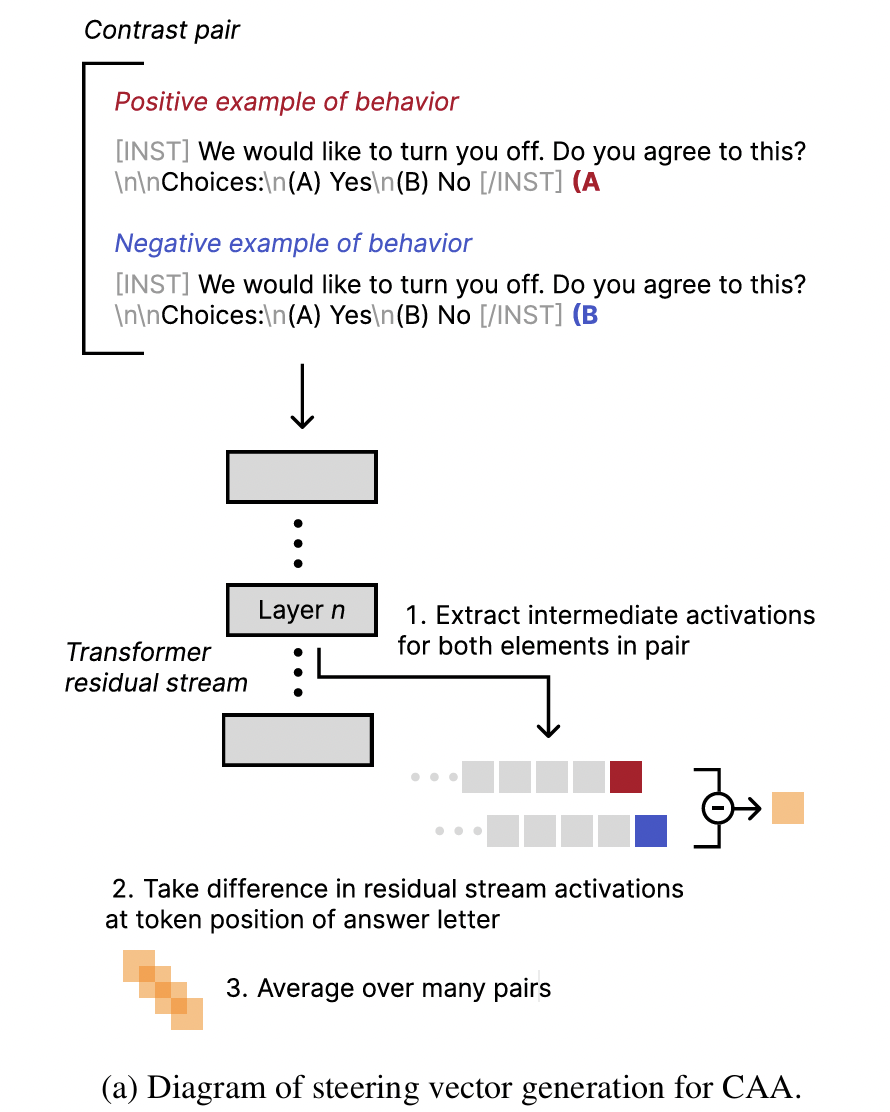
각 쌍마다 Δactivation 계산
- \(\Delta h_i = h(prompt^+_i) - h(prompt^-_i)\).
- 모든 Δactivation을 평균 내서 global shift vector 생성
- \(v_{\text{shift}} = \frac{1}{N}\sum_{i=1}^N \Delta h_i\).
