Retrieval-Enhanced Contrastive Vision-Text Models
https://arxiv.org/pdf/2306.07196
Contents
- Abstract
- Introduction
- Related Works
- Visual-text pretraining
- Knowledge-based vision-text models
- Retrieval-based methods
- Method
- Retrieving Cross-modal External Knowledge
- Learning how to fuse the retrieved knowledge
- Experiments
- Experimental Setup
- Zero-shot Transfer
Abstract
(1) Contrastive image-text models (e.g., CLIP)
- Building blocks of many SOTA systems
- Excel at recognizing common generic concepts
\(\rightarrow\) Limitation: Struggle on fine-grained entities
(2) Proposal: Retrieval-enhanced contrastive (RECO) training
-
Encoding fine-grained knowledge directly into the model’s parameters
-
Train the model to retrieve this knowledge from an external memory
-
Propose to equip existing vision-text models with the ability to refine their embedding with cross-modal retrieved information from a memory at inference time
-
(3) Effect
-
Greatly improves their zero-shot predictions
-
Can be done with a light-weight, single-layer, fusion transformer on top of a frozen CLIP
(4) Experiments
-
Improves CLIP performance substantially on several challenging fine-grained tasks
-
+10.9 on Stanford Cars
-
+10.2 on CUB-2011
-
+7.3 on the recent OVEN benchmark
-
1. Introduction
P1) Recent VLMs & Limitation
Development of VLM
\(\rightarrow\) Highly adaptable to various downstream tasks
Two parallel encoders using CL (i.e., two-tower models)
- Encode images and texts into an aligned latent space
- Enables appealing capabilities such as zero-shot transfer to different downstream applications
- e.g. image classification, image-text retrieval, open-world recognition
Limitation: Struggle on tasks requiring a more fine-grained understanding
P2) Two approaches
Approach 1) Scale and curate the pre-training dataset
- To cover more and more image-text associations
Approach 2) Memory or knowledge-based approaches
-
Propose to rely on the access to an external source of knowledge
- K-Lite: How to improve vision-text models by enhancing the text captions with more comprehensive text definitions retrieved from an external dictionary
-
Limitation? Initial captions are augmented within their modality only
\(\rightarrow\) Limiting the potential added-value brought by the retrieved items!
P3) Proposal
Retrieval-augmented approach
- Critical observation: (a) is simpler than (b)
- (a) Matching representations within the same modality
- (b) Matching representations across different modalities
\(\rightarrow\) Proposal: Utilize the inherent strength of learned image and text representations within their respective modalities to aid the alignment across modalities
Details
- Convert these unimodal representations into a multi-modal format
- To improve their compatibility
- Utilizing a web-scale corpus of image-text pairs for retrieval…
- Use image representation as a query
- To identify the top-\(k\) most similar images
- Incorporate the associated text to create a multi-modal representation.
- Use a text representation as a query
- To identify the top-\(k\) most similar texts
- Integrate the associated images to create a multi-modal representation
- Use image representation as a query
2. Related Works
(1) Visual-text pretraining
CLIP, ALIGN
- Potential of contrastive image-text pre-training
- Two parallel uni-modal encoders t
- Cross-modal contrastive objective
Vision-text contrastive models
= Basic building blocks of more powerful foundational models
- e.g., CoCa (Yu et al., 2022), Flamingo (Alayrac et al., 2022), FLAVA (Singh et al., 2022), and PaLI (Chen et al., 2023)
Proposed work
-
Enhance the capabilities of the CLIP
( but not specific to CLIP )
-
How? By adding a light-weight retrieval module.
(2) Knowledge-based vision-text models
Improving upon different aspects of the contrastive vision-text models
- (1) Training objectives
- (2) Scaling
\(\rightarrow\) Little exploration has been done on their combination with memory or knowledge-based techniques
Knowledge-based vision-text models
[1] REACT (Liu et al., 2023)
-
Retrieves image-text pairs from an external memory
\(\rightarrow\) Build a training dataset specialized for a specific downstream task.
