
Context Autoencoder for Self-Supervised Representation Learning
Contents
- Abstract
- Introduction
- Approach
- Architecture
- Objective Function
0. Abstract
Context AutoEncoder (CAE)
-
novel masked image modeling (MIM) approach
-
for self-supervised representation pretraining
Goal of CAE :
- pretrain an encoder by solving the pretext task
- pretext task :
- estimate the masked patches from the visible patches
Details :
- step 1) feeds the visible patches into the encoder
- extract representations
- step 2) make predictions from visible patches to masked patches
- introduce an alignment constraint
- encourage the alignment between..
- (1) representations of “predicted” masked patches
- (2) representations of masked patches “computed from encoder”
- encourage the alignment between..
- step 3) predicted masked patch representations are mapped to the targets of the pretext task through a decoder
1. Introduction
previous MIM methods ( e.g., BEiT )
- couple the encoding & pretext task competetion roles
\(\leftrightarrow\) CAE : separation of encoding (=RL) & pretext task
Downstream task
- semantic segmentation
- object detection
- instance segmentation
CAE
-
propose CAE for improving encoding quality
-
randomly partition image into 2 set of patches
-
(1) visible
-
(2) masked
-
-
architecture
- (1) encoder
- (2) latent contextual regressor (with an alignment constraint)
- (3) decoder
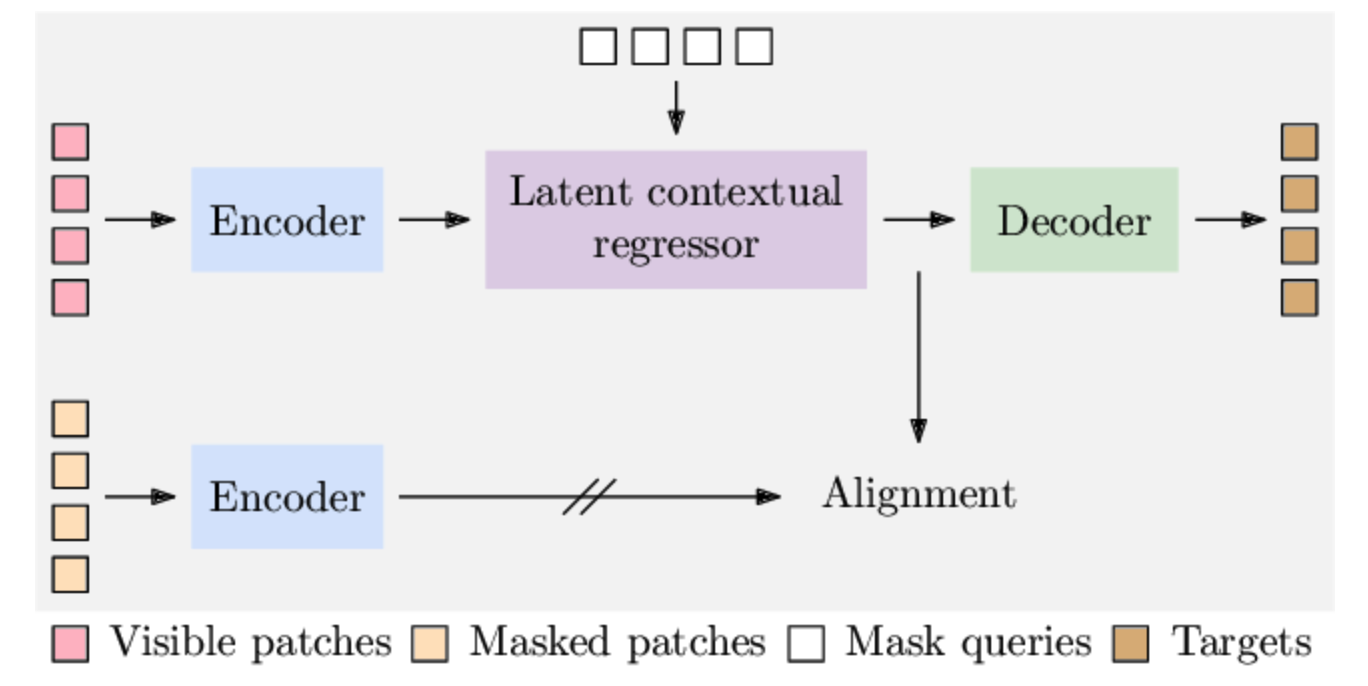
2. Approach
CAE pretrains the encoder,
by solving the masked image modeling task
(1) Architecture
randomly split an image into two sets of patches
- (1) visible patches \(\mathbf{X}_v\)
- (2) masked patches \(\mathbf{X}_m\)
pretext task :
- predict the masked patches from visible patches in the encoded represrentation space
- then, map the predicted representations to the targets
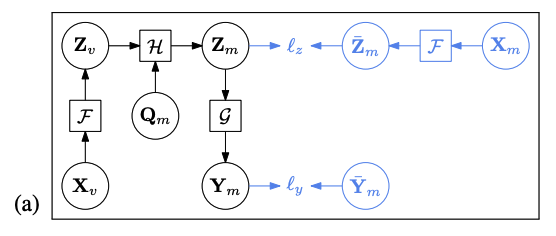
a) Encoder \(\mathcal{F}\)
-
learns representations only for VISIBLE patches
