
ChatTime: A Unified Multimodal Time Series Foundation Model Bridging Numerical and Textual Data
Abstract
ChatTime (Multimodal TS foundation model)
- Model TS as a “foreign language”
- Unified framework for “TS & text” processing
- Provides zero-shot forecasting capability
- Supports “bimodal” input/output (for both TS & text)
Code: https://github.com/ForestsKing/ChatTime.
1. Introduction
(1) Previous Works
a) Extensive TS data to construct TSFMs
-
Handle the forecasting task across any scenario with a “single model”
-
Limitation) Training-from-scratch strategy
\(\rightarrow\) Inefficient & Forfeits the ability to process textual information
b) Integrate the weights of pre-trained LLMs into a new TS forecasting framework
-
Fine-tune additional input and output layers
-
Limitation)
-
Incapable of zero-shot learning and require re-fine-tuning for each dataset
-
Inability to output text
\(\rightarrow\) TS QA & Summarization (X)
-
Question) Is it possible construct a
- (1) multimodal TSFM
- (2) that allows for zero-shot inference
- (3) and supports both TS and textual bimodal inputs and outputs?
LLM & TS Model
-
(1) LLM: Predicting the next word
-
(2) TS model: Predicting the next value
\(\rightarrow\) Fundamentally model the sequential structure of historical data to predict future patterns
Proposal: ChatTime
Conceptualize TS as a foreign language!
-
Converts “continuous” TS into a (finite set of) “discrete” values
- Through normalization & discretization
-
Characterizes them as “foreign language words”
-
By adding mark characters (####)
-
By using the same methodology as vocabulary expansion
\(\rightarrow\) Eliminate the need to train from scratch or alter the model architecture
-
-
Training:
- (1) Continuous pre-training
- (2) Instruction fine-tuning
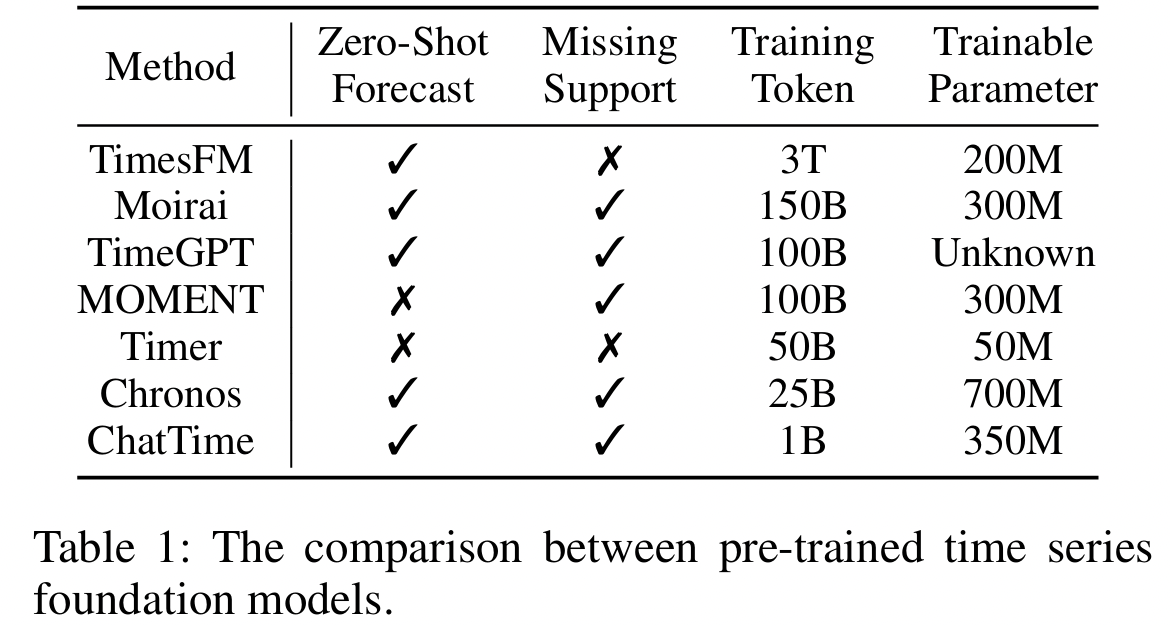
Comparison with other TSFMs (Table 1)
- Significantly reduce the training cost
- Gain an additional inference capability to process textual information
\(\rightarrow\) Simple yet effective approach addresses a wide range of TS problems at minimal cost
Series of experiments
Design a series of experiments (including three main tasks)
- [TS to TS] Zero-shot time series forecasting (ZSTSF)
- [Text to TS] Context-guided time series forecasting (CGTSF)
- [TS to Text] Time series question answering (TSQA)
Summary
-
[ZSTSF]: 8 real-world benchmark datasets (across 4 domains)
-
[CGTSF]: Collect TS records from 3 different scenarios
-
Adding and aligning background, weather, and date information
(w/o any leakage of future information)
-
-
[TSQA]: Synthesize a variable-length QA dataset
- Covering 4 typical TS features
Main Contributions
-
(1) ChatTime
- Multimodal TS foundation model
- Conceptualize TS as a foreign language
- Allows for zero-shot inference
- Supports both time series and textual bimodal inputs and outputs
-
(2) Establish
- a) Three context-guided TSF datasets
- b) TSQA dataset
to fill gaps in related multimodal domains
-
(3) Comprehensive experiments
2. Related Work
(1) LTSF
Pass
(2) LLM-based TS Analysis
Categorized into the following three paradigms
(Based on the dependence on pre-training weights)
- (Category 1) Relies entirely on pre-trained weights
- (Category 2) Integrates pre-training weights into new frameworks
- (Category 3) Uses the architecture of pretrained LLMs but does not utilize the weights
(Category 1) Relies entirely on pre-trained weights
- Employ LLMs directly for TSF via prompts
- Limitations:
- Lack of understanding about TS features
- Have low token utilization due to the bit-by-bit tokenization
- (Instruction fine-tuning has improved accuracy in some cases, but these improvements do not address high inference costs)
(Category 2) Integrates pre-training weights into new frameworks
- Additional layers will be fine-tuned to adapt for the tTS
- E.g., Incorporate extra input and output layers
- E.g., Utilize pre-trained weights as an embedding module
- Limitation: However, most of them cannot perform zero-shot inference
(Category 3) Uses the architecture of pretrained LLMs but does not utilize the weights
- Employ vast amounts of TS data to construct new foundation models
- Limitations
- Training from scratch is highly inefficient!
