
Contents
- Background
- PNN (Progressive Neural Network)
- HAT (Hard Attention to the Task)
- PackNet (Pruning-based Parameter Packing)
Background
Continual Learning (CL)의 필요성:
- Catastrophic Forgetting
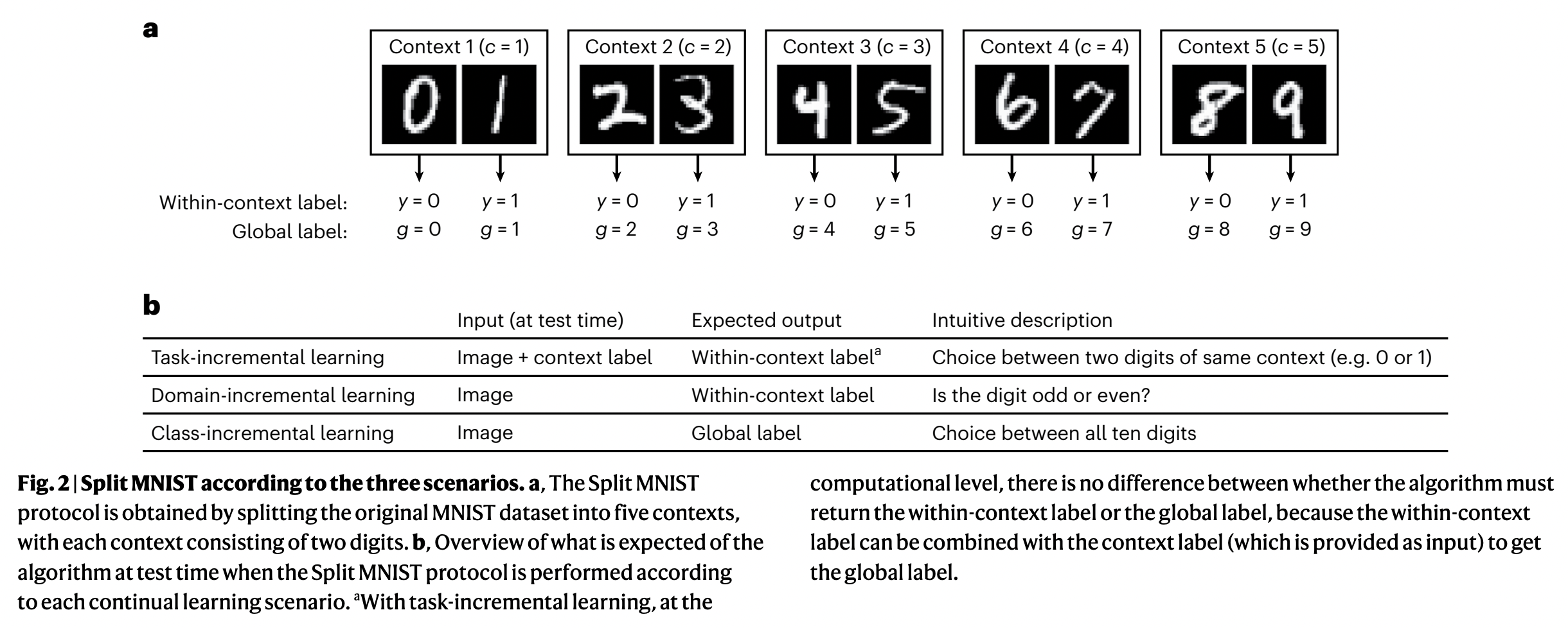
CL의 3가지 Scenario
- Task-Incremental Learning (Task-IL)
- Domain-Incremental Learning (Domain-IL)
- Class-Incremental Learning (Class-IL)
Frameworks
| 전략 종류 | 대표 기법 | 설명 |
|---|---|---|
| (1) Regularization-based | EWC, SI, MAS | param 이동 억제 |
| (2) Replay-based | ER, A-GEM, DER++ | 예전 데이터 (또는 생성 데이터) 재사용 |
