
Active Learning (AL)
1. Introduction
-
배경: 높은 Labeling 비용
-
아이디어: Unlabeled data 중, labeling을 할 데이터를 능동적으로 선택
-
주요 특징 및 개념
-
Label Efficiency: 모든 데이터를 라벨링하지 않고도 성능 향상 가능.
-
Query Strategy: 모델이 가장 정보가 될 만한 데이터를 “질문”해서 라벨을 요청.
-
Iteration: 모델 학습 → informative sample 선택 → 라벨 요청 → 학습 반복.
-
2. 주요 쿼리 전략 (Query Strategies)
- Uncertainty Sampling
- 모델이 가장 불확실해하는 샘플 선택 (e.g., 가장 낮은 softmax confidence)
- Query by Committee (QBC)
- 여러 모델로 구성된 committee 간 예측 불일치가 큰 샘플 선택
- Expected Model Change / Expected Error Reduction
- 어떤 샘플을 학습하면 성능이 얼마나 향상될지를 예측하여 선택
- Core-set Approaches
- 데이터 분포 전체를 대표할 수 있는 샘플 집합 선택
3. Adversarial & Representation-aware Methods
기본 아이디어
단순한 uncertainty나 거리 기반 전략으로는 충분하지 않을 수 있기 때문에…
→ 모델이 어떤 샘플에서 내부 표현을 헷갈려 하는가 (e.g., 가장 취약한 지점은 어디인가)를 활용
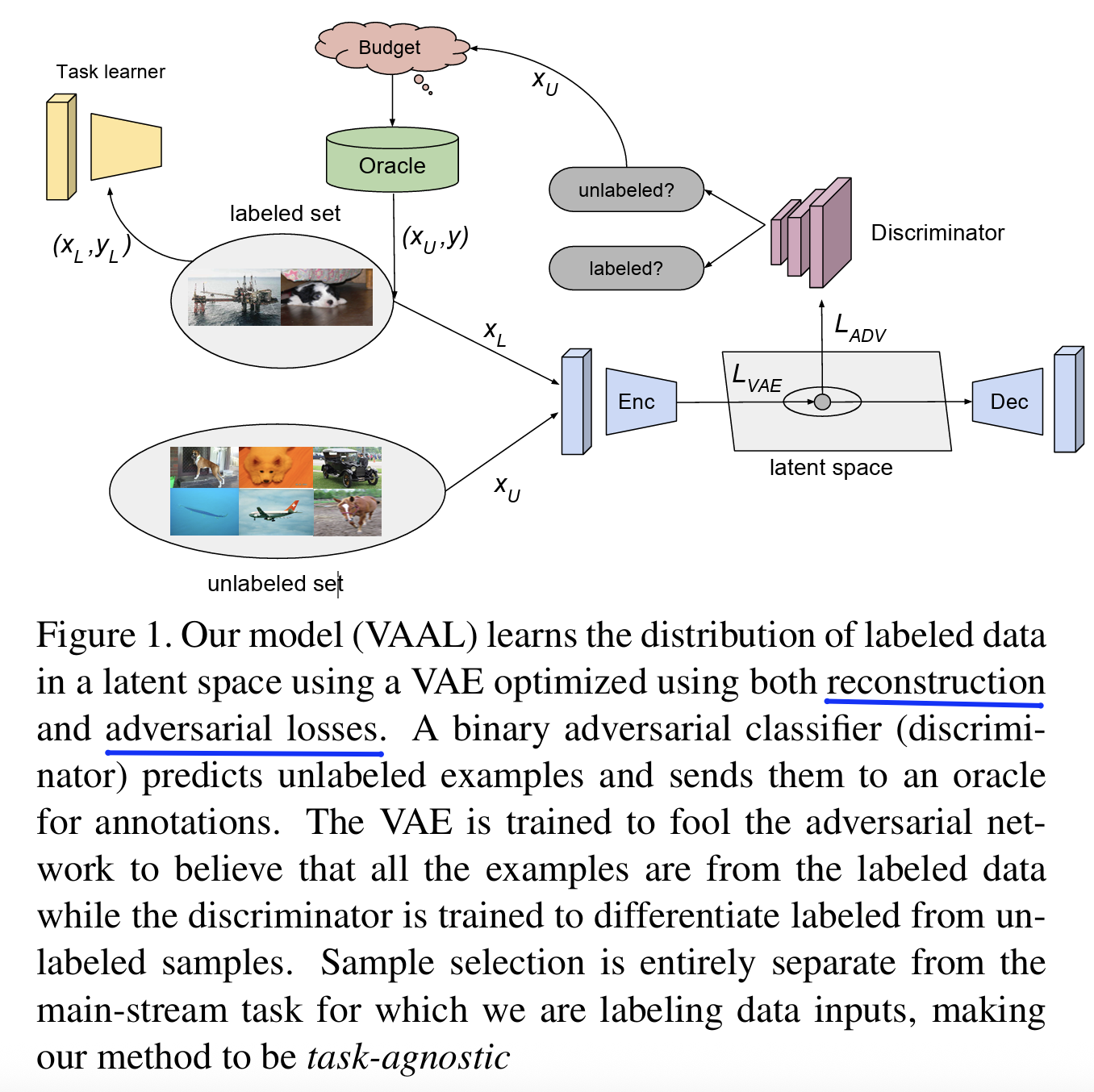
(1) VAAL: Variational Adversarial Active Learning
- https://arxiv.org/pdf/1904.00370