- Most of them support only unimodal numerical data
3. Methodology
(1) Overview
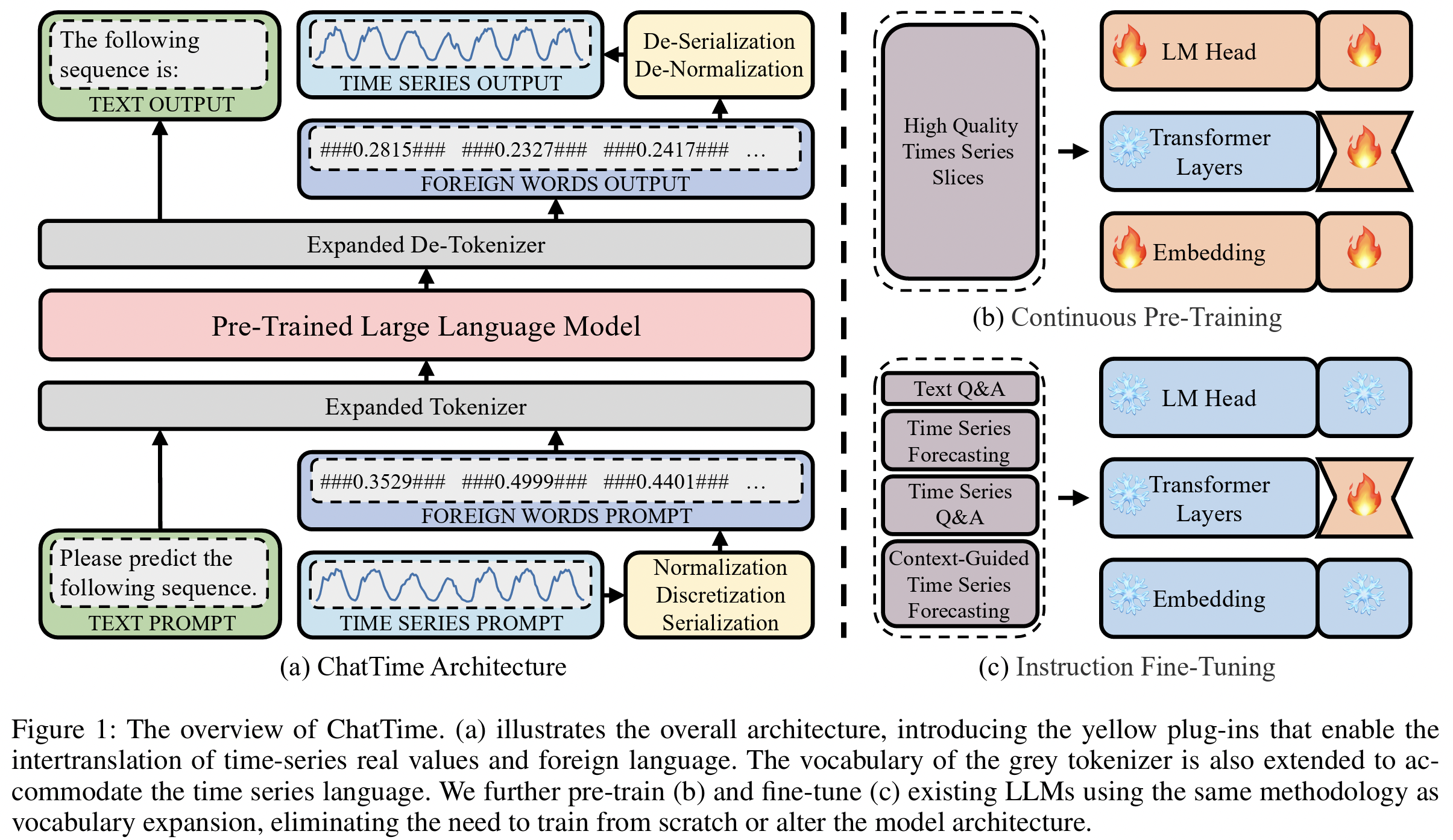
ChatTime (Figure 1-a)
- Step 1) Encodes TS into a “foreign language”
- Through a) normalization, b) discretization, and c) the incorporation of mark characters
- Step 2) Expanded tokenizer
- Transforms text and foreign words into token indexes
- Step 3) Process by the LLM
- Step 4) Detokenizer translates the token indexes back into text and foreign words
- Step 5) Foreign words are re-decoded into TS
- By removing mark characters and applying inverse normalization
Training process (Figure 1-b,c)
- (1) Continuous pre-training
- (2) Instruction fine-tuning
Both phases utilize 4-bit quantized models with LoRA
(2) Model Architecture
Conceptualizing TS as a foreign language
\(\rightarrow\) Enables pre-trained LLMs to process TS through vocabulary expansion
Two critical modifications
- (1) Introduces a yellow plug-in
- Interconversion between real values of TS and foreign language
- (2) Extends the vocabulary of grey tokenizer
- To accommodate TS language
NL vs. TS
- NL: Finite dictionary
- TS: Real-valued data within unbounded continuous domains
Notation) TS: \(x_{1:C+H} = \{x+1,...,x_{1:C+H}\}\),
- Input = \(C\) steps
- Pred = \(H\) steps
a) Min-max scaling
-
Mapping:
- Unbounded real values \(\rightarrow\) Bounded range of-1 to 1
-
\(\tilde{\mathbf{x}}_{1:C+H} = \frac{\mathbf{x}_{1:C+H} - \min(\mathbf{x}_{1:C})} {\max(\mathbf{x}_{1:C}) - \min(\mathbf{x}_{1:C})}-0.5\).
-
Scale based solely on the history
-
Note) Prediction series may surpass the range of the history series!