| (3) Parameter isolation | PNN, HAT, PackNet | task별 서브네트워크 유지 |
| (4) Dynamic architecture | DEN, ExpandNet | 필요시 네트워크 구조 확장 |
1. PNN (Progressive Neural Network)
Rusu et al., “Progressive Neural Networks”, arXiv 2016
https://arxiv.org/abs/1606.04671
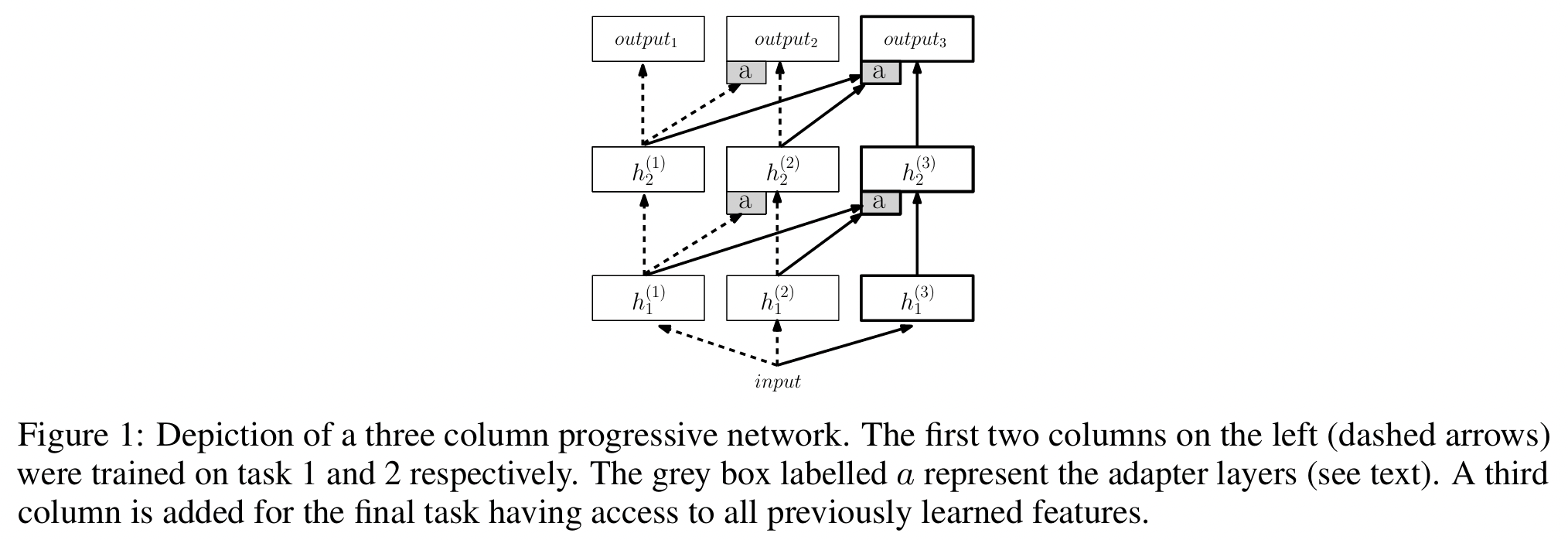
(1) Key Idea
매 새로운 task가 올 때마다,
새로운 네트워크(모듈)를 추가해서 학습하고,
이전 task의 네트워크는 고정(freeze)!
(+ 대신 이전 네트워크의 출력을 lateral connection으로 받아 활용)
(2) Mathematical Expression
\(h_l^{(k)} = f \left( W_l^{(k)} h_{l-1}^{(k)} + \sum_{j=1}^{k-1} U_l^{(k:j)} h_{l-1}^{(j)} \right)\).