Sinha, Samarth, Sayna Ebrahimi, and Trevor Darrell. "Variational adversarial active learning." Proceedings of the IEEE/CVF international conference on computer vision. 2019.
한 줄 요약: “VAE + GAN 구조로 labeled & unlabeled 구분 → 구분 잘 안 되는 애들을 골라라!”
-
Intuition
- VAE는 unlabeled data에 대해서도 good representation 추출!
- D는 라벨 여부만으로 판단 → 헷갈리는 샘플 = “정보성 있음”으로 취급하장!
-
Components
- VAE: Encoder
- Discriminator (D): Labeled & Unlabeled 구분
- Query: D가 헷갈리는 샘플 선택
-
Procedure
- Training:
- VAE encoder + decoder 학습
- D 학습 (label 여부 구분)
- Inference
- unlabeled set 중 D가 혼동하는 샘플 top-K 선택
- Training:
-
장/단점
- 장점: task-agnostic
- 단점: GAN의 학습 불안정성
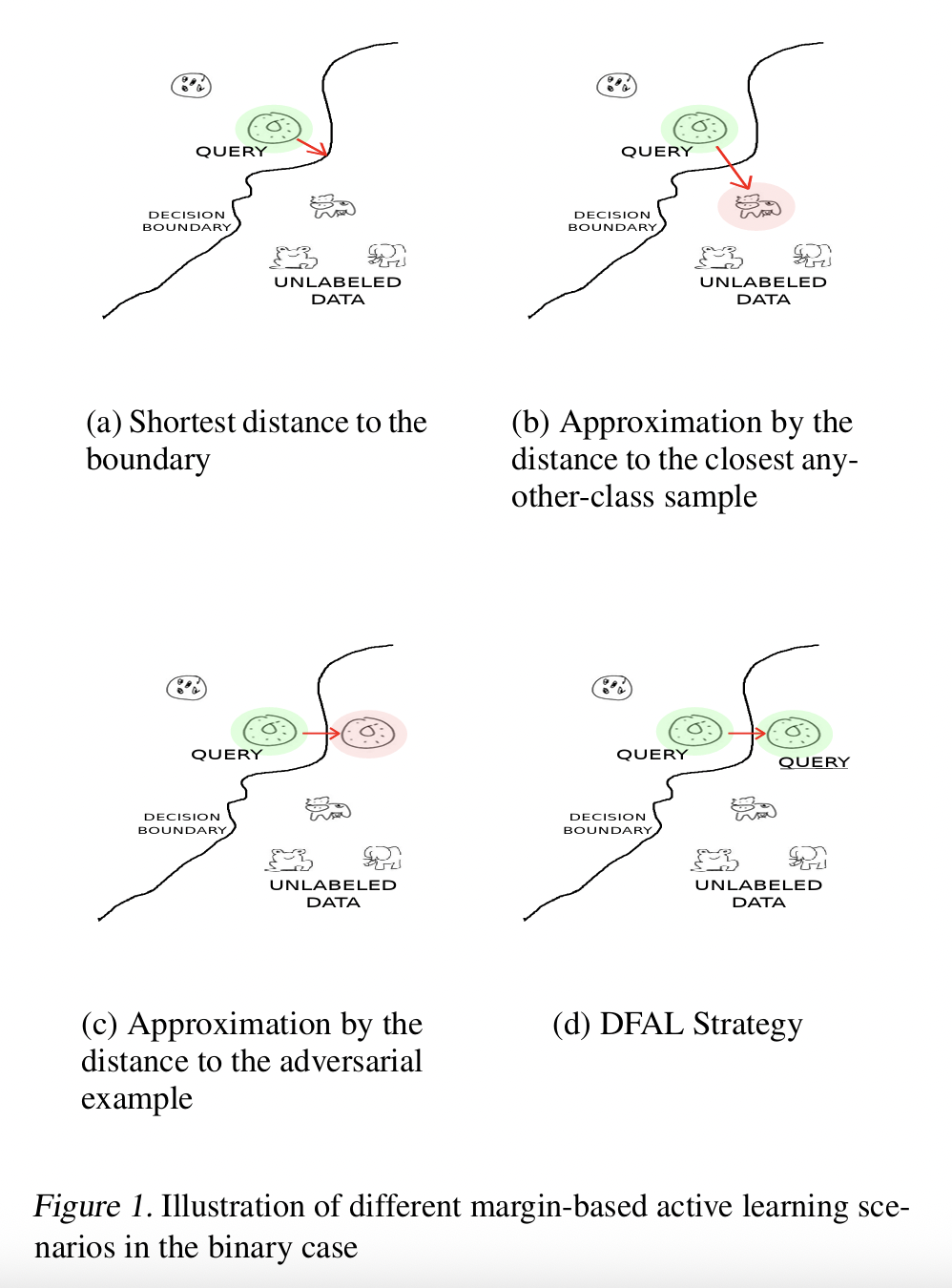
(2) Adversarial Querying (Gradient-based)
- https://arxiv.org/pdf/1802.09841
Ducoffe, Melanie, and Frederic Precioso. "Adversarial active learning for deep networks: a margin based approach." arXiv preprint arXiv:1802.09841 (2018).
한 줄 요약: “모델이 가장 취약한, perturbation에 민감한 데이터를 선택”
-
특정 샘플에 작은 노이즈를 줬을 때, 모델 출력이 크게 변하면 → 불안정 → 정보 많음