- maps the visible patches \(\mathbf{X}_v\) to the latent representations \(\mathbf{Z}_v\)
- ( use the ViT as \(\mathcal{F}\) )
- process
- step 1) embed visual patches
- step 2) add positional embeddings \(\mathbf{P}_v\)
- step 3) sends the combined embeddings into transformer blocks & generate \(\mathbf{Z}_v\)
b) Latent contextual regressor \(\mathcal{H}\)
- predicts the masked patch representations from \(\mathbf{Z}_v\)
- prediction ( = \(\mathbf{Z}_m\) ): constrained to align with the masked patch representations computed from encoder
-
( use a series of transformer blocks as \(\mathcal{H}\) )
- In this process, \(\mathbf{Z}_v\) are not updated
Initial queries \(\mathbf{Q}_m\) ( = mask queries )
-
mask tokens that are learned as model parameters
( = same for all the masked patches )
-
= Key & Value
c) Alignment constraint
- imposed on \(\mathbf{Z}_m\) ( predicted by \(\mathcal{H}\))
- feed the masked patches \(\mathbf{X}_m\) and generate \(\overline{\mathbf{Z}}_m\)
- alignment between…
- \(\mathbf{Z}_m\) and \(\overline{\mathbf{Z}}_m\)
d) Decoder
- maps \(\mathbf{Z}_m\) to the targets for masked patches \(\mathbf{Y}_m\)
- ( = stack of transformer blocks, based on self-attention )
(2) Objective Function
a) Masking & Targets
( following BEiT )
- adopt random block-wise masking stratregy
- for each image, 98 out of 196 (14x14) patches are masked
pre-trained DALL-E tokenizer
-
to generate discrete tokens for forming the targets
( = target tokens for maksed patches : \(\bar{\mathbf{Y}_m}\) )
b) Loss function
Loss = (1) decoding loss + (2) alignment loss
(1) decoding loss : \(\ell_y\left(\mathbf{Y}_m, \overline{\mathbf{Y}}_m\right)\) ….. CE loss
(2) alignment loss : \(\ell_z\left(\mathbf{Z}_m, \overline{\mathbf{Z}}_m\right)\) …. MSE loss
(3) total loss : \(\ell_y\left(\mathbf{Y}_m, \overline{\mathbf{Y}}_m\right)+\lambda \ell_z\left(\mathbf{Z}_m, \operatorname{sg}\left[\overline{\mathbf{Z}}_m\right]\right) .\)