
(참고: Fastcampus 강의, 강민철의 인공지능 시대 필수 컴퓨터 공학 지식)
4. 컴퓨터 구조 - CPU
Contents
- CPU의 구성 요소
- 명령어 사이클 & 인터럽트
- 멀티 코어와 멀티 프로세서
- 명령어 병렬 처리: 파이프라이닝
- 비순차적 명령어 처리
(1) CPU의 구성 요소
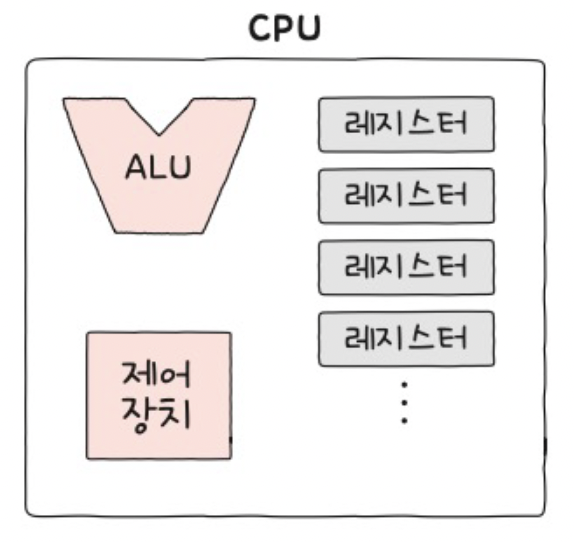
- ALU (산술 논리 연산 장치) = 연산을 수행하기 (계산하기)
- 제어 장치 = 명령어 해석 & 제어 신호 내보내기
- 레지스터(들) = 명령어 전/후로 임시 저장
a) ALU
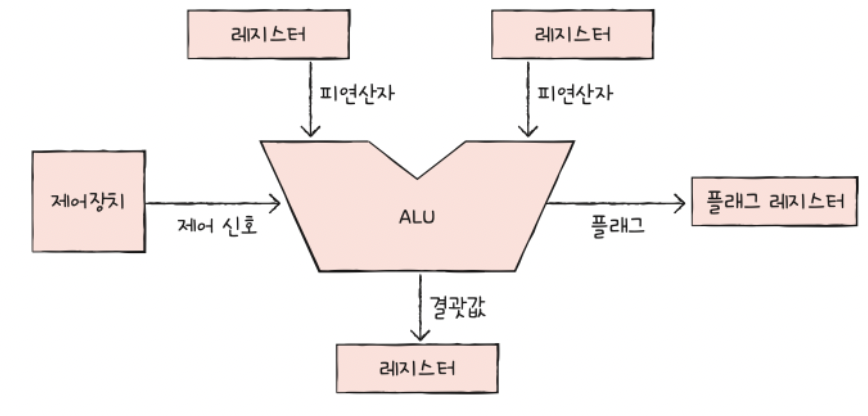
연산 과정
-
(레지스터로부터) “피연산자 (= 연산 대상)” 받아들임
