Mixture of nested experts: Adaptive processing of visual tokens
Jain, Gagan, et al. "Mixture of nested experts: Adaptive processing of visual tokens." arXiv preprint arXiv:2407.19985 (2024).
참고:
- https://aipapersacademy.com/mixture-of-nested-experts/
- https://arxiv.org/pdf/2407.19985
Contents
- Motivation
- MoNE: Mixture of Nested Experts
- Nested Experts
- Router
- MoNE Layer Output
- MoNE Layer Details
- Experiments
1. Motivation
Is Standard MoE Enough?
Mixture-of-Experts (MoE)
- Helps to increase models size (w/o a proportional increase in computational cost)
- Limitation = **Large memory footprint
- \(\because\) Need to load all of the experts
Information redundancy in CV

Patch on the upper right
- Mostly contain background pixels
- Nonetheless, ViT ( + MoE ) allocate the same compute power to all tokens!
2. MoNE: Mixture of Nested Experts
Limitation of MoE
- (1) Large memory footprint
- (2) Information redundancy
\(\rightarrow\) Solution: Mixture of Nested Experts (MoNE)
(1) Nested Experts
Example) 3 nested experts
- With 3 different colors.
- Size
- Expert 1 (L)
- Expert 2 (M)
- Expert 3 (S)
- Each expert has different capacity (of handling tokens)
- Expert 1 > Expert 2 > Expert 3
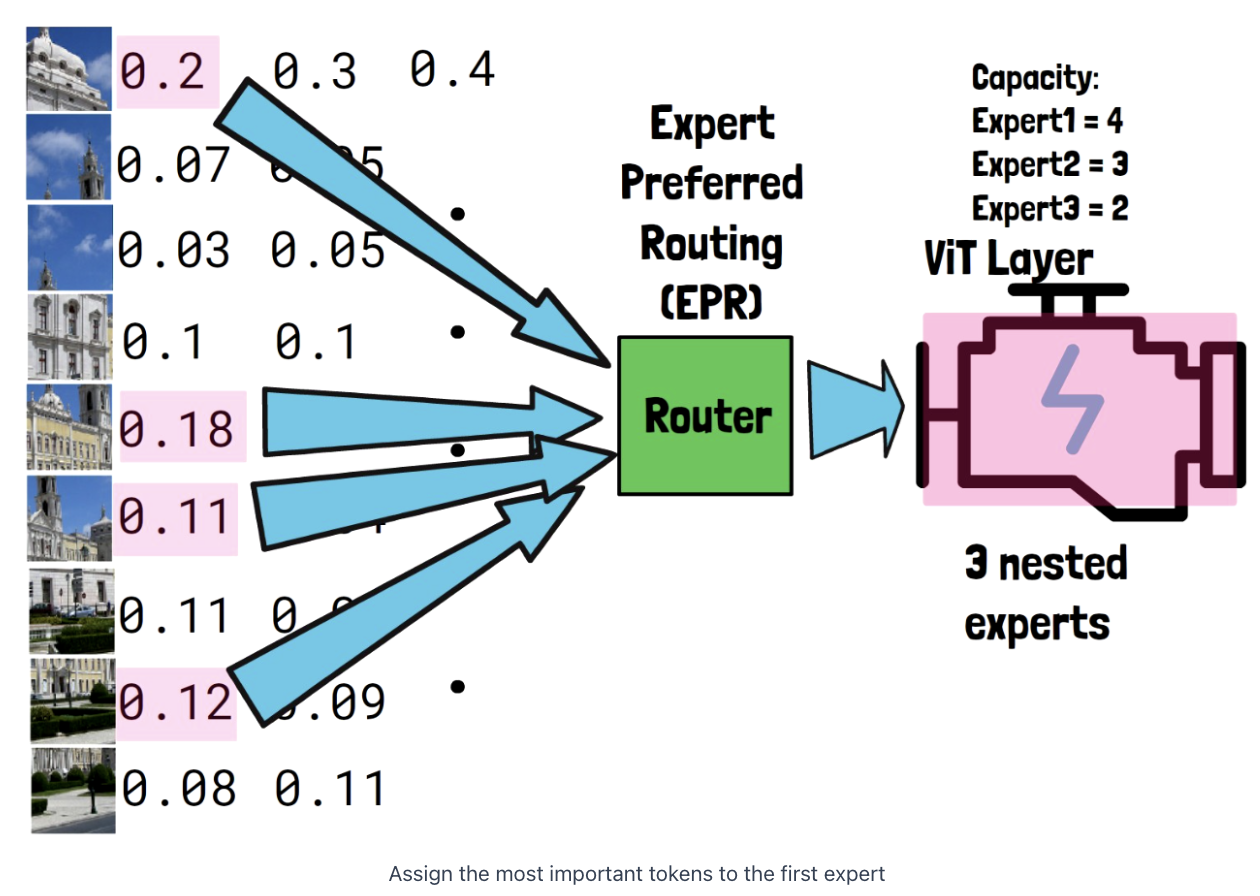
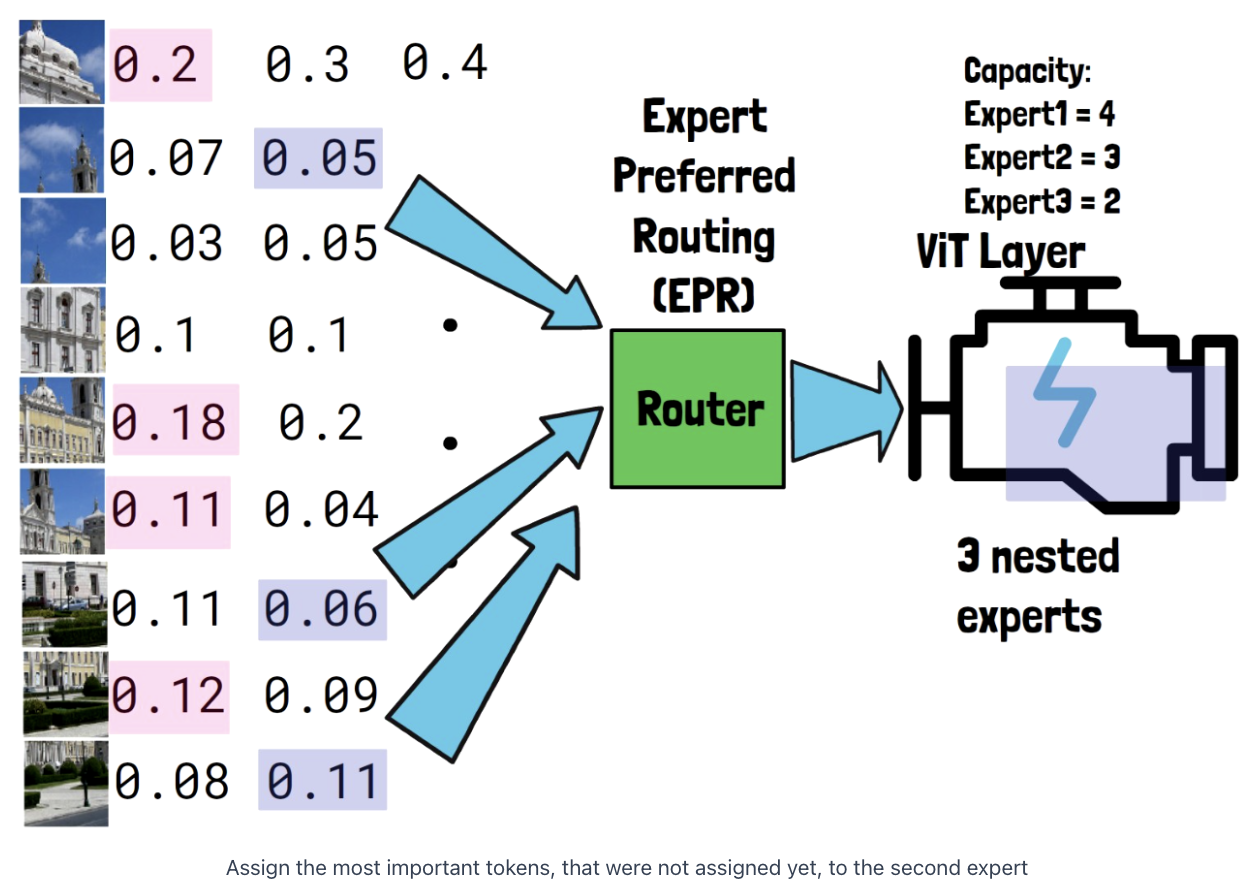
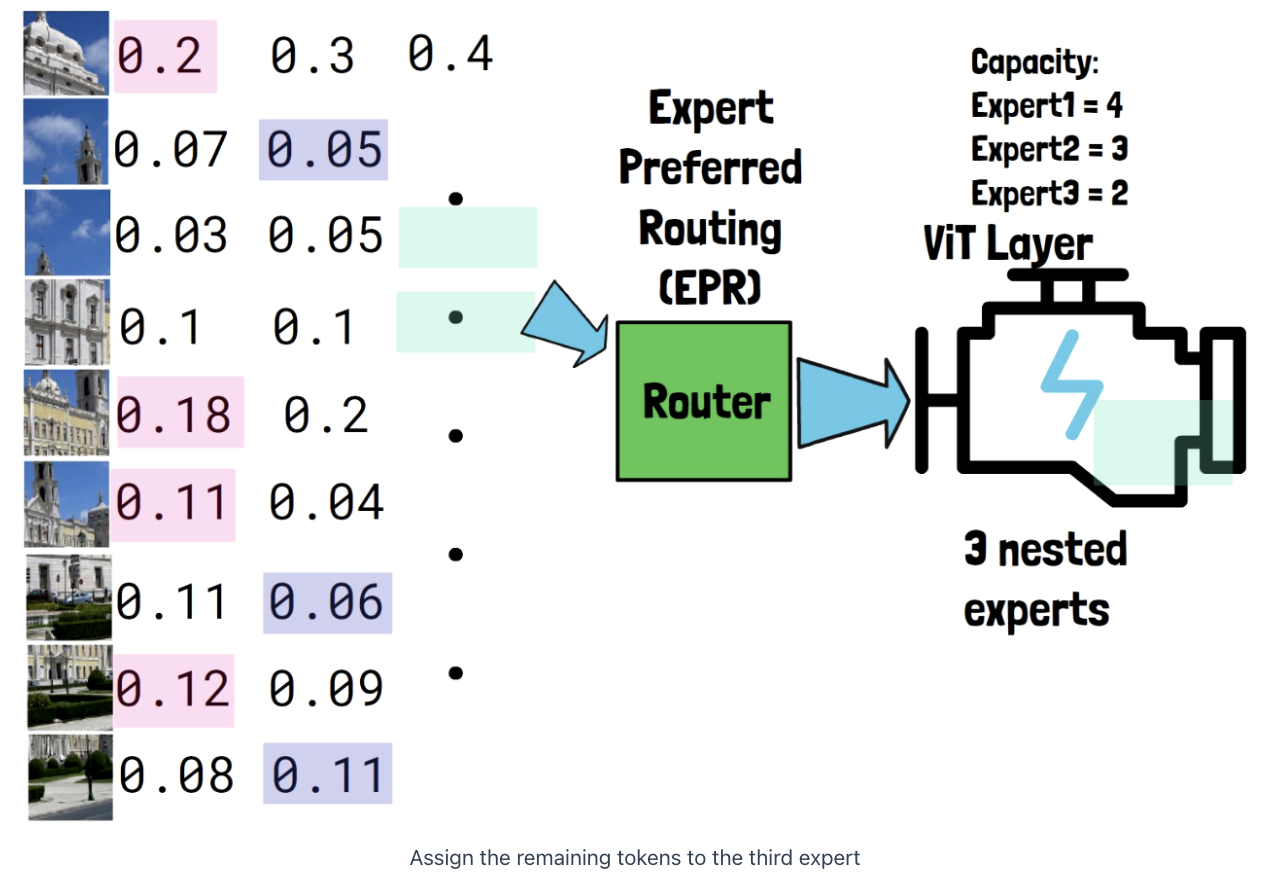
(2) Router
( Expert Preferred Router )
Router assigns probabilities to the input tokens
- First expert = allocated with the most important input tokens
- Second expert = ~ for unallocated tokens
- Third expert = ~ for unallocated tokens
(3) MoNE Layer Output
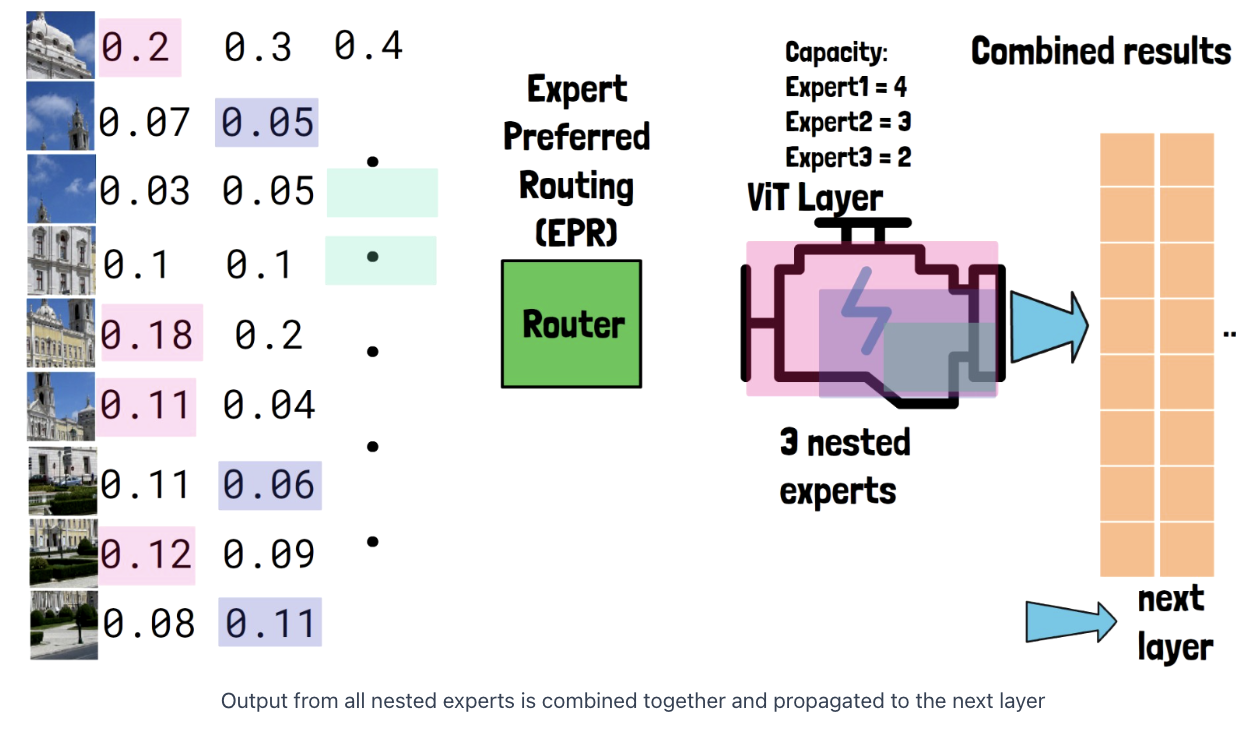
Three nested experts
