
KumoRFM: A Foundation Model for ICL on Relational Data
Fey, Matthias, et al. "KumoRFM: A Foundation Model for ICL on Relational Data."
arxiv: https://kumo.ai/research/kumo_relational_foundation_model.pdf
Contents
Abstract
Relational Foundation Model (RFM)
-
Pre-trained model capable of making accurate predictions over …
any relational DB & any predictive task!!
-
w/o requiring any data- or task-specific training
KumoRFM
- Extends ICL to the “multi-table relational graph” setting
- Employs a “table agnostic” encoding scheme
- Employs a novel Relational Graph Transformer to reason within arbitrary multi-modal data across tables
Results
- Accurate predictions within one second
- Eliminates the need for labor-intensive model development
-
Scalable and explainable AI on enterprise data
- Available at https://kumo.ai.
1. Introduction
Background: No foundation model designed specifically for “enterprise data”
Enterprise data
- Typcally stored in structured relational DB
- tables in data warehouses. Examples of such data are e.g.,
Foundation model for relational DB
$\rightarrow$ Substantial challenges, due toheterogeneous database schemas
Open questions:
- What should such a foundation model for relational data be capable of?
- * Will it be able to generalize to new databases and tasks, even the ones it was never trained on?*
- Could it provide accurate predictions from a few in-context examples?
- How does the neural network architecture look like?
- How should such a model be trained?
- * What data shall one use to train it?*
- How can one efficiently apply it in real-time?
Relational Foundation Model (KumoRFM)
First foundation model designed specifically for “enterprise relational data”
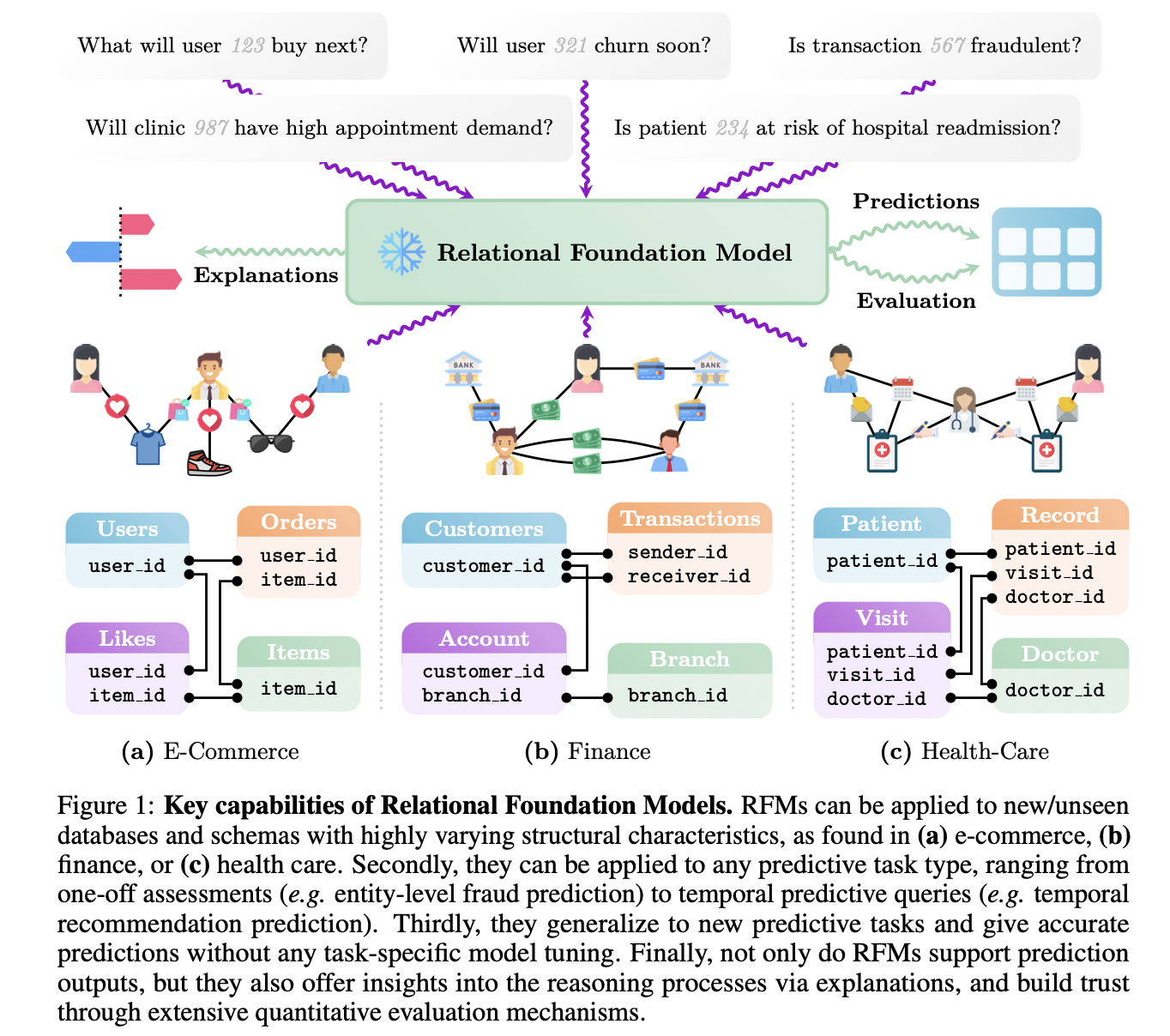
[Several key advanced capabilities]
(1) Adapt to database schemas unseen during its training phase
- Accommodate diverse structural characteristics
- e.g. Varying numbers of tables & Different types of relationships (one-to-many, many-to-many)
- Handle a wide range of column types effectively
- e.g., columns that are proprietary or opaque
(2) Adapts to a spectrum of tasks specified at inference time
- via a unified prompting interface