-
주요 방식
-
Adversarial Margin Sampling
- adversarial perturbation을 주고, 출력 margin 감소를 측정
- margin 감소량이 큰 샘플 선택!
-
Gradient Norm
-
입력 \(x\)에 대한 loss gradient \(\mid \mid \nabla_x \mathcal{L}(f(x), y) \mid \mid\)이 큰 샘플
-
모델이 “불안정하게 반응”하는 지점 = informative
-
-
-
장/단점
- 장점: Model의 generalization 키움
- 단점: Gradient 연산 비용
(3) Representation-aware Diversity Sampling
한 줄 요약: “Representation space 상에서 다양한 방향에 있는 샘플을 고르게 선택”
-
단순한 L2 거리 기반 k-Center와 달리, representation의 distn를 더 정교하게 분석
-
주요 방식
-
Gradient Embedding Matching (GEM)
-
각 샘플이 loss gradient를 얼마나 많이 변화시키는지 측정
-
다른 샘플들과 orthogonal한 gradient를 가지는 샘플을 선택 (정보 보완적)
-
-
Contrastive Core-set
-
embedding space에서 anchor-positive-negative 구조를 활용해 diversity 확보
-
핵심: “현재 labeled set에서 가장 다른 샘플 찾기”
-
-
Prototype-based Sampling
- 각 cluster centroid을 기준으로 거리 기반 선택
-
-
장/단점
-
장점:
-
다양한 표현 영역을 반영 → redundancy 방지
-
self-supervised 기반 pretraining과 매우 잘 어울림
-
-
단점:
- embedding quality에 민감
-