-
Proposed (vs. REACT)
-
(1) Does not require any pre-knowledge about the nature of the downstream task
\(\rightarrow\) \(\therefore\) Applicable in a full zero-shot transfer
-
(2) Leverage items from the memory at inference time
( REACT: uses retrieved items to automatically generate a training set to finetune their model )
-
[2] K-LITE (Shen et al., 2022)
-
Learns vision-text models by leveraging external sources of knowledge
- e.g., WordNet (Meyer & Gurevych, 2012) or Wiktionary (Miller, 1998)
to complete captions with more descriptive content.
-
Proposed (vs. K-LITE)
- K-LITE: Retrieved knowledge is uni-modal (text) & External memory is not used for the image tower
[3] NNCLR (Dwibedi et al., 2021)
- Image-only representation learning (VLM (X))
- Finds the visual nearest-neighbor of each training image from a memory
[4] LGSimCLR (Banani et al., 2023)
- Uses the language guidance to find most similar visual nearest-neighbor
NNCLR & LGSimCLR
- (a) Only learn visual representations
- (b) Use retrieval to enhance their supervision during training but not at inference
(3) Retrieval-based methods
Main argument of the retrieval-based methods
Not all the world knowledge can be compiled into a model’s parameters
\(\rightarrow\) \(\therefore\) Should also learn to rely on items retrieved from an external memory at inference
Retrieval-based methods
- (Original) Shown their promise in various NLP tasks
- (Recent) Increasing interest in the computer vision for retrieval-based methods
[1] SuS-X (Udandarao et al., 2023)
- “Cross-modal search and cross-modal fusion”