\(\rightarrow\) \(\therefore\) Scale the history series into the range of-0.5 to 0.5
(To reserve the remaining interval as a buffer for the prediction series)
-
b) Binning
- To quantize these (scaled) real values into discrete tokens
- Uniformly partition the interval from -1 to 1 into 10K bins
c) Fix the precision
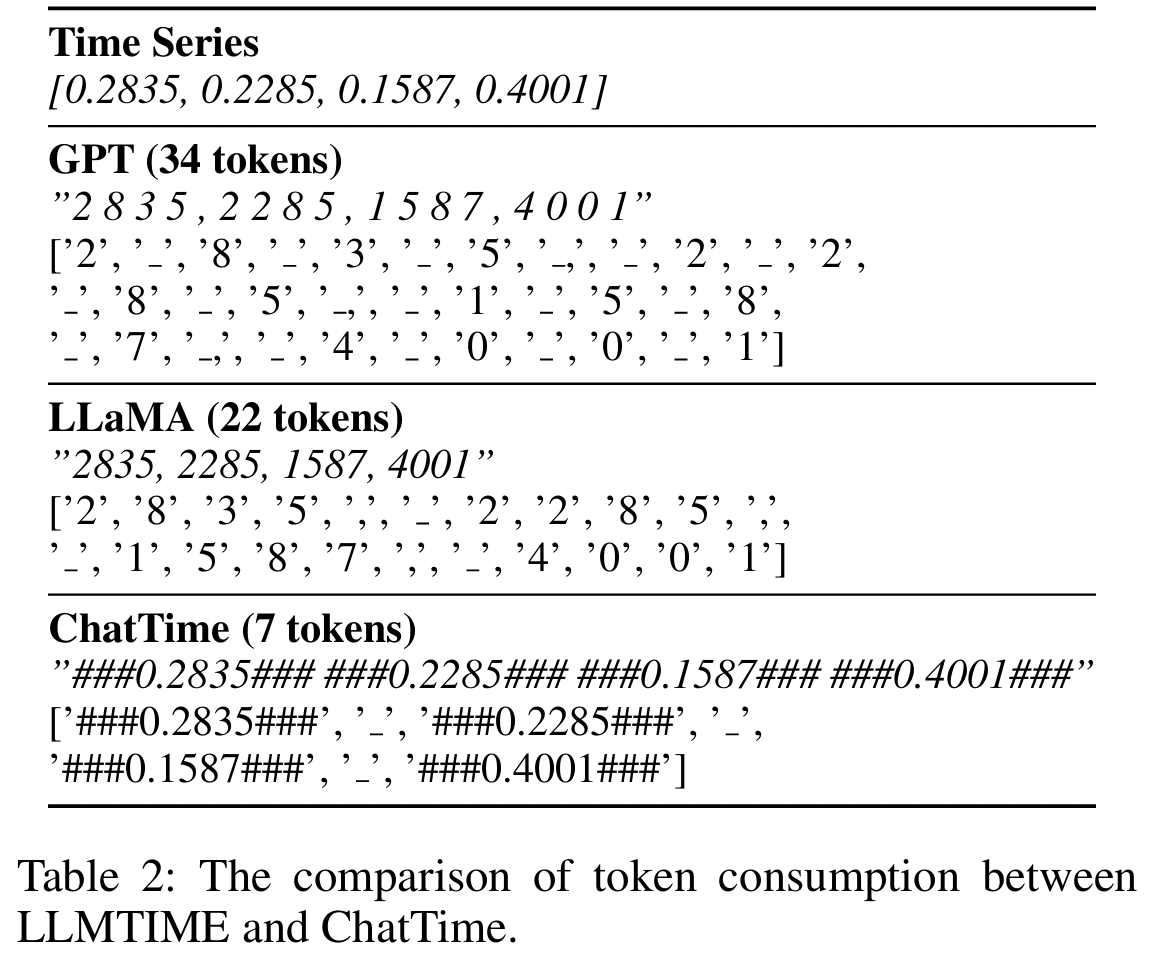
-
Fix the precision of the discretized TS to 4
- (Feat. LLMTIME (Gruver et al. 2023))
-
(Table 2) LLMTIME presents two methods for GPT and LLaMA tokenizing TS
\(\rightarrow\) Consumes a substantial number of tokens, leading to large computational costs!
-
Proposal: Mark characters ”###” at the beginning and end of the discretized TS
\(\rightarrow\) By extending the vocabulary of the tokenizer, only one token is needed for each value, regardless of its precision.
\(\rightarrow\) Also include an additional ”###Nan###” to manage missing values.
(3) Continuous Pre-Training
Continuous Pre-Training
= Frequently employed to enhance the comprehension of LLMs in specialized domains
\(\rightarrow\) Grasping the “fundamental principles of TS” is essential!!
Details (Figure 1-b)
-
1M high quality TS slices are used to pre-train “LLaMA-2-7B-Base”
\(\rightarrow\) Resulting in “ChatTime-1-7B-Base”
-
Pretraining task: Autoregressive forecasting on extensive TS data
-
Training layers
-
**(1) Embedding layer & Output header **
(\(\because\) vocabulary of the tokenizer is expanded )
-
(2) LoRA of Transformer layer
-
Dataset
Sourced from two extensive open-source TS repositories
- Monash (Godahewa et al. 2021)
- TFB (Qiu et al. 2024)
\(\rightarrow\) Approximately 100 sub-datasets
- (11 subdatasets for evaluating ZSTSF and CGTSF tasks have been excluded to prevent information leakage)
Pretraining task
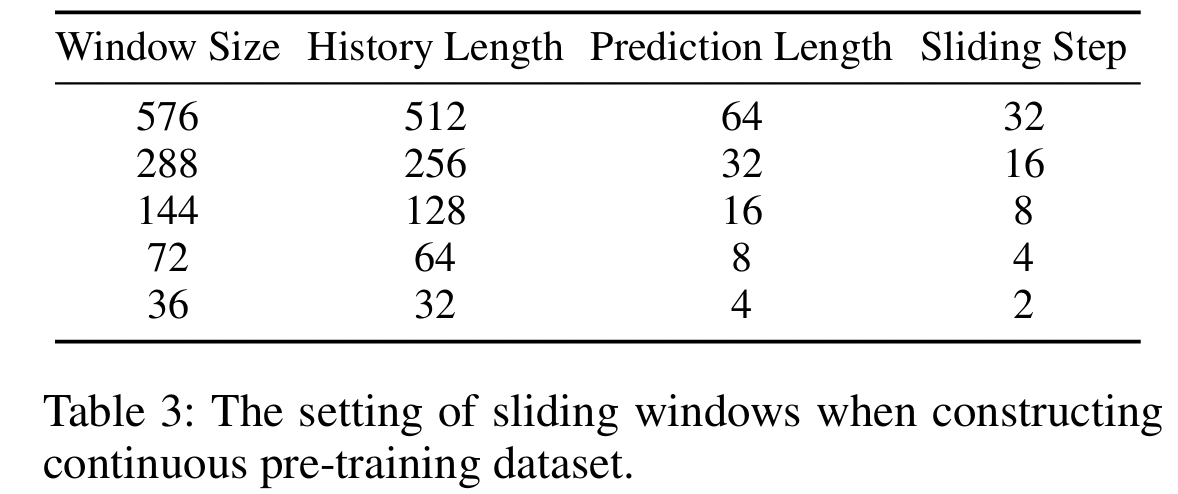
“Autoregressive forecasting” strategy
- To support “arbitraty” (history and prediction) window sizes
- Apply sliding slices to the original TS
- Using 5 distinct window and step sizes (Table 3)
- Prioritize slicing the original TS into larger segments
Details
- Given the numerous repeating patterns and the limited computational resources ..