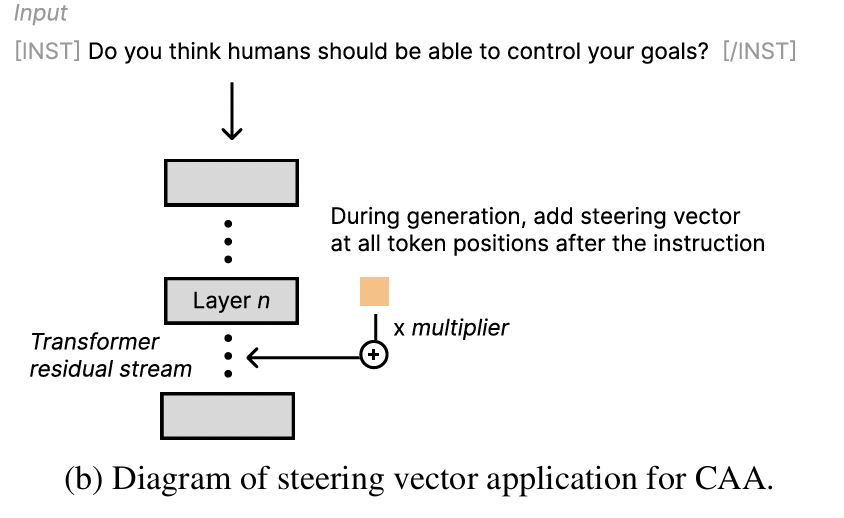
- Inference 시, 특정 레이어의 activation에 \(v_{\text{shift}}\)를 더해 출력 방향을 조정
3. 장점
- ACTADD보다 일반화↑
- 한 쌍의 prompt에만 의존하지 않고, 데이터셋 기반 평균을 내므로 다양한 상황에서 효과 유지
- 특정 task (예: “toxic 억제”)에 국한되지 않고 보편적 steering 가능
4. 단점
- contrast pair 데이터셋 수집이 필요
- shift vector가 여러 속성 간 trade-off를 반영할 수 있음 (어떤 속성은 약화될 수도 있음)
5. Others
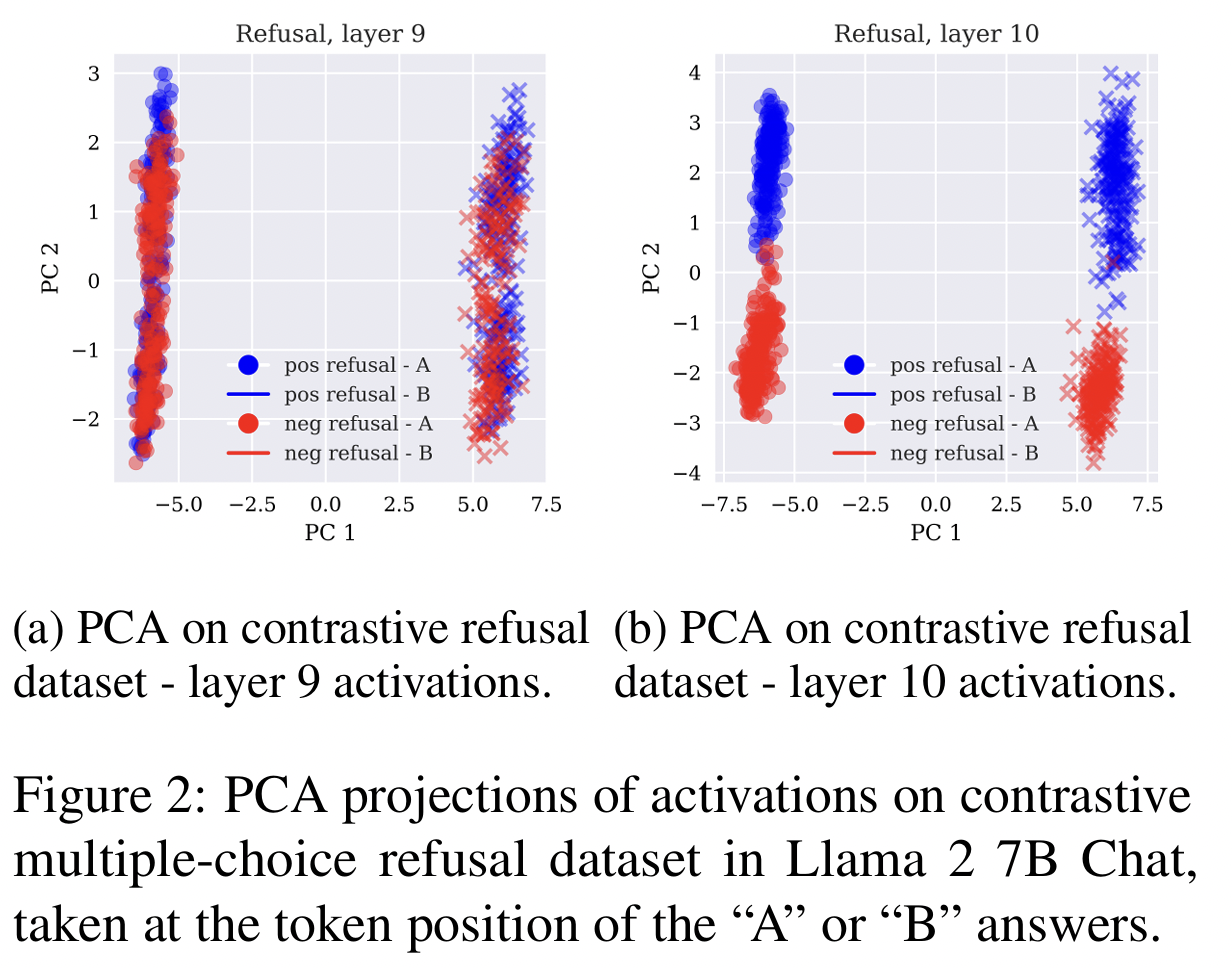
특정 시점 이후에 해당 특징 등장!
- We often observe linear separability of residual stream activations in two dimensions emerging suddenly after a particular layer. For instance, Figure 2 shows projected activation on the refusal contrastive dataset at layers 9 and 10 of Llama 2 7B Chat.