\(\rightarrow\) Output from all nested experts is combined together
(4) MoNE Layer Details
Two things to note!
- This is not a single model, but a single layer !
- Tokens that are routed to nested experts which are smaller than the full layer, are downsized to the dimension of the nested expert
Example
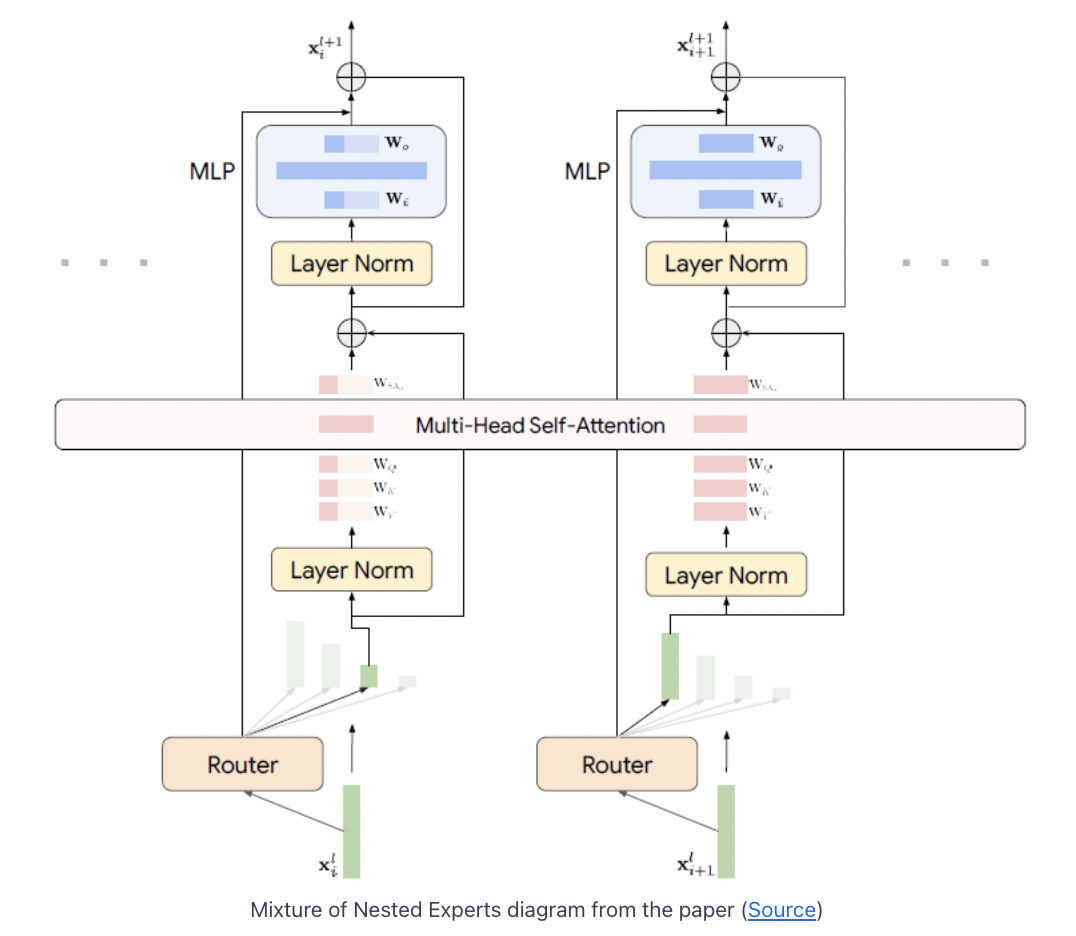
-
Two tokens to be processed
-
(Left) Assigned to the 3rd expert
\(\rightarrow\) dimension = 64
-
(Right) Assigned to the 1st expert
\(\rightarrow\) dimension = 256
a) Self-attention
-