- Step 1) Perform K-means on 10M original TS slices
- Step 2) Categorize them into 1M and 25K groups
- Randomly selecting one sample from each group to serve as a representative.
- For continuous pre-training (1M)
- For instruction fine-tuning (25K)
(4) Instruction Fine-Tuning
Fine-tune ChatTime-1-7B-Base
\(\rightarrow\) Resulting in ChatTime-1-7B-Chat
(Only fine-tune the LoRA of Transformer layer)
Four task datasets
- (1) Text Q&A
- (2) TSF
- (3) TS Q&A
-
(4) CGTSF
- 25K samples are extracted for each task
(1) Text Q&A
- To retain the textual inference capabilities of the LLMs
- Randomly select 25K samples from the widely used Alpaca dataset for this task
(2) TSF
- Unimodal TSF
- Utilize 25K high quality TS slices (Sec 3.3)
(3) TS Q&A & (4) CGTSF
- (Involve the interconversion of TS & Text, but related datasets are lacking)
- Collect three CGTSF datasets and synthesize a TSQA dataset to address this gap
a) CGTSF
Supported by three multimodal datasets
- Melbourne Solar Power Generation (MSPG)
- London Electricity Usage (LEU)
- Paris Traffic Flow (PTF)
Details (Appendix B.2)
-
Only “background, weather, and date” are included as textual auxiliary information
\(\rightarrow\) To prevent future information leakage
- Chronologically split into training, validation, and test sets with a ratio of 6:2:2
- A sample of 25K data points is randomly selected from the training sets of these three datasets.
b) TS Q&A
Employ the KernelSynth to generate a variable length multimodal QA dataset
- Based on four generic typical TS features
Details (Appendix B.3)
- Randomly select 25K data entries from this dataset
4. Experiments
(1) Implementation Setting
Training process
- (1) Continuous pre-training
- (2) Instruction fine-tuning
Common
-
4-bit quantized models with LoRA (i.e., QLoRA)
- Rank = 8, alpha = 16
-
Batch size is 8 with a gradient accumulation of 32
-> Resulting in a global batch size of 256
Epochs
-
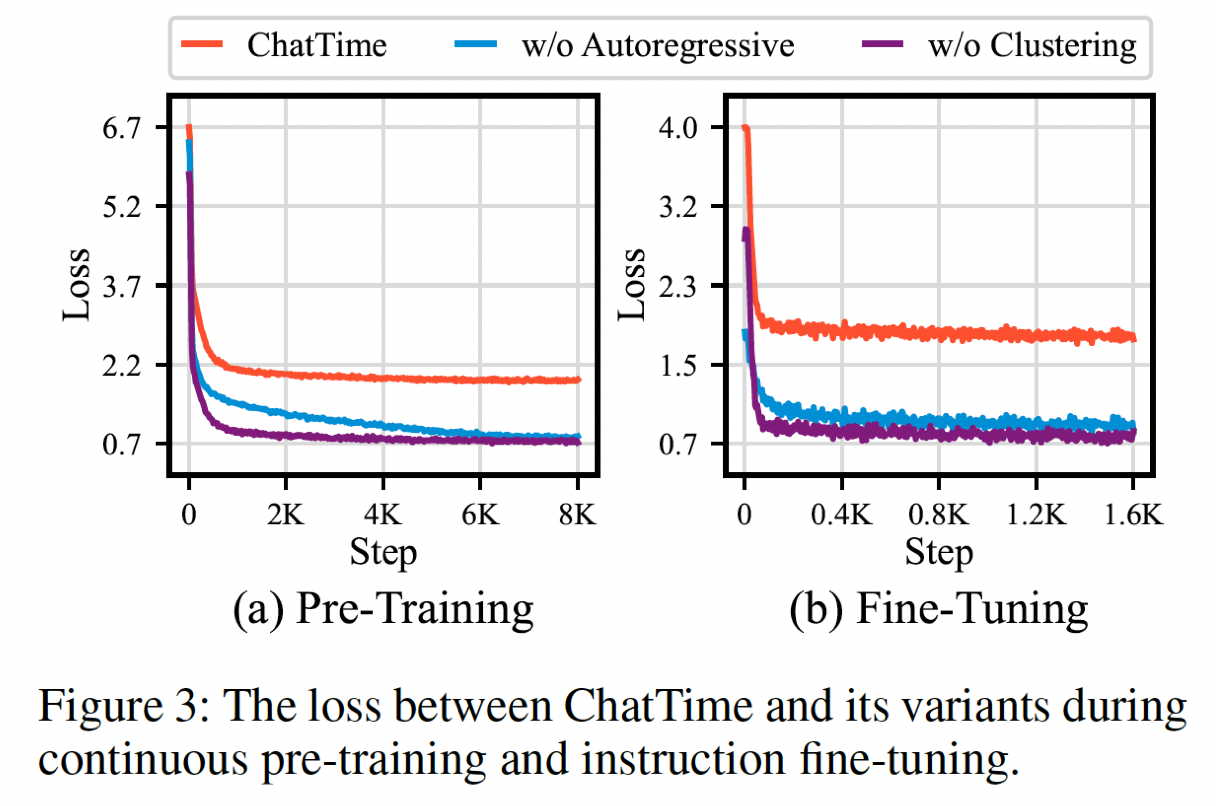
(1) Pretraining = 2 (8K steps) … loss graph: Figure 3(a)
-
(2) fine-tuning = 4 (1.6K steps) … loss graph: Figure 3(b)
Prompt templates for ChatTime



(2) Zero-shot TSF
Unimodal TSF
Dataset: from four domains
-
Electric, Exchange, Traffic, Weather
-
Excluded these datasets during the training
(\(\because\) Information leakage)
-
Train:Val:Test = 6:2;2
Determine a priori period of each dataset based on its collection granularity and use it as the prediction length
History length = {2,3,4,5} times the prediction length
\(\rightarrow\) Ensure that the history window of the zero-shot models contains at least two complete periods
Metric: MAE
Baselines (2groups)
- (1) Single-task models
- Models trained and predicted on a single dataset with fixed history and prediction lengths
- E.g., DLinear, iTransformer, GPT4TS, TimeLLM
- GPT4TS & TimeLLM: Utilize pretrained LLMs as their backbone
- (2) TSFMs
- Capable of zero-shot TSF
- E.g., TimeGPT, Moirai, TimesFM, Chronos
- For the foundational models available in different sizes, we use their most powerful versions
- All baselines are evaluated based on our runs using the same hardware as ChatTime, except for the closed-source model TimeGPT, which requires official API calls.
- We use official implementations from GitHub and follow the hyperparameter configurations recommended in their papers.