(제어 장치로부터) “제어 신호 (= 연산 작업)” 받아들임
- 연산을 수행함
- 연산의 결과를 레지스터 (+ 플래그 레지스터)에 저장함
플래그 레지스터
- 연산의 결과에 대한 부가 정보
- ex) 부호 / 제로 / 캐리 / 오브펄로우 / 인터럽트 / 슈퍼바이저 플래그
b) 제어 장치
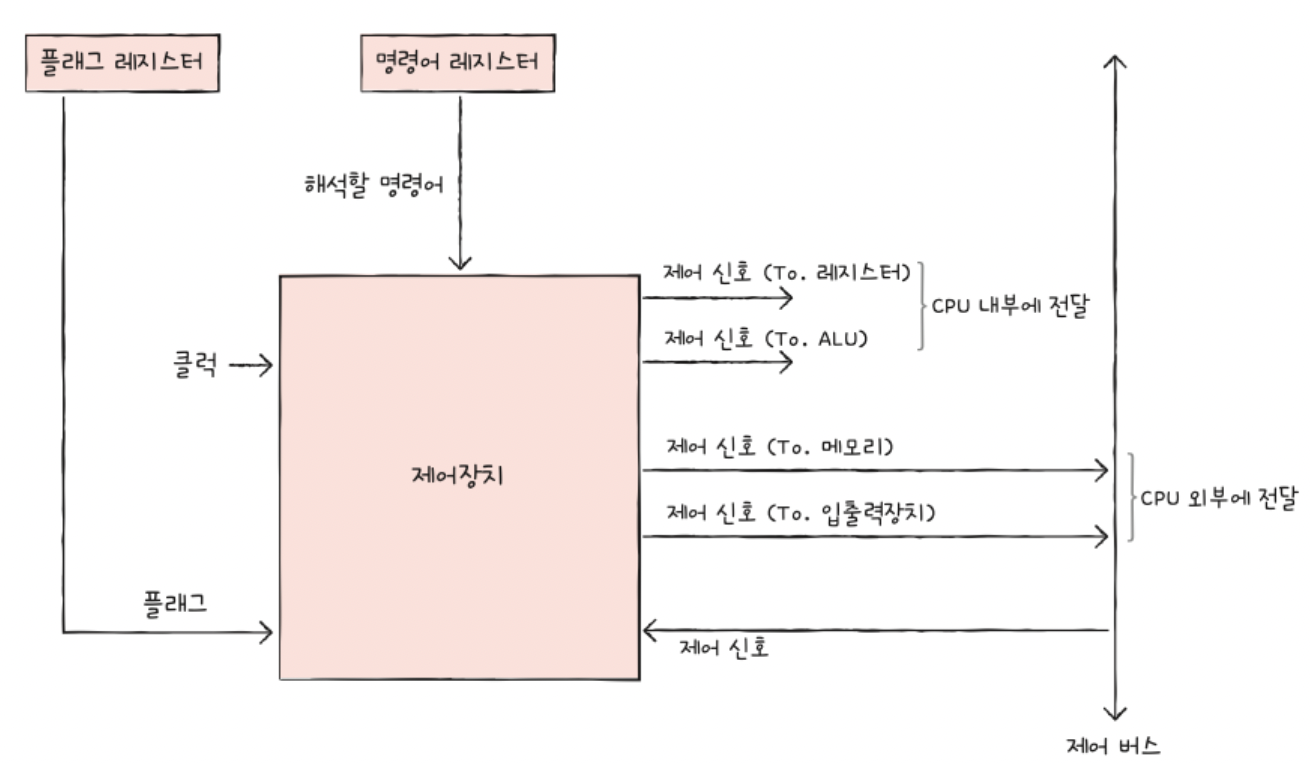
역할: 제어 신호를 내보내고, 명령어를 해석
세 가지를 입력받은 뒤, 제어신호를 뱉음
- (1) 해석할 명령어 (from 명령어 레지스터)
- (2) 플래그 (from 플래그 레지스터)
- (3) 클럭 신호 = 부품이 움직이는 “박자”
c) 레지스터
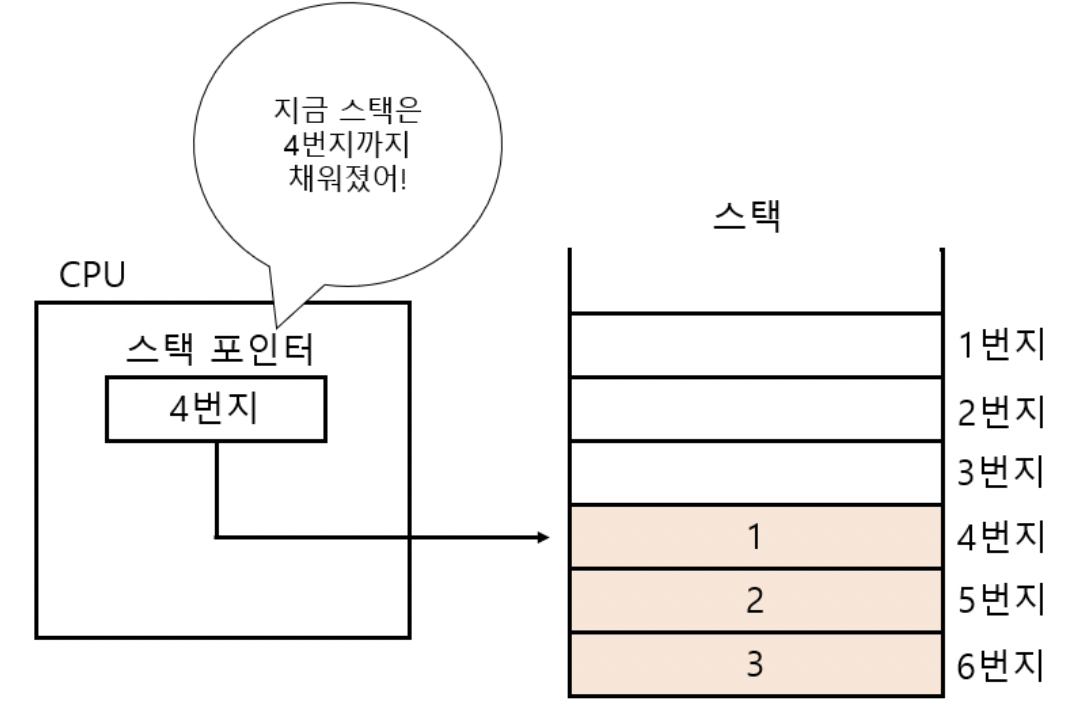
