FilterAugment; An Acoustic Environmental Data Augmentation Method (Interspeech, 2022)
https://arxiv.org/pdf/2110.03282.pdf
Contents
- Abstract
- Introduction
- Audio Data Augmentations
- Proposed Method
- Motivation
- Algorithm
- Experiments
Abstract
FilterAugment
-
DA method for regularization of acoustic models on various acoustic environments
-
mimics acoustic filters by applying different weights on frequency bands
\(\rightarrow\) enables model to extract relevant information from wider frequency region.
-
improved version of frequency masking
- masks information on random frequency bands
-
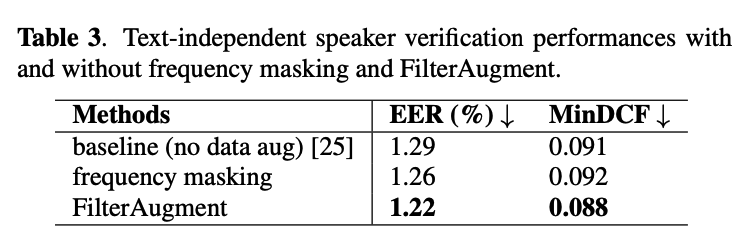
Experimental results
-
improve sound event detection (SED) model performance by 6.50%
( while frequency masking only improved 2.13% )
-
polyphonic sound detection score (PSDS)
-
equal error rate (EER) of 1.22% when applied to a text-independent speaker verification model
( model used frequency masking with EER : 1.26% )
-
-
1. Introduction
SpecAugment [10] : pass
\(\rightarrow\) limitation : brutal in the sense that they completely remove certain information from the data
FilterAugment
( an improved version of frequency masking from SpecAugment )
Intuition: Sound could be heard differently in various acoustic environments
- ex)such as conference room, shower room, performance hall, cave, etc.
Propose to regularize acoustic models over various acoustic environments by mimicking acoustic filters
- Highly variable acoustic characteristics can be modeled using acoustic filters, which FilterAugment aims to mimic in a simplified way!
- Approximates acoustic filters by applying random weights on randomly determined frequency bands.
Experiments) Detection and Classification of Acoustic Scenes and Events (DCASE) 2021 challenge task
2. Audio Data Augmentations
DA using conventional audio signal processing
- (1) could introduce some inefficiencies!
- may involve more computations in expense for more natural sound
- (2) requires prior knowledge to appropriately handle audio data
\(\rightarrow\) Such inefficiencies hinder optimal training of acoustic models!
Solution ) simple / intuitive / effective … SpecAugment!
- powerful and widely used data augmentation methods in audio and speech domain
- directly applied on log mel spectrogram.
Intuition of SpecAugment
(1) Time warping
- sound like the audio played faster in some points and slower in some other points.
(2) Time masking
- sound that some parts are not played for short duration.
(3) Frequency masking
- sound like some part of frequency range is missing
\(\rightarrow\) As long as these distortions are not too severe, human can recognize the content of audio data after these processing, and trained acoustic models should do as well.
3. Proposed Method
(1) Motivation
FilterAugment = can be explained in 2 different but related points of view.
[ Viewpoint 1] Acoustics and signal processing
- regularizes acoustic models to various acoustic environments by mimicking acoustic filters
[ Viewpoint 2 ] Acoustic model training
- learns to effectively extract acoustic information from wide frequency ranges while training.
Viewpoint 1) Acoustics and Signal Processing
When we hear sound events or speeches, we can recognize their contents regardless of acoustic environments
\(\rightarrow\) \(\because\) Our auditory system is trained to understand the sound contents regardless of the acoustic environments
Acoustic environment
( = physical objects surrounding the sound source )
- These interact with sound wave and change the acoustic characteristics of sound
\(\rightarrow\) such change in acoustic characteristics appears as relative change in energy on different frequency range
Examples
Ex 1) sound source is far away from the receiver
= high-frequency energy reduces
( \(\because\) it dampens more than low-frequency energy does while propagating in the air )
Ex 2) when there is a wall or any object blocking between the receiver and the sound source..
= high-frequency energy reduces
( \(\because\) it does not diffract easily thus does not propagate to the receiver much )
\(\rightarrow\) Such change in energy on different frequency ranges can be simulated by designing appropriate types of filter: high pass filter, low pass filter, band pass filter, notch filter, etc.
Limitations of such filters
- (1) requires understanding in acoustics and signal processing
- (2) applying filters to training audio data takes time to compute filters’ impulse responses and convolute them with audio data.