- i.e., Able to perform them even for tasks it was never explicitly trained for
- e.g., Handle complex predictive tasks such as temporal forecasting
(3) Mechanisms for explainability
KumoRFM Overview
- [Model] Built on a Transformer
- [Pretraining] Learn and reason across multiple tables of structured data
-
[Inference] In less than one second
-
[Result] Comparable to SoTA supervised deep learning models.
(+ Can be further fine-tuned to a specific task )
Relational DL
KumoRFM is built on the principles of Relational DL!
-
Represents relational data as a “temporal heterogeneous graph”
- Node = Entity
- Edges = Primary-foreign key links between entities
-
Table-wise attention mechanisms (feat. Relational Graph Transformer)
- Operates on the local subgraph centered around the entity of interest (=seed node)
-
“Table-invariant” feature representation
$\rightarrow$ Enables transfer across tables
Predictive Query Language (PQL): Prompting KumoRFM
Declarative mechanism for prompting KumoRFM.
- SQL-like syntax to define predictive modeling tasks
- Structured to specify …
- (1) Target variable
- (2) Entity for which predictions are made
- (3) Optional filters (to refine the dataset)
- Supports various predictive tasks
- e.g., regression, classification …
KumoRFM
-
Utilizes ICL $\rightarrow$ Enable it to generalize to previously unseen tasks
-
Executes a given Predictive Query with a powerful real-time in-context label generator that dynamically produces task-specific context labels for any given entity by leveraging temporal neighbor sampling (Wang et al., 2021; Fey et al., 2024).
-
This mechanism is used both to construct input subgraphs and to derive in-context labels in a time-consistent manner.
-
ICL is then applied in two complementary ways:
- (1) within the subgraph of an entity by attending to its own historical labels as well as those of its entities nearby
- (2) across sampled subgraphs, using subgraph-wise attention to capture broader contextual patterns.
$\rightarrow$ This dual mechanism not only reduces the number of context examples required, but also prioritizes context that is more relevant according to temporal and relational proximity.