(Left) Smaller nested expert
- Only subset of the weights of the attention module are used to extract Q,K,V
-
(Right) Larger nested expert
- Whole matrices are used.
( Tokens still interact with each other in the self-attention module )
- By padding the values received from smaller nested models, to the full model dimension
b) MLP
Only a subset of the weights being used
\(\rightarrow\) Tokens to smaller nested models: less compute!
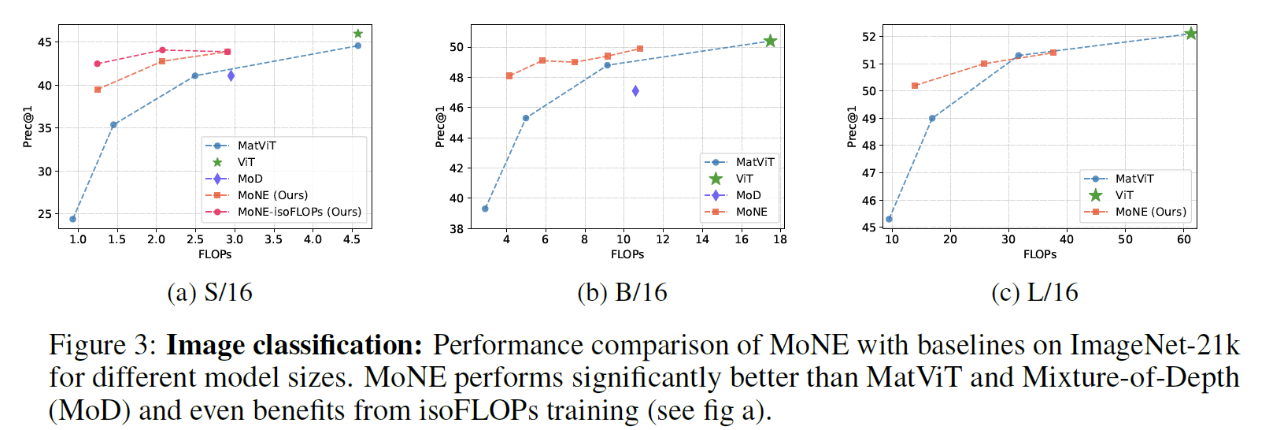
3. Experiments
(1) MoNE Tokens Important Understanding

(2) Image Classification