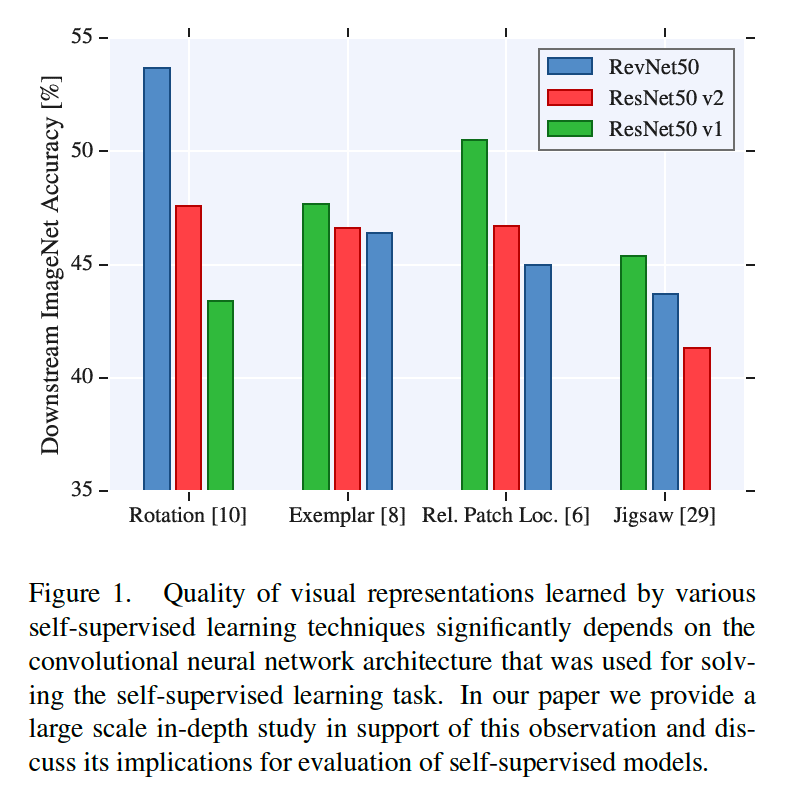
Revisiting Self-Supervised Visual Representation Learning
Contents
- Abstract
- Introduction
0. Abstract
Previous works :
- mostly focus on pre-text tasks
- but not on CNN architectures
\(\rightarrow\) this paper revisit the previously proposed models!
1. Introduction
4 main contributions :
- best architecture design : FULLY-supervised \(\neq\) SELF-supervised
- (unlike AlexNet) ResNet architecture
- learned representations do not degrade toward the end of the model
-
increasing the model complexity of CNN
\(\rightarrow\) increase the quality of learned visual representation
- (in evaluation procedure) lr is sensitive in linear model