- (3) complicate training and optimization process
\(\rightarrow\) solution : FilterAugment
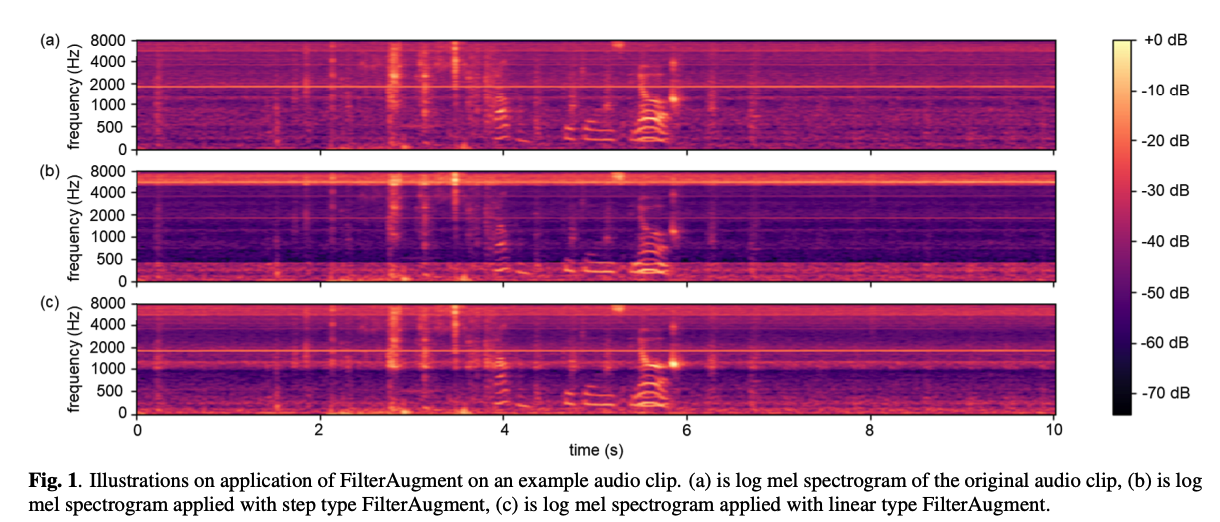
FilterAugment
Simpler alternative data augmentation method to mimic filter effect
-
randomly increases or decreases energy of random frequency ranges of log mel spectrograms.
( = equivalent to application of random filters )
-
Although it might sound unnatural compared to acoustic filters as it induces discrete filter design, FilterAugment is much easier to comprehend and use.
Viewpoint 2) Acoustic model training
Randomly weighting on random frequency bands of log mel spectrogram
= enables training of acoustics models to extract sound information from wider frequency regions
w/o FilterAugment …
-
acoustic model is likely to learn to recognize frequency ranges that exhibit “dominant and distinctive” feature of desired labels
-
however, we can recognize the sound content regardless of the acoustic environment
\(\rightarrow\) can still recognize sound content from the other less distinctive frequency ranges
\(\rightarrow\) \(\therefore\) frequency masking improves training acoustic models as well!
Frequency masking
-
removes information from certain random frequency range
-
helps to train acoustic model to infer the sound information from less distinctive frequency regions
-
problem of masking
= completely removes certain part of energy that might help inferring the sound information.
\(\rightarrow\) solution) remove (X) weaken (O) some parts of frequency range while strengthening other parts instead.
Therefore, FilterAugment helps training acoustic models to extract information from the wider range of frequency regardless of each frequency’s relative significance composing the sound information.
(2) Algorithm
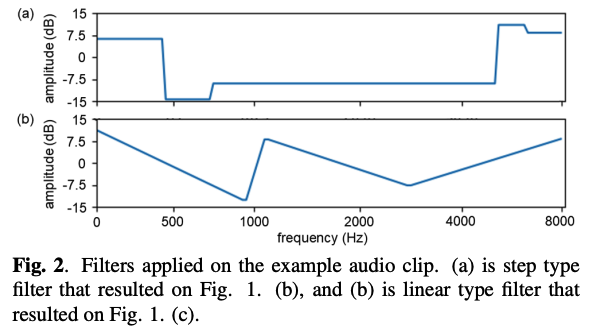
Propose 3 types of FilterAugment
- (1) step
- (2) linear
- (3) mixed
Procedure
-
Randomly choose number of frequency bands \(n\)
( within hyperparameter band number range )
-
Randomly choose \(n-1\) mel frequency bins between 0 and \(F\) ( = # of mel frequency bins in mel spectrogram )
+ Include 0 and \(F\) to form \(n+1\) frequency boundaries
-
Randomly choose \(n\) different weights
( within hyperparameter \(d B\) range )
-
Add chosen \(n\) weights on \(n\) frequency bands of log mel spectrogram defined by each set of subsequent frequency boundaries respectively.
\(\rightarrow\) Result: Mel spectrogram’s energy is ..
- amplified in some frequency bands
- reduced in other bands.
4. Experiments