Results
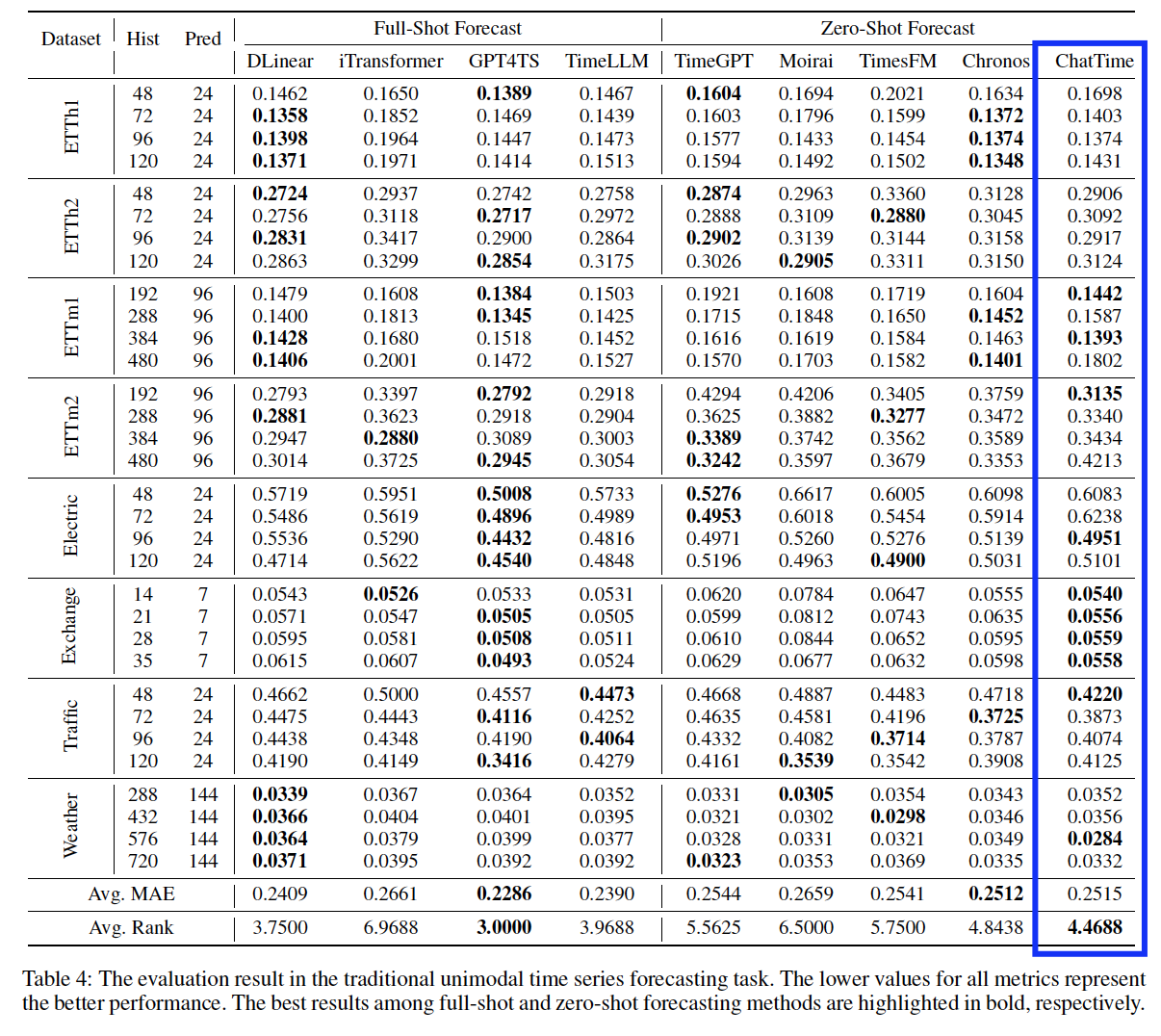
-
To avoid a few datasets dominating the results, we primarily compare the average MAE (the lower, the better) and the average Rank (the smaller, the better) across eight datasets
-
Results Summary
-
[vs. TSFM] By fine-tuning an existing pre-trained LLM instead of training it from scratch…
\(\rightarrow\) Achieves 99.9% of the zero-shot prediction accuracy of the previous SOTA method (Chronos) using only 4% of the data.
-
[vs. Single-task] Attains 90.9% of the prediction accuracy of the previous SOTA method (GPT4TS)
-
-
