SpecAugment on Large Scale Datasets (ICASSP, 2019)
https://arxiv.org/pdf/1912.05533.pdf
Contents
- Abstract
- Introduction
- SpecAugment
- Adaptive Masking
- Experiments
Abstract
SpecAugment: augmentation scheme for ASR
- directly on the spectrogram of input utterances
This paper :
-
demonstrate its (1) effectiveness on tasks with large scale datasets
( by investigating its application to the Google Multidomain Dataset )
-
introduce a (2) modification of SpecAugment
- “adaptive masking” : adapts the time mask size and/or multiplicity
- depending on the length of the utterance
- “adaptive masking” : adapts the time mask size and/or multiplicity
-
further improve the performance of the Listen, Attend and Spell model on LibriSpeech
( LibriSpeech: https://www.aitimes.kr/news/articleView.html?idxno=20198 )
( https://www.openslr.org/12 )
- 2.2% WER on test-clean
- 5.2% WER on test-other
1. Introduction
Data augmentation : successful method for ASR
- ex) SpecAugment
- improving the performance of ASR networks on the 960h Librispeech & 300h Switchboard
Question) Effectiveness of SpecAugment ofor large scale tasks?
\(\rightarrow\) this paper : use Google Multidomain Dataset
- large scale multi-domain dataset
- multiple test sets from disparate domains
Multistyle TRaining (MTR)
- mixed room simulator is used to combine clean audio with a large library of noise audio
Result summary ( of various augmentations )
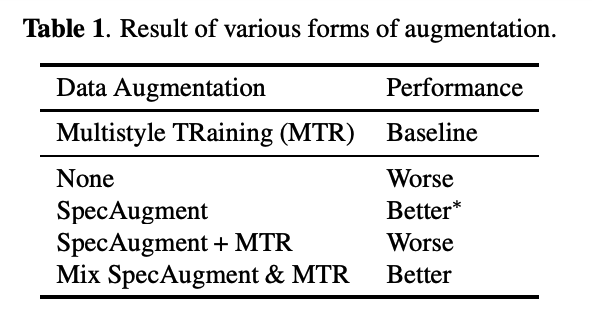
-
SpecAugment:
-
better on all natural test sets
-
worse on a synthetic test set obtained by applying MTR to test utterances.
( applying SpecAugment on top of MTR degrades performance across most domains )
-
-
Mix SpecAugment (proposed): BEST
SpecAugment
- requires a negligible amount of additional computational resources
- does not require additional audio data
- can be applied online
- highly scalable as the training set becomes large
- consists of..
- frequency masking
- time masking
- time warping
- fixed number of time masks regardless the length of the utterance
Proposed
SpecAugment can be considered as a serious alternative to more sophisticated resource-heavy augmentation methods.
-
On large scale tasks spanning multiple domain … expect the length of the utterances to have a large variance
\(\rightarrow\) . introduce adaptive time masking
Adaptive Time Masking
- number of time masks & size of the time mask vary depending on the length of the input
- experiment) Google Multidomain Dataset & LibriSpeech 960h
(1) Related Work
Vocal Tract Length Perturbation
Noisy audio signals
Speed perturbation
Acoustic room simulators
-
Multistyle TRaining (MTR) : clean audio is combined with background noise using a room simulator
-
successfully applied to HMM-based systems & end-to-end LAS models
Question) How SpecAugment compares to or can complement existing data augmentation techniques like MTR, especially on large scale datasets?
Contribution
-
Scale up SpecAugment to large scale industrial datasets
- compare to existing MTR data augmentation & improve it
-
SpecAugment improves the performance of streaming models.
-
Mix SpecAugment
-
Adaptive version of SpecAugment
( =degree of time masking is adaptive to the input sequence length )
-
2. SpecAugment
Review of SpecAugment
- obtained by composing 3basic augmentations
- time warping & frequency masking & time masking
- notation
- time dim = \(\tau\)
- freq dim = \(\nu\)
a) Time warping with parameter \(W:\)
- displacement : \(w \sim \text{Unif}(-W,W)\).
- start point : \(w_0 \sim \text{Unif}(W,\tau-W)\).
- linear warping function
- \(\mathcal{W}(t)= \begin{cases}\left(\frac{w_0+w}{w_0}\right) t & t \leq w_0, \\ \frac{\left(\tau-1-w_0-w\right) t+(\tau-1) w}{\tau-1-w_0} & t>w_0 \end{cases}\).
- intuition:
- start point \(w_0\) is mapped to the point \(w_0+w\)
- boundary points \(t=0\) and \(t=\tau-1\) are fixed
- warped features \(\mathbf{x}_{\text {warp }}(t)\) at time \(t\) are related to the original features \(\mathbf{x}_{\text {orig }}(t)\) b
- \(\mathbf{x}_{\text {warp }}(\mathcal{W}(t))=\mathbf{x}_{\text {orig }}(t)\).
b) Frequency masking with parameter \(F\)
- mask size : \(f \sim \text{Unif}(0,F)\)
- mask start point : \(f_0 \sim \text{Unif}(0, \nu-f)\)
- consecutive log-mel frequency channels \(\left[f_0, f_0+f\right)\) are then masked
c) Time masking with parameter \(T\)
- mask size : \(t \sim \text{Unif}(0,T)\)
-
mask start point: \(t_0 \sim \text{Unif}(0,\tau-t)\)
- consecutive time steps \(\left[t_0, t_0+t\right)\) are masked
\(\rightarrow\) SpecAugment applys these three augmentations a fixed number of times.
3. Adaptive Masking
Large scale datasets
- contain disparate domains of inputs
- large variance in the length of the input audio
\(\rightarrow\) Fixed number of time masks may not be adequate!
- ex) time masking may be too weak (severe) for longer (shorter) utterances
Introduce 2different ways time masking can be made adaptive
( w.r.t length of spectogram \(\tau\) )
a) Adaptive multiplicity
# of time masks : \(M_{\mathrm{t} \text {-mask }}=\left\lfloor p_M \cdot \tau\right\rfloor\)
- for the multiplicity ratio \(p_M\)
b) Adaptive size
time mask parameter : \(T=\left\lfloor p_S \cdot \tau\right\rfloor\)
- for the size ratio \(p_S\).
Summary )
- this paper caps the number of time masks at 20
- \(M_{\mathrm{t} \text {-mask }}=\min \left(20,\left\lfloor p_M \cdot \tau\right\rfloor\right)\).
4. Experiments
(1) LibriSpeech 960h
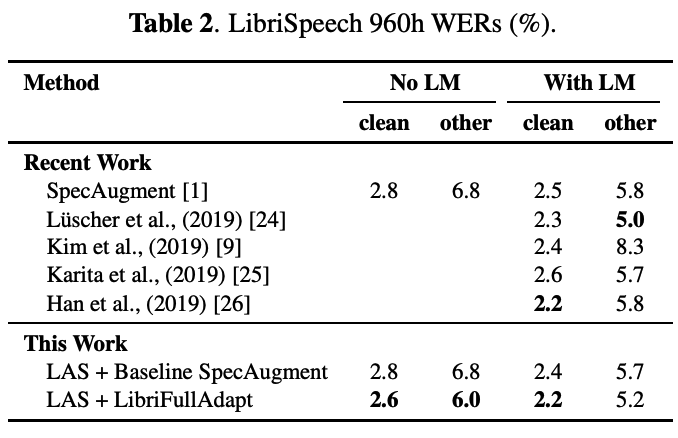
(2) Google Multidomain Dataset