ConvMAE : Masked Convolution Meets Masked Autoencoders
Contents
- Abstract
- Approach
- Masked Autoencoders (MAE)
- ConvMAE
0. Abstract
ConvMAE framework
-
multi-scale hybrid convolution-transformer can learn more discriminative representations via the mask auto-encoding scheme
-
directly using the original masking strategy : heavy computational cost
\(\rightarrow\) solution ) adopt the masked convolution
- simple block-wise masking strategy for computational efficiency
- propose to more directly supervise the multi-scale features of the encoder to boost multi-scale features
1. Approach
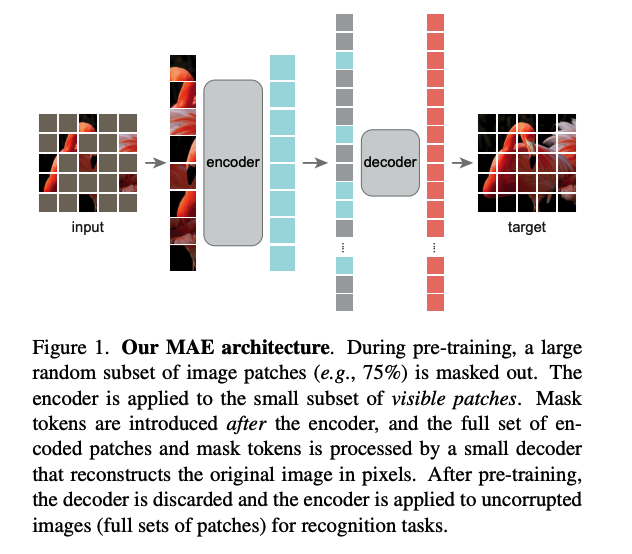
(1) Masked Autoencoders (MAE)
Details :
-
simple, but strong & scalable pretraining framework for learning visual representations
-
self-supervised method for pretraining ViT
( by reconstructing masked RGB patches, from visible patches )
-
consists of transformer-based ENCODER & DECODER
- ENCODER ) only visible patches are fed
- DECODER ) learnable mask tokens are processed
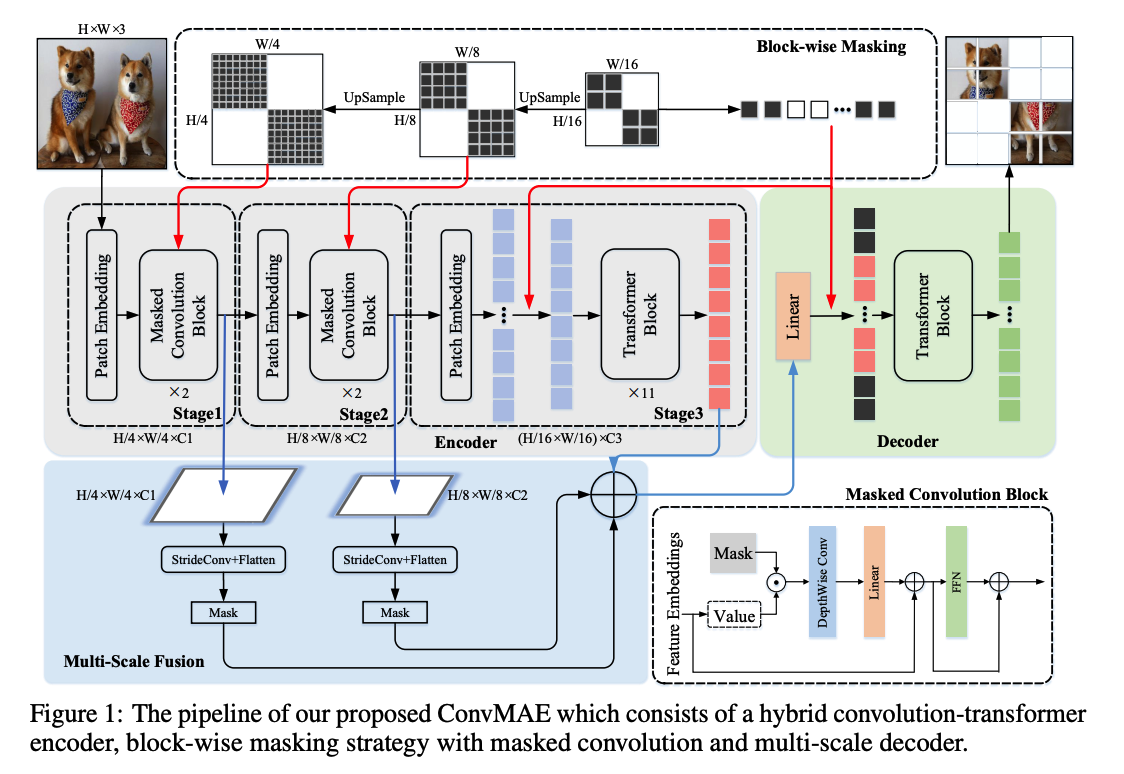
(2) ConvMAE
ConvMAE = simple & effictive derivative of MAE