Although introducing LLMs brings some performance gains for GPT4TS and TimeLLM, they do not significantly outperform the simple linear model DLinear.
\(\rightarrow\) Validates that current unimodal methods may be approaching their saturation point
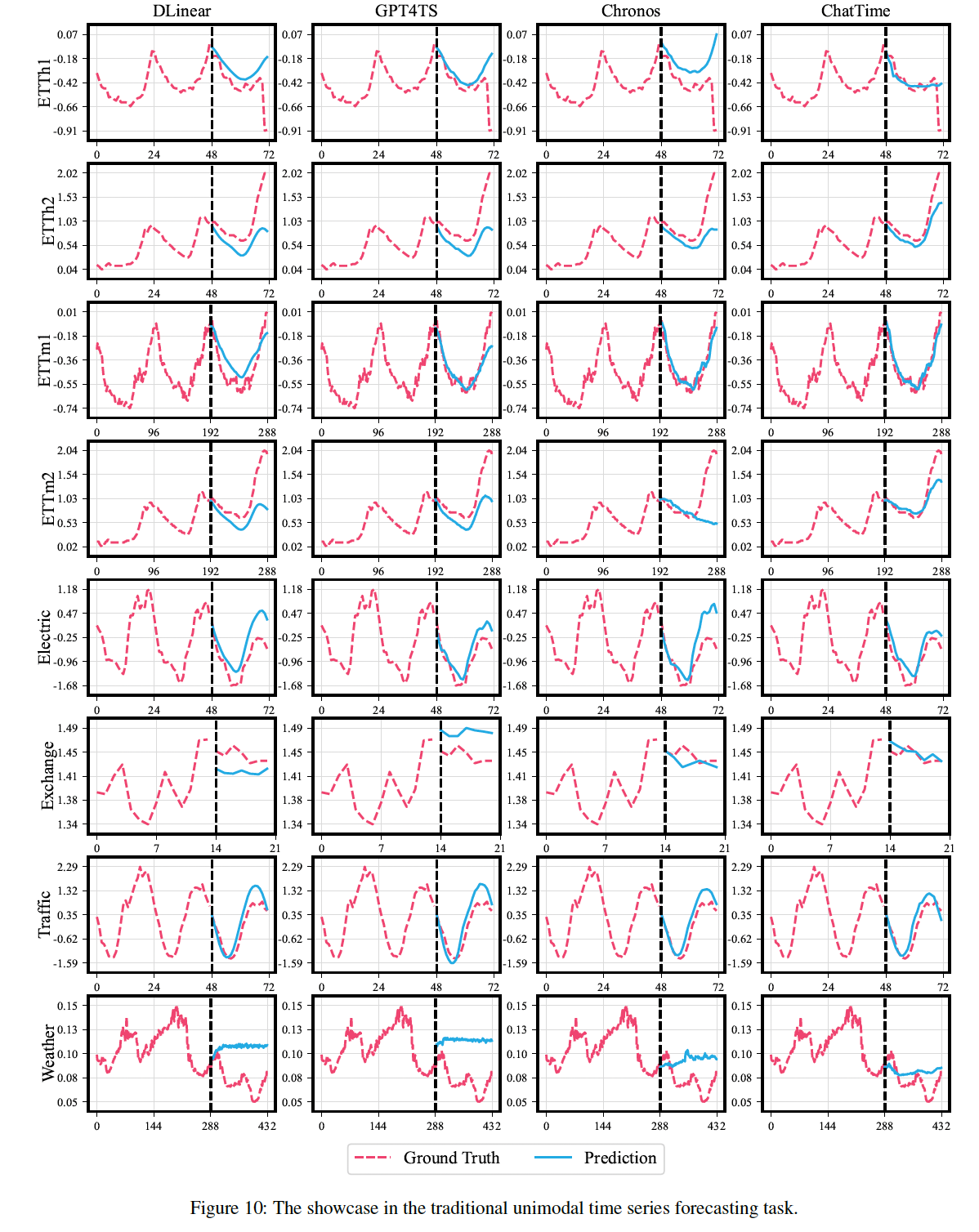
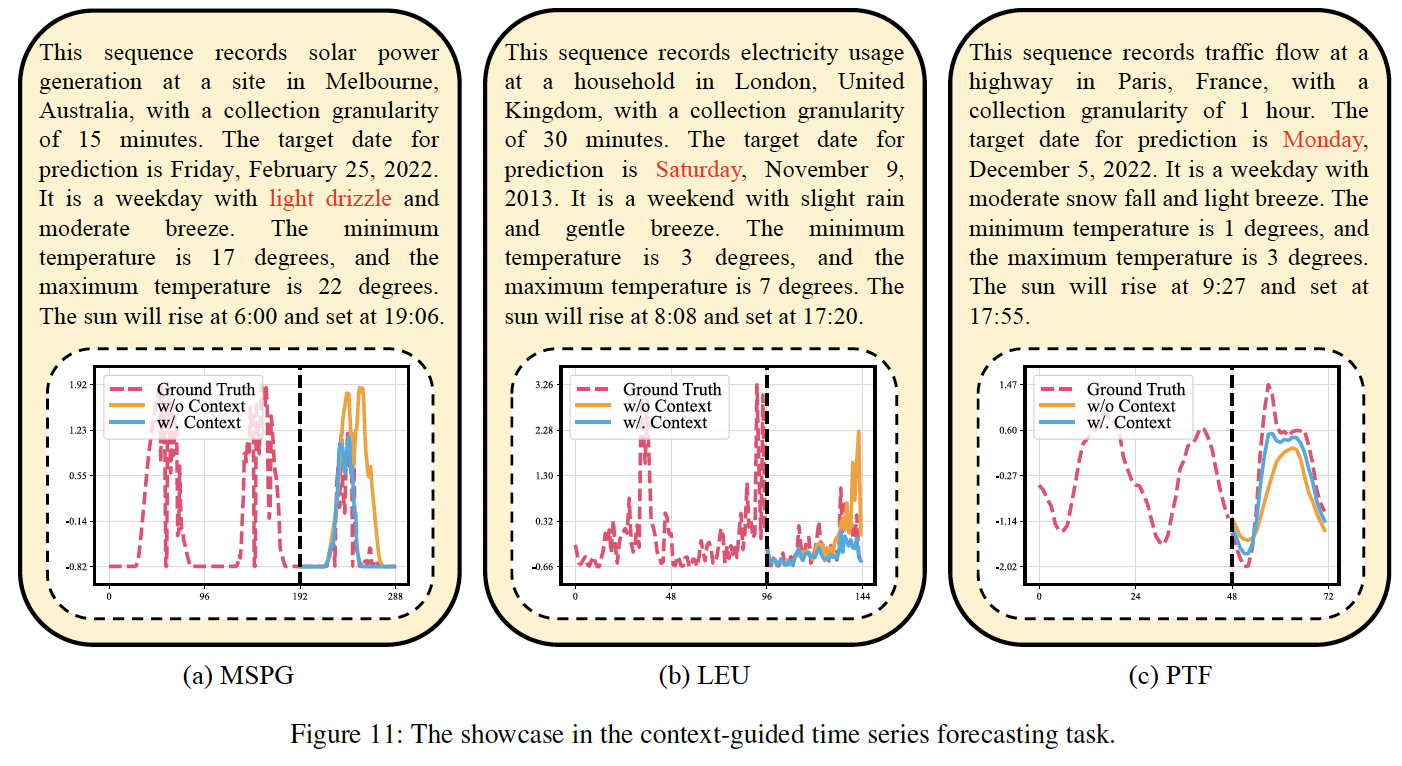
(3) Context-guided TSF
Multimodal context-guided TSF
- Dataset: Three datasets (collected in Section 3.4)
- Segment / History,pred length / Metric (Same as Section 4.2)
Due to the limited multimodal datasets…
\(\rightarrow\) Instruction fine-tuning phase is performed on partial training sets of these three datasets!