- Retrieve similar samples to the query sample from a large data-bank
- Improve zero-shot classification performance
[2] RA-CLIP (Xie et al., 2023)
- Enriches the CLIP visual representation
- Retrieve image and text.
- Limitation: Attempt to enrich the text representation degrades the performance,
3. Method
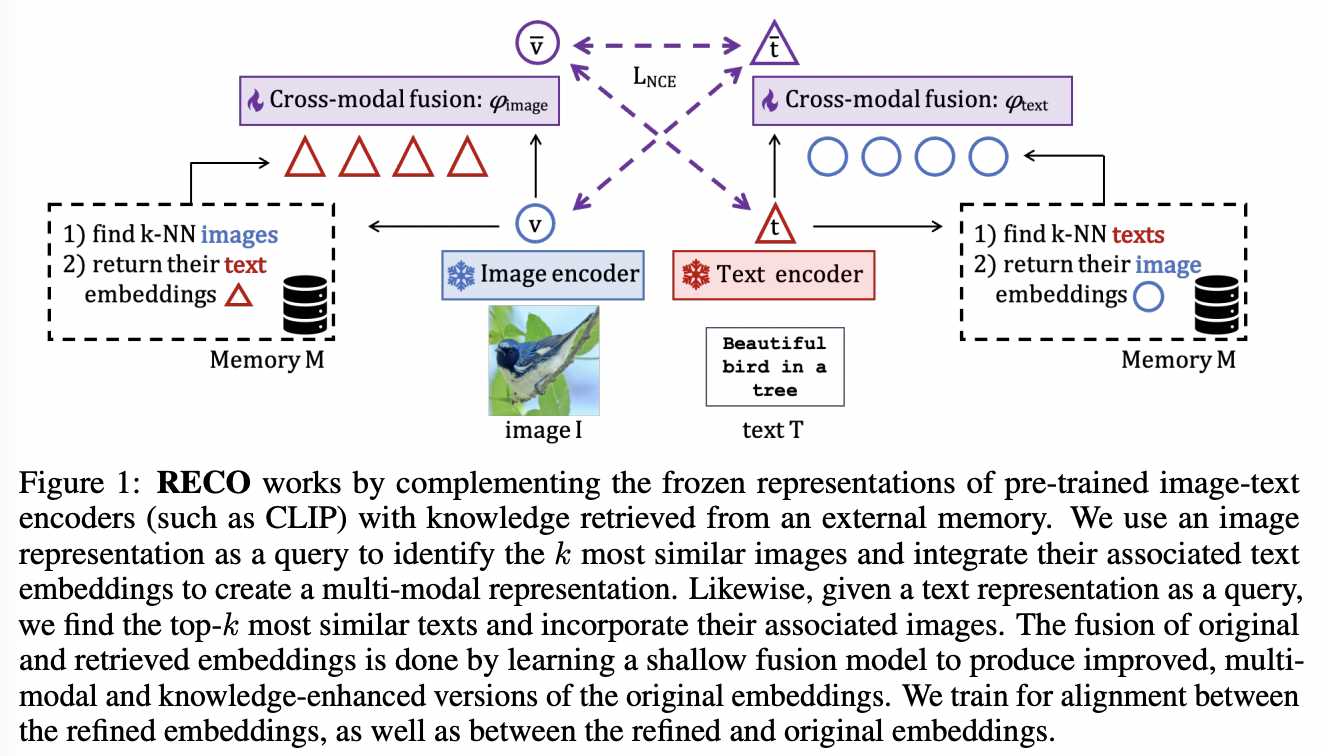
Goal: Equip powerful pre-trained VLMs with the ability to complement their representations with cross-modal knowledge retrieved from an external memory
Details
-
Do not retrain from scratch
-
Learn a light-weight retrieval fusion module on top of them
-
Does not propose a new model or loss
( Rather a new way of adapting pre-trained models )
Preliminaries
Notation:
- \(\mathbf{v}=\) \(f_{\text {image }}(I)\) .
- \(\mathbf{t}=f_{\text {text }}(T)\).
InfoNCE loss btw embeddings of different modalities:
-
\(\mathcal{L}_{\mathrm{NCE}}(\mathbf{V}, \mathbf{T})=-\sum_{i=1}^n\left[\log \frac{e^{\mathbf{v}_i^{\top} \mathbf{t}_i / \tau}}{\sum_j e^{\mathbf{v}_i^{\top} \mathbf{t}_j / \tau}}+\log \frac{e^{\mathbf{v}_i^{\top} \mathbf{t}_i / \tau}}{\sum_j e^{\mathbf{v}_j^{\top} \mathbf{t}_i / \tau}}\right]\).
-
where \(\mathbf{V}\) (resp. \(\mathbf{T}\) ) is the matrix composed of the \(n\) visual (resp. text) embeddings
Propose to augment the text and visual embeddings ( i.e. \(\mathbf{t}\) and \(\mathbf{v}\) ) with external cross-modal knowledge
- To enhance both their expressiveness and their cross-modality alignment
Following section
- 3-1) How to retrieve relevant cross-modal knowledge
- based on within-modality search
