auDeep: Unsupervised Learning of Representations from Audio with Deep RNNs ( JMLR 2017 )
https://arxiv.org/pdf/1712.04382.pdf
Contents
- Abstract
- Recurrent Seq2Seq AE
- System Overivew
- Experiments
- Three audio classification tasks
- Baselines
- Results
Abstract
auDeep
- Python toolkit for deep unsupervised representation learning from acoustic data
- architecture
- seq2seq … consider temporal dynamics
- provide an extensive CLI in addition to a Python API
code: https: //github.com/auDeep/auDeep.
SOTA in audio classification
1. Recurrent Seq2Seq AE
Extends the seq2seq (RNN enc-dec model)
- input sequence : fed to a multi-layered RNN
- final hidden state fed to FC layer
- output : fed to decoder RNN & reconstruct the input sequence
Loss : RMSE (reconstruction loss)
Details:
- for faster model convergence, the expected decoder output from the previous step is fed back as the input into the decoder RNN
- used representation : activations of the FC layer
Input data = spectrograms
- time dependent sequences of frequency vectors.
Two of the key strengths
- (1) fully UNsupervised training
- (ii) the ability to account for the temporal dynamics of sequences
3. System Overview
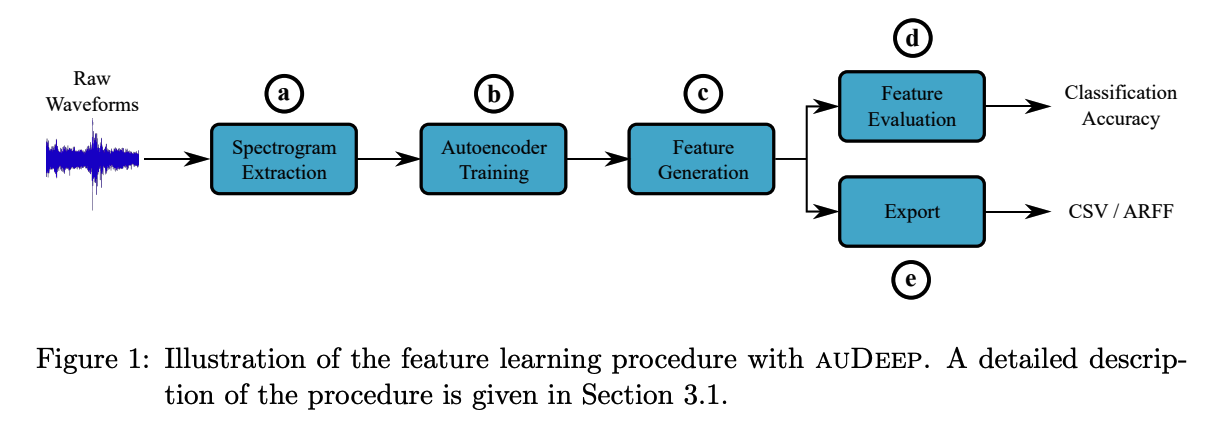
-
extracted features can be exported to CSV or ARFF for further processing
( ex. classification with alternate algorithms )
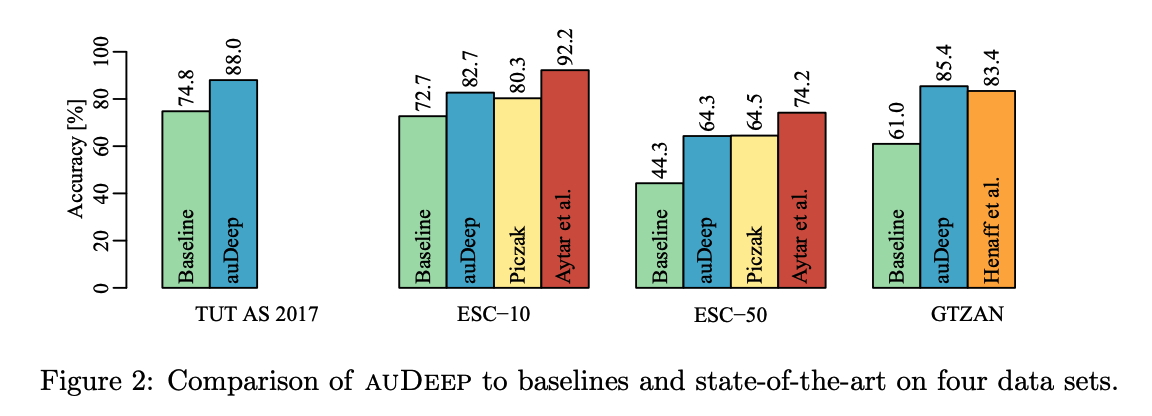
4. Experiments
(1) Three audio classification tasks.
- (1) Acoustic scene classification
- dataset : ( TUT Acoustic Scenes 2017 (TUT AS 2017) )
- (2) Environmental sound classification (ESC)
- dataset : ( ESC-10 and ESC-50 )
- (3) Music genre classification
- dataset : ( GTZAN )
Train multiple autoencoder configurations using auDeep
& Perform feature-level fusion of the learned representations.
$\rightarrow$ fused representations are evaluated using the built-in MLP with the same cross-validation setup as used for the baseline systems on the TUT AS 2017, ESC-10, and ESC-50 data sets.
(2) Baselines
(a) CNN (Piczak, 2015a)
(b) Sparse coding approach ( Henaff et al., 2011 )
(c) SoundNet system (Aytar et al., 2016)
- better than auDeep ….but not fair compairison
- auDeep was trained using ESC-10 and ESC-50 data only
- SoundNet was pre-trained on an external corpus of 2+ million videos.
(3) Results