( Although this deviates from the zero-shot setup, ChatTime still does not require separate training for different scenarios but utilizes shared model weights )
Additional baseline (vs. Section 4.2)
- TGForecaster (Xu et al. 2024): Can handle textual information
- ChatTime-: Excludes textual input
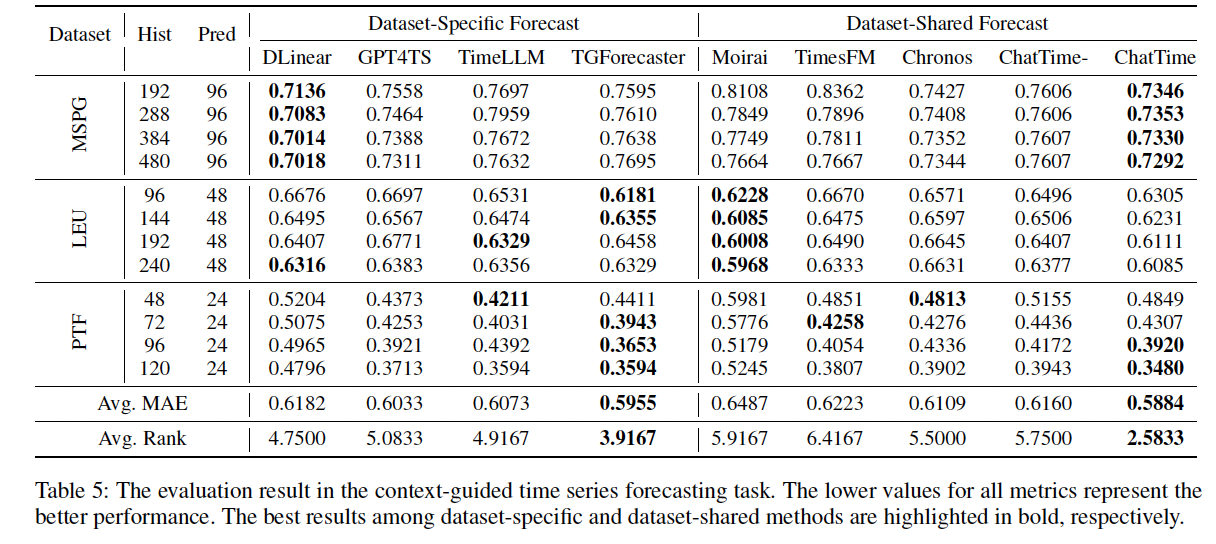
Results
-
With the incorporation of textual information…
\(\rightarrow\) TGForecaster and ChatTime exhibit superior performance!
-
ChatTime > TGForecaster
\(\rightarrow\) Owing to the synergistic integration of the two modalities
- TGForecaster: Trained independently on each dataset
-
ChatTime significantly outperforms ChatTime- using only unimodal values
\(\rightarrow\) Affirming the effectiveness of contextual assistance!
(4) TS QA
Multimodal TSQA
- Dataset: Synthesized in Section 3.4
- Exclude the 25K samples utilized for the instruction fine-tuning
- Use the remaining data as the test set
- Baselines
- Powerful generic pre-trained LLMs
- GPT4 (OpenAI 2023a), GPT3.5 (OpenAI 2023b), GLM4 (GLM 2024), and LLaMA3-70B (Meta 2024).
Input formats:
- Two prompts suggested by LLMTIME (Gruver et al. 2023)
- For GLM4, we have tested both prompts and select the format like LLaMA, which yields better results.
Baselines:
- LLaMA3: Uses API from Alibaba (Alibaba 2024)
- Remainings: Use their official API.
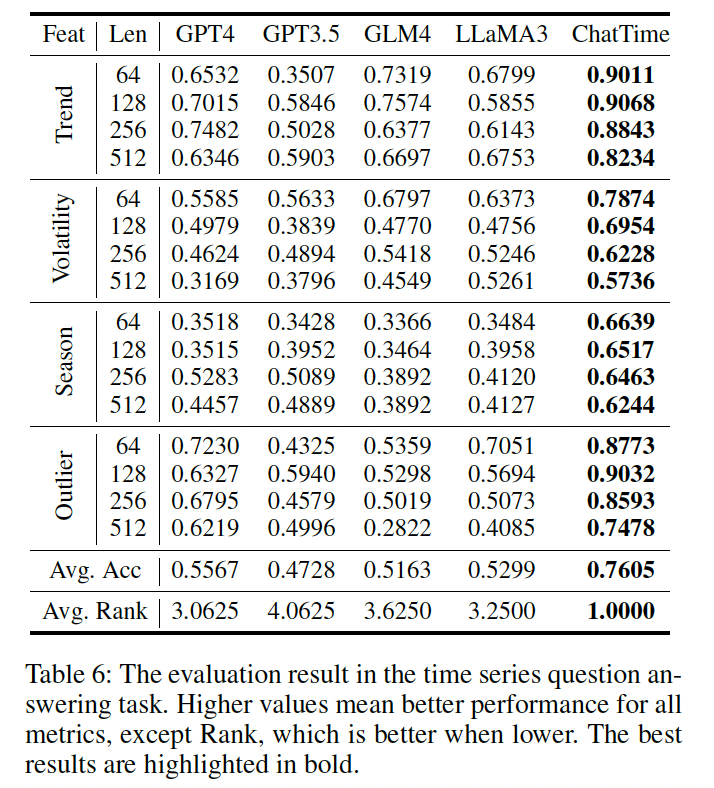
Results
- Although generic LLMs have shown impressive performance across various text tasks, their efficacy in TS comprehension remains suboptimal
- ChatTime
- Not only preserves the inference capabilities of LLMs
- But also demonstrates a superior understanding of TS features.