-
Lastly, KumoRFM incorporates explainability at both the global data level and the individual entity level (Simonyan et al., 2013; Sundararajan, 2024; Ying et al., 2019). For any prediction, users can examine the features and columns most relevant to the prediction and assess the importance of individual nodes and edges within the subgraph of the entity.
Evaluation
We evaluate KumoRFM on 30 different predictive tasks coming from 7 diverse publicly available datasets in RELBENCH (Robinson et al., 2024). RELBENCH is a benchmark for Relational Deep Learning that comprises a wide range of relational databases and tasks. Importantly, KumoRFM was never trained nor tuned on any of the datasets or predictive tasks included in RELBENCH. Results show that across 30 tasks from 7 datasets, on average, KumoRFM outperforms both the de-facto gold-standard of feature engineering as well as end-to-end supervised deep learning approaches by 2% to 8% across three different task types. When fine-tuned on a specific task, KumoRFM can improve its performance further by 10% to 30% on average. Most importantly, KumoRFM is orders of magnitude faster than conventional approaches that rely on supervised training, and provides a zero-code solution to query any entity and any target at any future point in time.
2. Overview of KumoRFM
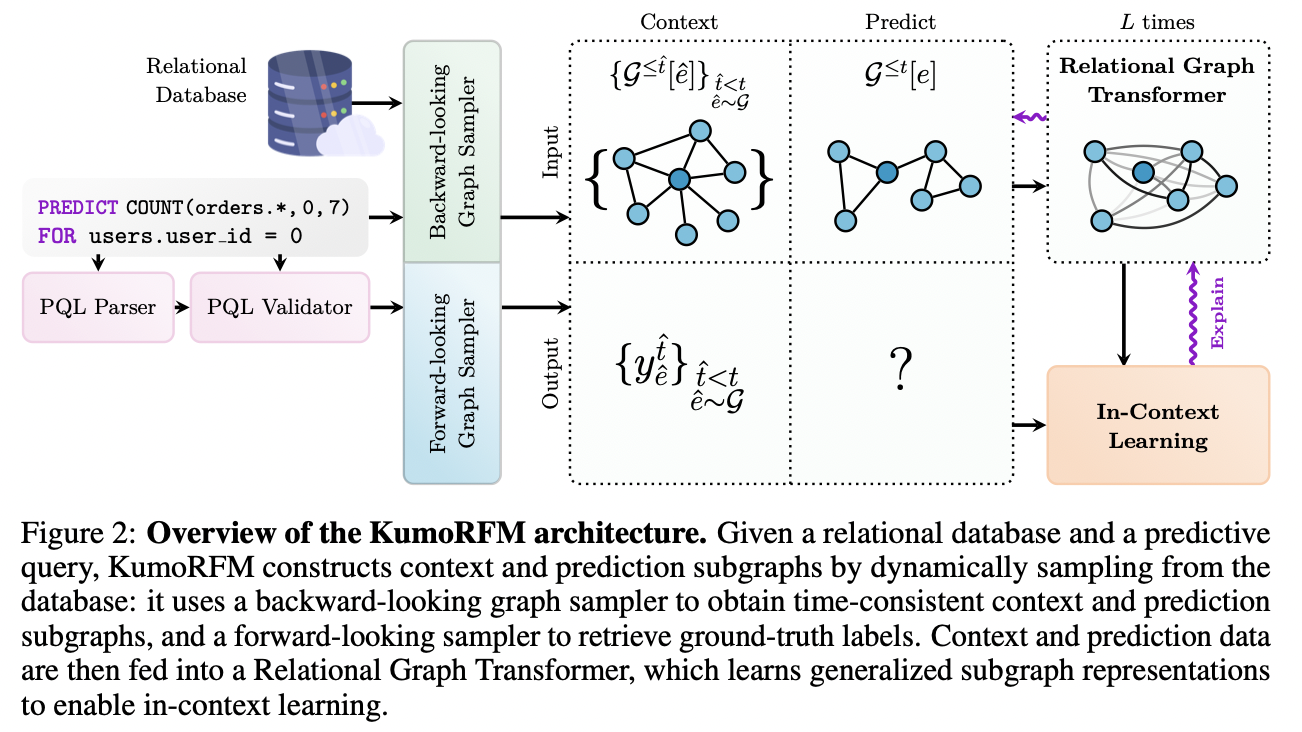
KumoRFM is the first system to offer accurate, explainable, and trustworthy predictions on any database and any predictive task, all without any task/dataset-specific training or tuning. At the core of KumoRFM is the Predictive Query Language (PQL), an expressive declarative language for specifying predictive tasks (Sec. 2.1). With this, users can effectively “talk to their data”2, issuing high-level queries for tasks such as forecasting or recommendation, and instantly receiving predictions, explanations and quantitative evaluation metrics. Explanations are available at fine-grained analytical and textual summary levels. The quantitative prediction accuracy evaluation process enables users to build confidence in the model’s predictions through both performance-centric and behavioral metrics.