- \(h_l^{(k)}\): task \(k\)의 layer \(l\) 출력
- \(W_l^{(k)}\): 현재 task의 주 weight
- \(U_l^{(k:j)}\): 이전 task \(j\)의 layer l-1 출력과의 lateral connection
- \(f\): 비선형 함수 (ReLU 등)
(3) Pros & Cons
Pros
- 완전한 망각 방지 (no forgetting)
- 이전 지식 재사용 가능 (lateral connection)
- 이론적으로 strong transfer 가능
Cons
- 확장성 문제: task마다 네트워크가 계속 늘어남 → 메모리/속도 비용 큼
- 추론 시 처리: 전체 Column이 동시에 필요 → latency 증가
2. HAT (Hard Attention to the Task)
Serra et al., “Overcoming Catastrophic Forgetting with Hard Attention to the Task”, ICML 2018
https://arxiv.org/abs/1801.01423
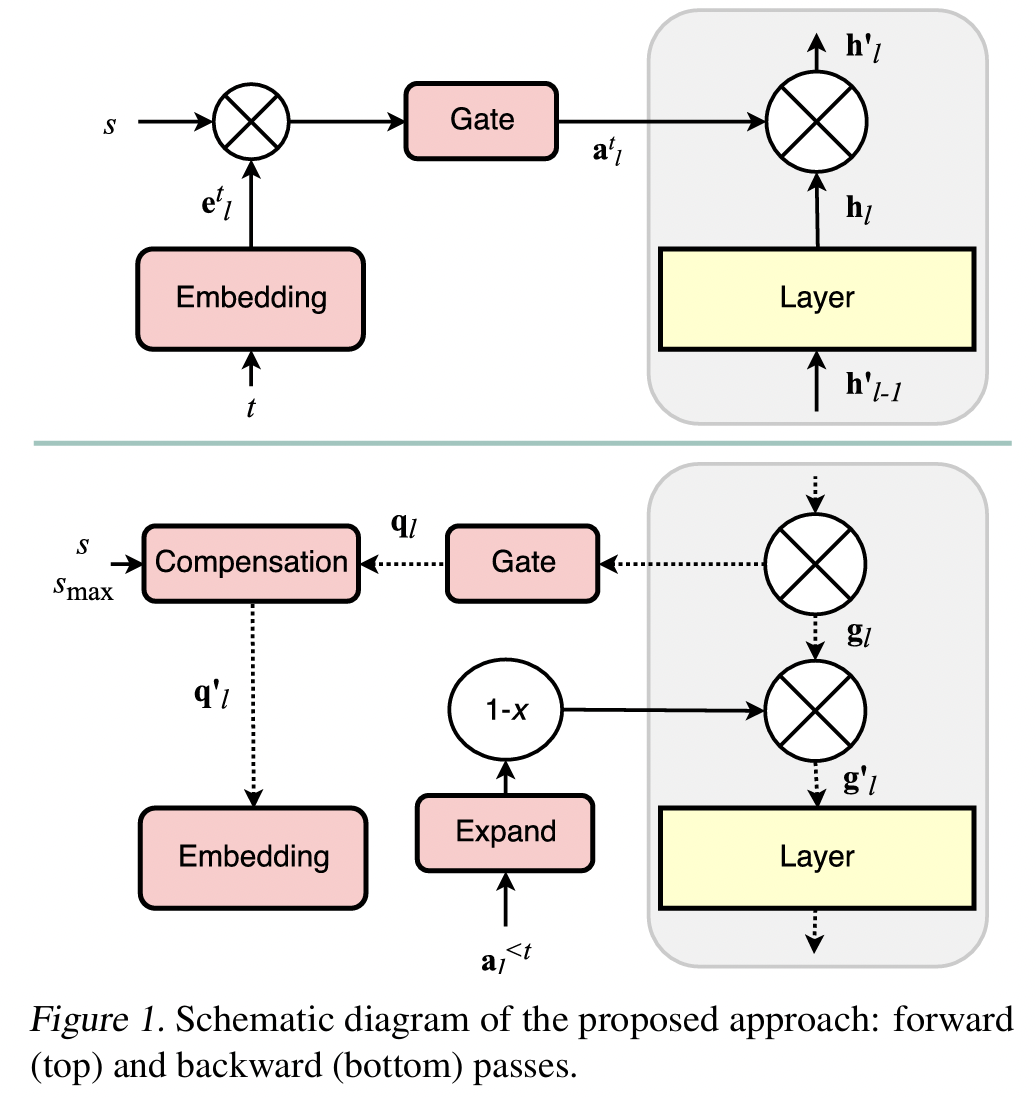
(1) Key Idea
매 task마다 어떤 param를 쓸지 선택하는 binary mask를 학습
선택된 param만 학습에 사용 + 이후 task에서는 고정!
→ param 간섭(interference)을 강하게 차단!
(2) Procedure
- Step 1) 매 task마다 layer마다 binary mask를 생성
- Step 2) 이 mask를 통해 네트워크 일부 param만 사용 + 업데이트
- Step 3) 학습이 끝나면, 해당 mask는 고정
- 이후 task에서는 이미 사용된 파라미터를 잠그고(freeze), 남은 param 중 일부만 새로 사용
(3) Layer-wise Hard Attention Mask
\(\tilde{a}_l^{(t)} = \sigma(s_l^{(t)}/T)\).