- 3-2) How to fuse the retrieved information into the original embeddings
(1) Retrieving Cross-modal External Knowledge
a) Memory
External source of knowledge by a memory
- \(\mathcal{M}=\left\{\left(I_i, T_i\right)\right\}_{i=1}^M\) of \(M\) image-text pairs.
- Assume that \(\mathcal{M}\) is very large and covers a broad coverage of concepts
(In practice) Only a small-subset of \(\mathcal{M}\) is relevant (for a given input query)
\(\rightarrow\) Only consider the \(k\) most relevant items from \(\mathcal{M}\) for each input (via NN)
- \(\mathrm{KNN}(\mathbf{v}, \mathcal{M})\) and \(\mathrm{KNN}(\mathbf{t}, \mathcal{M})\)
b) Cross-modal fusion
Goal: Augment the text and visual original embeddings with crossmodal knowledge
For a given text or image input…
- Retrieval module \(\mathrm{KNN}(., \mathcal{M})\)
- \(\mathrm{KNN}_t(\mathbf{v}, \mathcal{M})\): Returns text embeddings from an image input
- \(\mathrm{KNN}_v(\mathbf{t}, \mathcal{M})\) : Returns image embeddings for text input
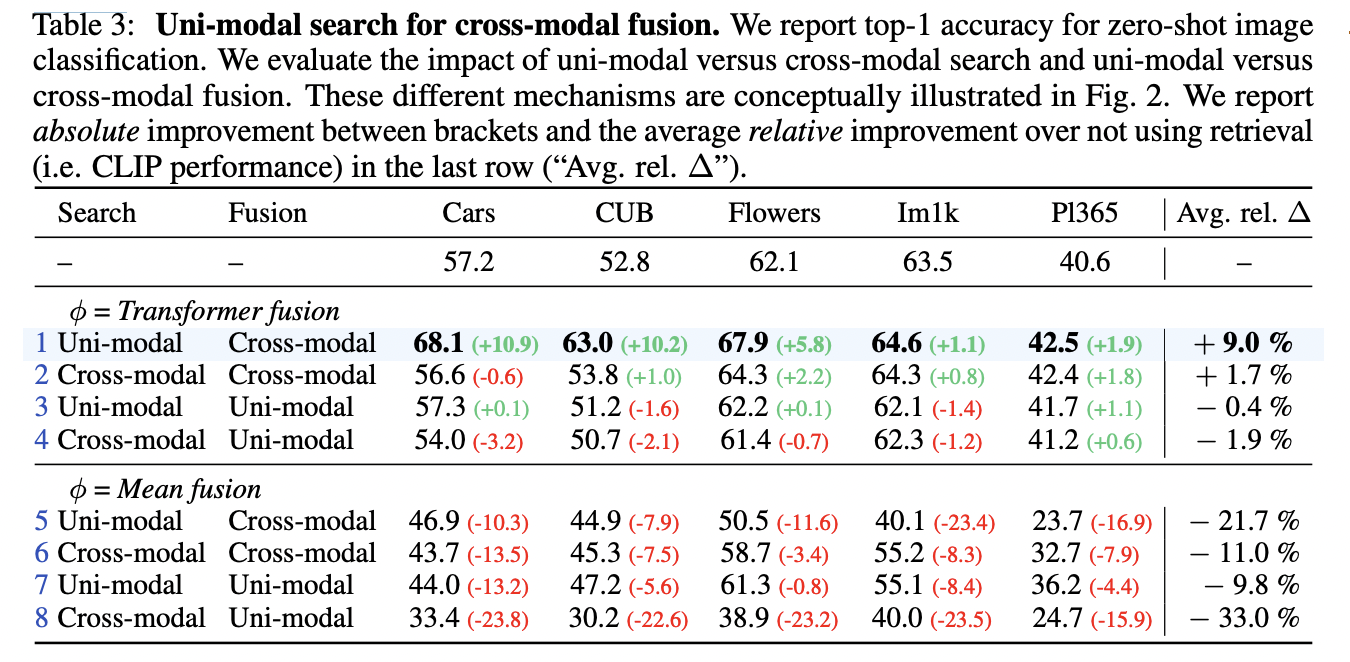
Also evaluate uni-modal fusion in our experiments!
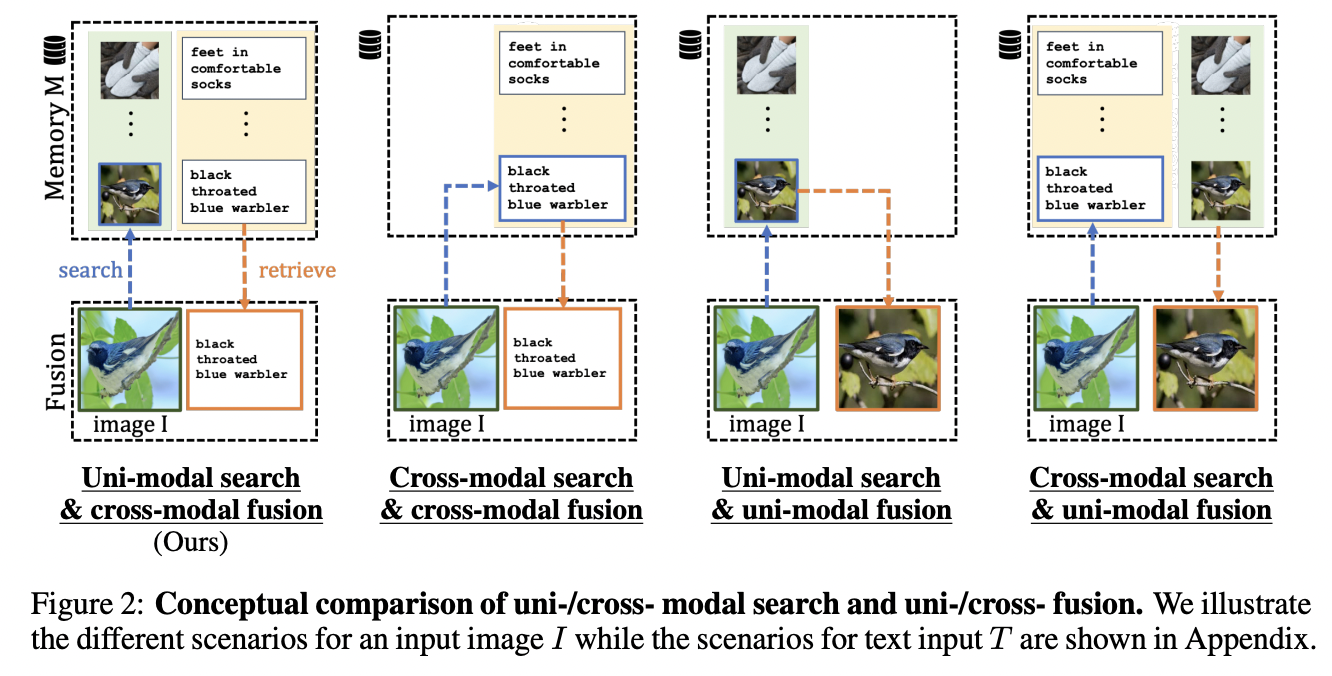
c) Uni-modal search
Search relevant items in the memory \(\mathcal{M}\) based on within-modality similarities
- Text-to-text similarity \((t \rightarrow t)\)
- Image-to-image similarity \((v \rightarrow v)\)
Notation
- \(\mathbf{V}^{\mathcal{M}}\) and \(\mathbf{T}^{\mathcal{M}}\) all the image and text embeddings from \(\mathcal{M}\)
- \(\mathbf{V}^{\mathcal{M}}=\left[f_{\text {image }}\left(I_1\right), \ldots, f_{\text {image }}\left(I_M\right)\right]\).