( + modifications on the encoder design & masking strategy )
Goal of ConvMAE :
-
(1) learn discriminative multi-scale visual representations
-
(2) prevent pretraining-finetuning discrepency
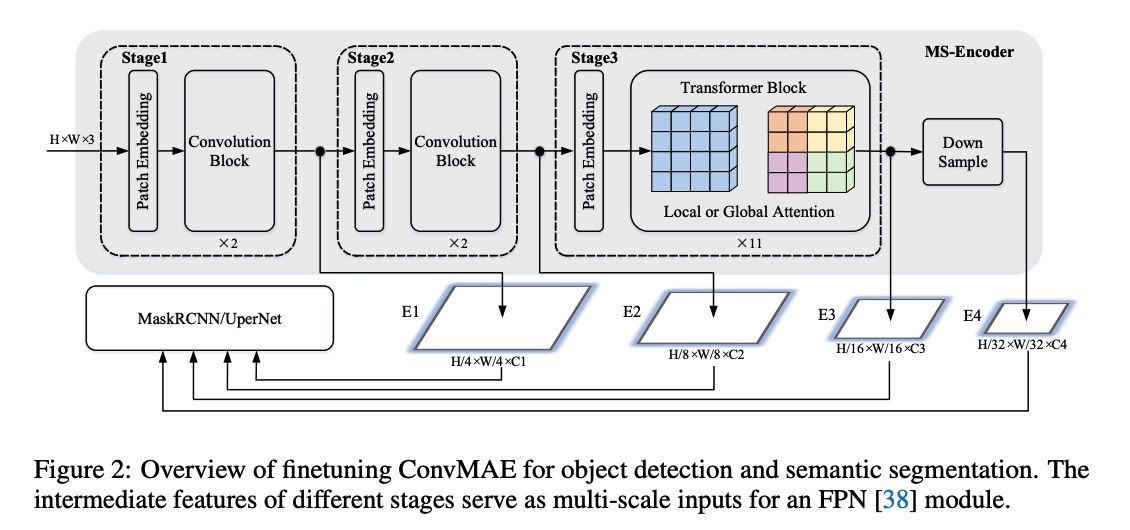
a) Hybrid Convolution-transformer Encoder
encoder consists of 3 stages
-
with output spatial resolutions of \(\frac{H}{4} \times \frac{W}{4}, \frac{H}{8} \times \frac{W}{8}, \frac{H}{16} \times \frac{W}{16}\)
-
[ 1 & 2 stage ]
-
use convolution blocks to transform the inputs to token embeddings
- \(E_1 \in \mathbb{R}^{\frac{H}{4} \times \frac{W}{4} \times C_1}\) & \(E_2 \in \mathbb{R}^{\frac{H}{8} \times \frac{W}{8} \times C_2}\)
-
follow the design principle of the transformer block
( by only replacing the self-attention operation with the \(5 \times 5\) depthwise convolution )
-
-
[ 3 stage ]
- use self-attention blocks to obtain token embeddings
- \(E_3 \in \mathbb{R}^{\frac{H}{16} \times \frac{W}{16} \times C_3}\).
- use self-attention blocks to obtain token embeddings
-
between every stage…
\(\rightarrow\) stride-2 convolutions are used to downsample the tokens
b) Block-wise Masking with Masked Convolutions