Fig. 2 highlights the inter-play of the different building blocks into a unified system. KumoRFM is a running system connected to a per-enterprise specific relational database which stores its structured data (e.g., product catalogs, transaction records, customer data, supply chain data). KumoRFM internally represents such data as a temporal, heterogeneous graph G(Fey et al., 2024). Based on this representation, KumoRFM has the capability to seamlessly traverse through the graph in real-time, and query or sample subgraphs around a given entity e (e.g. a customer or product) at any specific point in time t. This sampling approach allows (recursive) access to neighbors (e.g., orders attached to a user or item) in constant time and is highly customizable: it allows for specifying the number of hops, tables, and metapaths to sample based on different temporal sampling strategies (e.g., uniform, most recent, fixed time interval), and can be adaptive (i.e., up to a certain node budget) to allow for maximally sized subgraphs even in cold start scenarios.
Once a predictive query is issued, it gets parsed, validated and transformed into an abstract syntax tree. Such a predictive query unambiguously defines the task type (node-level prediction vs. link-level prediction) and query type (one-off assessment vs. temporal prediction) (Sec.~\ref{sec:2.1}).
KumoRFM then builds upon the principles of ICL, and connects it to the Relational Deep Learning setting. That is, given an entity e and a timestamp $t$, we sample the $k$-hop subgraph $\mathcal{G}^{\leq t}_k[e] \subseteq \mathcal{G}$ around entity e up to timestamp $t$, and use it as input to make a prediction \tilde{y}_e^{(t)} according to the user-defined predictive query.
In the conventional RDL setup, such a model is trained from scratch using offline-generated historical labels y_{\hat{e}}^{\hat{t}}, where \hat{t} < $t$, \hat{e} \sim \mathcal{G}, for supervision. However, in the ICL setup, these historical labels are instead prompted during prediction time to a pre-trained but frozen KumoRFM:
$\tilde{y}e^{(t)} = \text{KumoRFM}\theta^{\text{freeze}} \left( \mathcal{G}^{\leq t}k[e],\ \left{ \left(\mathcal{G}^{\leq \hat{t}}_k[\hat{e}],\ y{\hat{e}}^{\hat{t}} \right) \right}_{\hat{e} \sim \mathcal{G}, \hat{t} < t} \right)$.
- $\hat{t}$ & $\hat{e}$: Randomly sampled timestamps and entity nodes, respectively.
This approach fundamentally departs from conventional supervised learning where model parameters \theta are trained for a specific dataset and task, with the final model being applied to unseen examples at inference time. Instead, KumoRFM is pre-trained to reason about the non-linear dependency between (subgraph, label) pairs in a single forward pass to derive a prediction for a test subgraph, and thus can naturally generalize to unseen datasets and tasks.
Importantly, to accommodate for real-time use-cases, all required input data (i.e., the entity subgraph, context subgraphs and their labels) are generated and combined on-the-fly (Sec.~\ref{sec:2.2}).