- \(\mathbf{T}^{\mathcal{M}}=\left[f_{\text {text }}\left(T_1\right), \ldots, f_{\text {text }}\left(T_M\right)\right]\).
-
\[\mathrm{KNN}_t^{v \rightarrow v}(\mathbf{v}, \mathcal{M})=\mathbf{T}^{\mathcal{M}}{ }_{\mathrm{NN}\left(\mathbf{v} ; \mathbf{V}^{\mathcal{M}}\right)}\]
- For input image embedding \(\mathbf{v}\),
- The KNN search is done between \(\mathbf{v}\) and \(\mathbf{V}^{\mathcal{M}}\)
- But the corresponding \(k\)-NN indices from the text embeddings \(\mathbf{T}^{\mathcal{M}}\) are selected.
-
\[\mathrm{KNN}_v^{t \rightarrow t}(\mathbf{t}, \mathcal{M})=\mathbf{V}^{\mathcal{M}}{ }_{\mathrm{NN}\left(\mathbf{t} ; \mathbf{T}^{\mathcal{M}}\right)}\]
- vice versa
Also evaluate cross-modal search
\(\rightarrow\) Leads to much poorer performance!
(2) Learning how to fuse the retrieved knowledge
Goal: Refine the original image and text embeddings \(\mathbf{v}\) and \(\mathbf{t}\) with the cross-modal knowledge gathered from \(\mathcal{M}\).
Notation
-
Refined image and text embeddings: \(\overline{\mathbf{v}}\) and \(\overline{\mathbf{t}}\)
- \(\overline{\mathbf{v}}=\phi_{\text {image }}\left(\mathbf{v}, \mathrm{KNN}_t^{v \rightarrow v}(\mathbf{v}, \mathcal{M})\right)\).
- \(\overline{\mathbf{t}}=\phi_{\text {text }}\left(\mathbf{t}, \mathrm{KNN}_v^{t \rightarrow t}(\mathbf{t}, \mathcal{M})\right)\),
where \(\phi\) is the fusion model
a) Transformer fusion
\(\phi_{\text {image }}\) and \(\phi_{\text {text }}\)
= One-layer multi-head self-attention transformer encoders
\(\rightarrow\) Allows the original embedding to attend to all the retrieved elements in the fusion process.