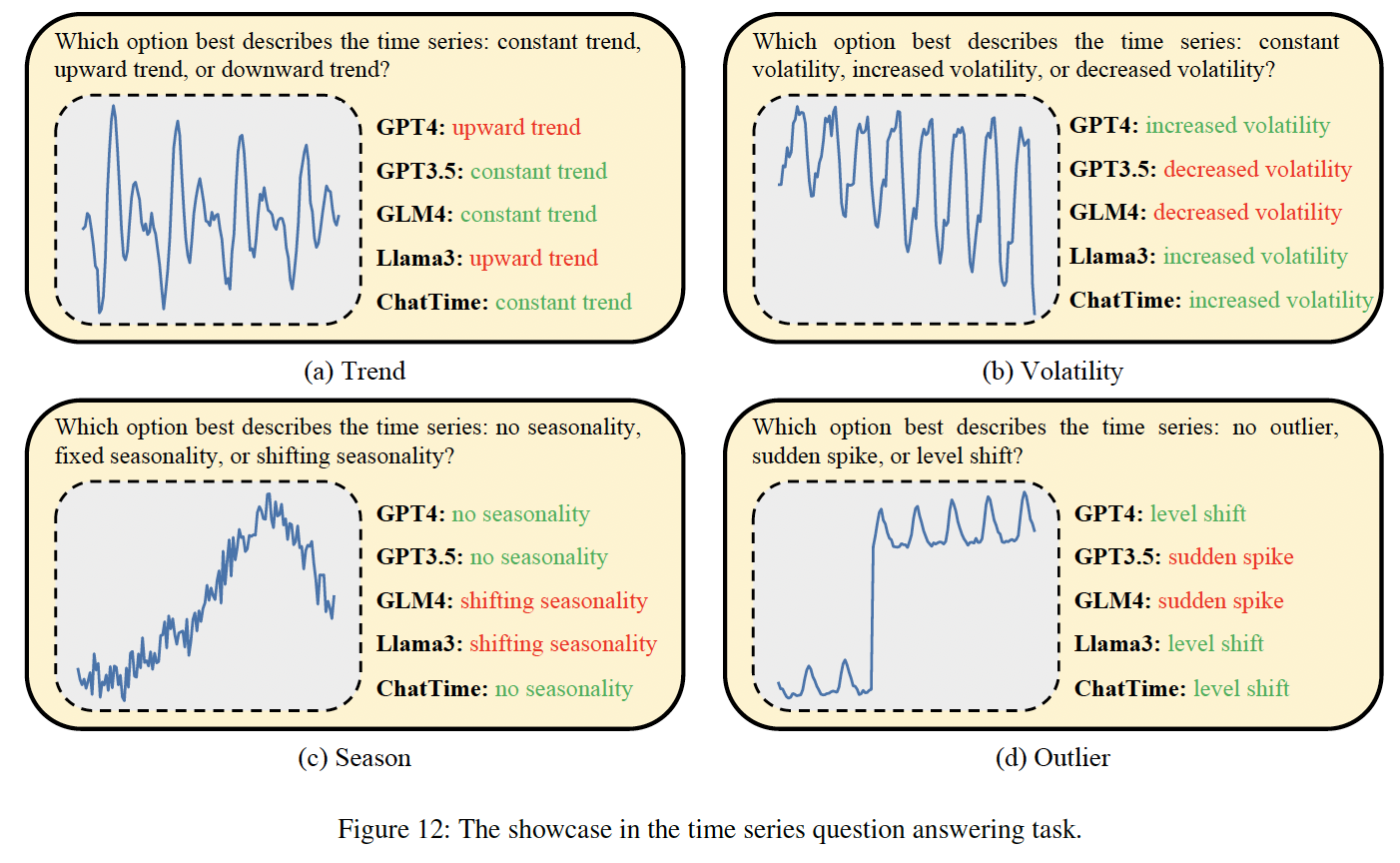
(5) Ablation Study
Ablation study
- On the aforementioned three tasks
- Report their average results across all datasets individually
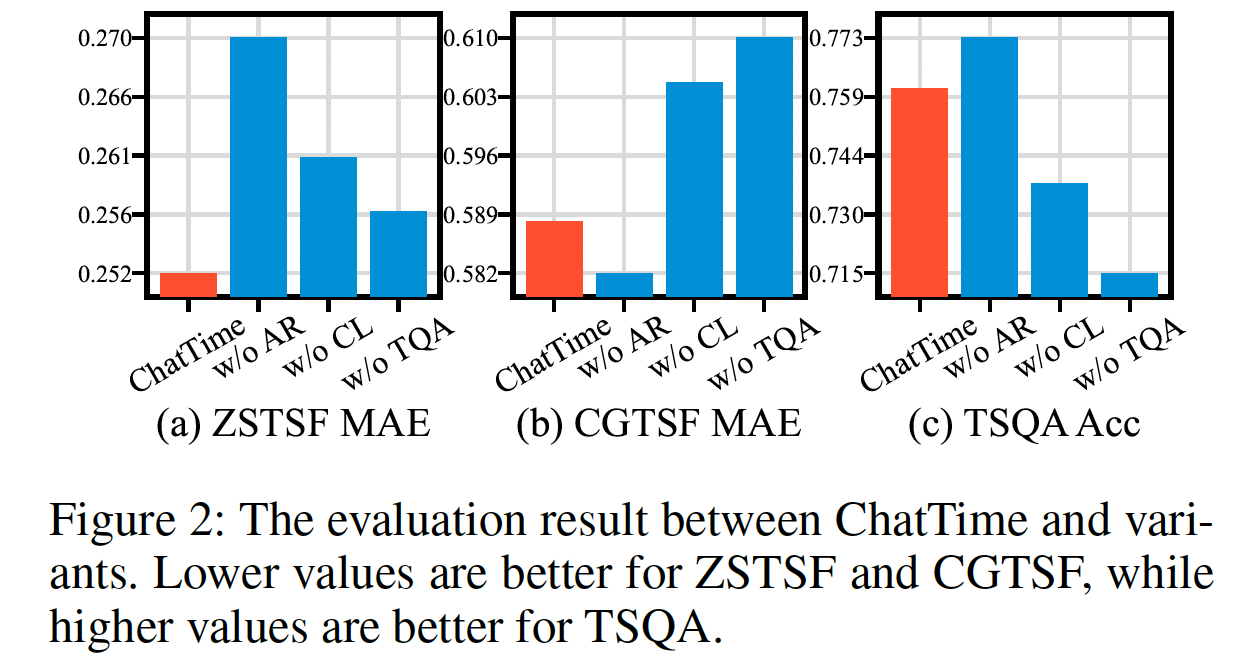
- Indispensability of autoregressive continuous pre-training (w/o AR)
- Clustering for time-series slices (w/o CL)
- Text question answering in fine-tuning instructions (w/o TQA)
a) [w/o AR]
Substitute the 1M continuous pre-training dataset with the 100K instruction fine-tuning dataset.
- Increase the epoch by ten times to maintain consistent parameter iterations
- Results
- Leads to a slight improvement in CGTSF and TSQA
- But removing the pre-training dataset causes a struggle to grasp the fundamental TS features, significantly reducing the zero-shot inference capability and practical value.
- Figure 3: Overfitting in ChatTime after replacing TS pre-training data
b) [w/o CL]
Substitute the high-quality TS slices obtained from clustering with low-quality data randomly sampled from the 10M original slices.
- Results
- Lacks sufficient comprehension of TS after replacement
- Various degradations across the three tasks.
- Figure 3: Confirms that randomly sampled data is less challenging to model, making ChatTime prone to overfitting
c) [w/o TQA]
Exclude the text QA dataset in the instruction fine-tuning
-
Results
-
Omitting this task hampers the inference capability
-
Resulting in performance degradation across all three tasks
( Particularly in the multimodal CGTSF and TSQA )
-
5. Conclusion
Efficient construction of a multimodal TSFM that
- (1) Allows for zero-shot inference
- (2) Supports both time series and textual bimodal inputs and outputs
ChatTime
-
Characterize TS as a foreign language, we
- Framework for the unified processing of time series and text
- Designed a series of experiments and constructed four multimodal datasets
Future works
- Due to resource constraints, ChatTime has not yet reached saturation.
- Plan to use more data and computational resources to further extend its applicable tasks
- Anomaly detection
- Classification
- Summarization
python run_eval_CGTSF.py --model_path /data/seunghan9613/ChatTime/output/ChatTime-1-7B-Chat-Comp2TS-25K --device cuda:3