-
\(s_l^{(t)}\): 학습 가능한 attention score (task-specific)
-
\(\sigma\): Sigmoid with sharpening
\(\rightarrow\) 점점 0으로 수렴하도록 annealing하도록 temperature \(T\)
-
\(\tilde{a}_l^{(t)} \in [0,1]^d\): soft mask (추후 hard mask로 근사)
\(\theta_l \leftarrow \theta_l - \eta \cdot \nabla \mathcal{L} \cdot \tilde{a}_l^{(t)}\).
- mask에 따라 일부 param는 학습에서 제외됨
(4) PNN vs. HAT
| 항목 | HAT | PNN |
|---|---|---|
| param 분리 방식 | mask로 선택 | 네트워크 추가 |
| param 재사용 | 가능 (공유 안 된 부분만) | lateral connection 통해 재사용 |
| 메모리 사용량 | 고정됨 | task마다 증가함 |
(5) Code
# mask 생성
att_scores = nn.Parameter(torch.randn(hidden_size))
att_mask = torch.sigmoid(att_scores / temperature)
# param에 mask 적용
layer.weight.grad *= att_mask
- 학습이 끝나면 att_mask를 저장하고 고정
- 다음 task에서는 해당 부분 gradient zero
(6) Pros & Cons
Pros
- 망각 방지 + param 재사용 균형 있음
- 메모리 증가 없음 (단일 네트워크 유지)
- 선택된 param만 사용하기 때문에 안정적
Cons
- Task-specific mask가 필요 → Task-ID 알아야 함
- mask가 완전히 0/1로 수렴하도록 annealing 조절 필요
- 초기에 공유 param가 너무 적으면 transfer 저하 가능
3. PackNet (Pruning-based Parameter Packing)
Mallya & Lazebnik, “PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning”, CVPR 2018
https://arxiv.org/abs/1806.00562
(1) Key Idea
-
하나의 네트워크 안에 여러 task를 packing하는 방식
-
각 task를 학습한 뒤, 그 task에 필요한 param만 남기고 pruning
- 이후 task에서는 남은 param만 사용 가능
- 이전 task param는 고정(freeze)하여 망각 방지
즉, PackNet = 여러 task를 하나의 네트워크에 “채워넣기”
(2) Procedure
- Step 1) Task A 학습 → 전체 param 사용 가능
- Step 2) Pruning 수행 → 성능 유지하면서 사용된 중요 param만 남김
- Step 3) Pruned param는 고정(freeze) → 이후 학습에서 변경 금지
- Step 4) Task B 학습 → 남은 param로만 학습
- 반복: Task C, D…
(3) Iterative Pruning + Freezing
- Pruning 기준: weight magnitude (값이 작은 weight 제거)
- Freezing 방식: 이전 task가 사용한 weight는 gradient 차단
(4) Mathematical Expression
- 모델 weight: \(\theta\)
- task \(t\) 후의 중요 weight mask: \(m^{(t)} \in \{0,1\}^d\)
총 mask: \(m^{(1:t)} = \bigvee_{i=1}^t m^{(i)}\).
현재 task에서는 다음을 사용:
\(\theta^{(t+1)} = \text{train}(\theta \odot (1 - m^{(1:t)}))\).
- 이전 task에서 사용된 param는 고정, 새로운 task는 남은 param로 학습
(5) Code
# Step 1: Task A 학습
train(model)
# Step 2: pruning
mask_A = get_weight_mask(model, keep_ratio=0.5) # 중요도 기준 pruning
freeze_weights(model, mask_A)
# Step 3: Task B 학습
train(model, only_on=~mask_A) # 남은 weight만 사용
(6) Pros & Cons
Pros
- 단일 네트워크만 사용 → 메모리 효율적 (PNN과 반대)
- 완전한 망각 방지: 이전 param는 고정
- 이론적으로 task 수만큼 weight가 남아 있다면 계속 학습 가능
Cons
- param 소진: task가 많아지면 남은 weight 부족해짐
- Pruning hyperparameter 민감
- Task-ID 필요: 어떤 weight를 freeze해야 할지 알아야 함!
4. Comparison
| 항목 | PackNet | HAT | PNN |
|---|---|---|---|
| param 분리 | pruning | mask | column 분리 |
| 구조 확장 | ❌ 없음 | ❌ 없음 | ✅ 있음 |
| 망각 방지 | ✅ 강함 | ✅ 강함 | ✅ 완전 |
| 유연성 | 중간 | 높음 | 낮음 (확장 문제) |