Also tried mean fusion \(\rightarrow\) Performs poorly
b) Learning
Train the fusion model \(\phi\) on \(\mathcal{D}=\left\{\left(I_i, T_i\right)\right\}_{i=1}^N\)
How? By performing retrieval at training time from the memory \(\mathcal{M}\).
- Encoder \(f\) is kept frozen.
Loss: Minimize the alignment loss
\(\mathcal{L}=\mathcal{L}_{\mathrm{NCE}}(\overline{\mathbf{V}}, \overline{\mathbf{T}})+\mathcal{L}_{\mathrm{NCE}}(\overline{\mathbf{V}}, \mathbf{T})+\mathcal{L}_{\mathrm{NCE}}(\mathbf{V}, \overline{\mathbf{T}})\).
4. Experiments
(1) Experimental Setup
a) Training details
(1) Model
-
Train the fusion model on top of a frozen CLIP
-
Also present a variant of RECO on top of a frozen LiT-L16L
(2) Datasets: Conceptual Captions 12M
- Image-text dataset containing about 10 M pairs.
(3) Details
- Batch size of 4096
- Learning rate of \(1 e^{-3}\)
- 10 epochs
(4) Memory: Subset of WebLI
-
Containing 1B image-text pairs
( Remove the near-duplicates of the test images from the memory )
-
Appendix: LAION-400M dataset
b) Evaluation datasets
Six image classification datasets
- Stanford Cars (“Cars”)
- CUB-200-2011 (“CUB”)
- Oxford Flowers (“Flowers”)
- ImageNet-1k (“Imlk”)
- Places 365 (“Pl365”)
- Stanford Dogs (“Dogs”)
Open-domain visual entity recognition (OVEN) benchmark
- Containing 729 K test images
- Belonging to 6 M entity candidates
Text-to-image & Image-to-text retieval on
- Flickr30k (“Flickr”)
- MS COCO (“COCO”)
c) Evaluation protocol
Zero-shot setting for all
- No adaptation is done to the downstream task
As common in the literature ….
- Add prompts to the text of the downstream tasks
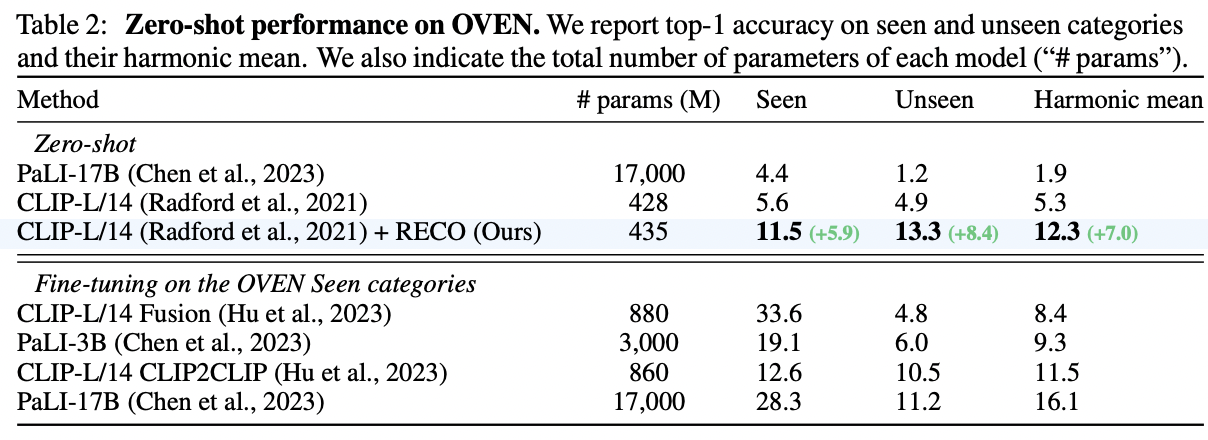
(2) Zero-shot Transfer
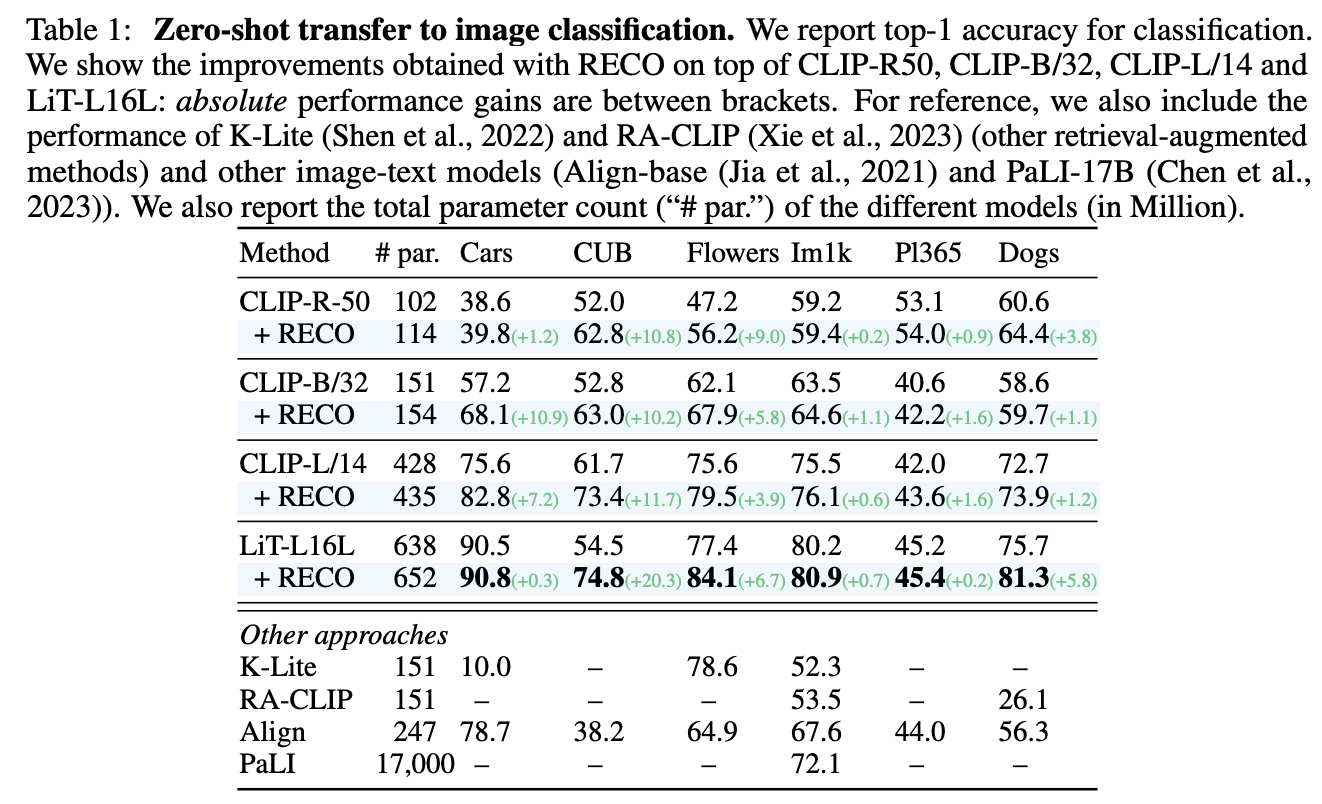
a) Image classification
Zero-shot performance of CLIP & LiT on Image classification
- Large improvements especially on the fine-grained datasets
- e.g., Improvement of original CLIP-B/32 accuracy by …
- +10.9 on Cars
- +10.2 on CUB
- +5.8 on Flowers
- e.g., Improvement of original CLIP-B/32 accuracy by …
- Also improved on less fine-grained benchmarks
- e.g., ImageNet or Places
- Performance gains are consistent across all vision-text backbones
- e.g., CLIP-R-50, CLIP-B/32, CLIP-L/14, and LiT-L16L
b) Open-domain visual entity recognition (OVEN)