프로그램 실행 전/후로 값을 임시 저장하는 작은 저장 장치
- “프로그램 카운터” = 메모리에서 가져올 명령어 주소 (메모리에서 읽어들일 주소)
- 일반적으로 1씩 증가 (메모리의 프로그램이 순차적으로 증가)
- “명령어” 레지스터 = 해석할 명령어 (메모리에서 읽어들인 주소)
- “메모리 주소” 레지스터 = 메모리의 주소 (읽어들일 주소 값)
- “메모리 버퍼” 레지스터 = 메모리와 주고받을 명령어와 데이터
- “플래그” 레지스터 = 연산 결과에 대한 부가 정보 저장
- “범용” 레지스터 = 범용적으로 사용 가능한 레지스터 (여러 개 있음)
- “스택 포인터” = ‘스택의 꼭대기’를 가리키는 레지스터 (스택 주소 지정 방식에서 사용)
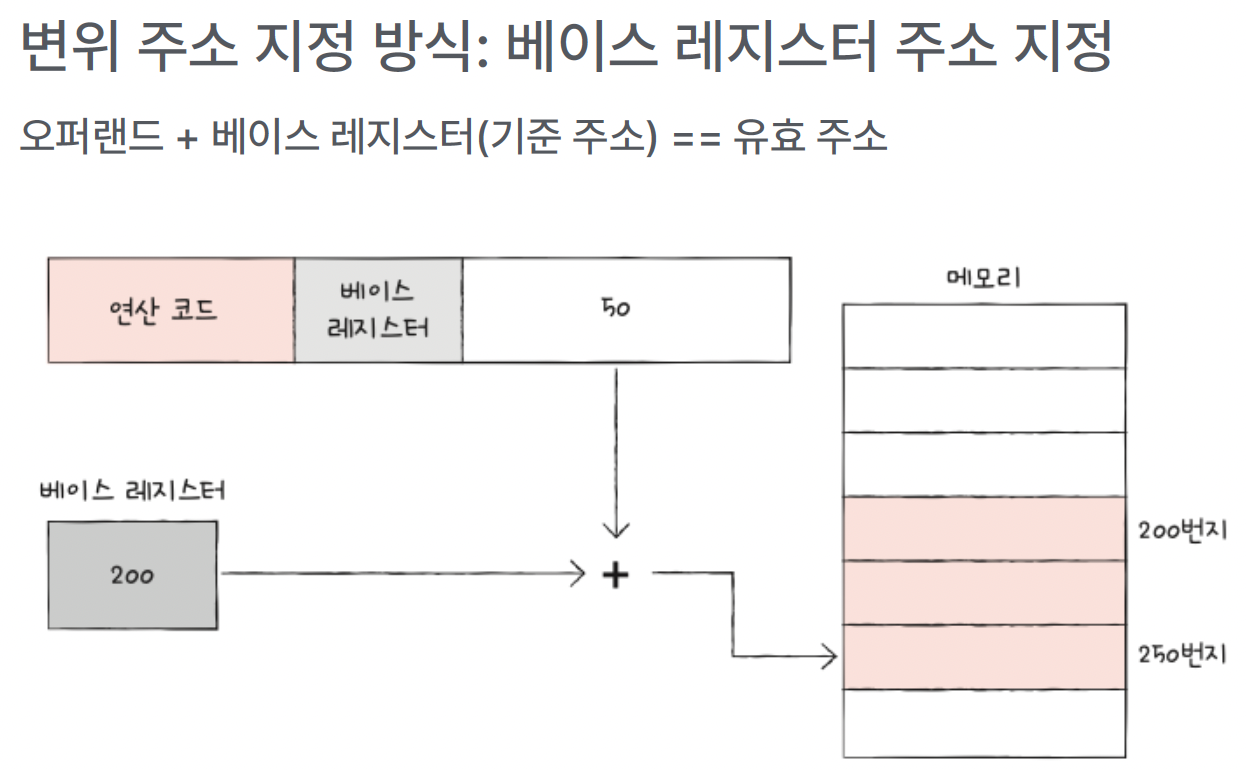
- “베이스” 레지스터 = ‘떨어진 거리’를 가리키는 레지스터 (변위 주소 지정 방식에서 사용)
| 항목 | 스택 주소 지정 | 변위 주소 지정 |
|---|---|---|
| 기준 | 스택 포인터(SP) | 베이스 레지스터 + 변위 |
| 주소 명시 | 불필요 | 명시적 (offset 사용) |
| 사용 용도 | 함수 호출, 임시 저장 등 | 배열, 구조체, 지역 변수 접근 |
| 유연성 | 낮음 | 높음 |
(2) 명령어 사이클 & 인터럽트
a) 명령어 사이클
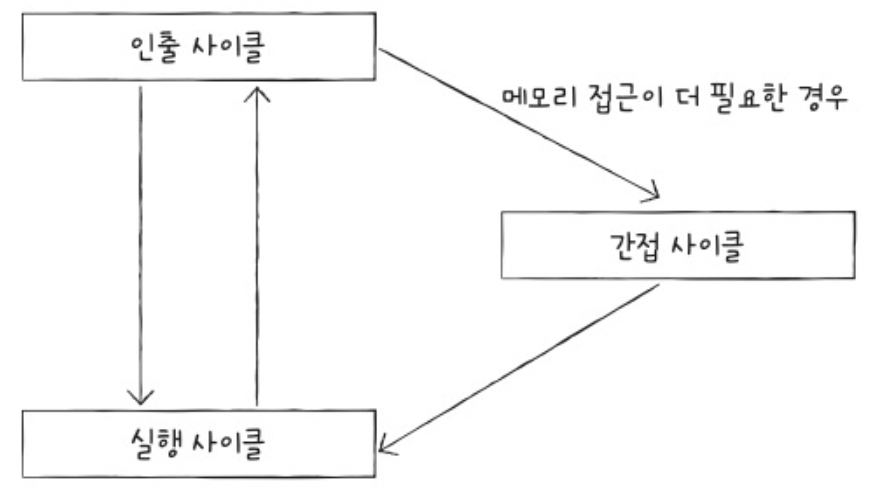
CPU가 명령어를 순차적으로 처리하는 양상
- (1) 인출 사이클
- (2) 실행 사이클
Procedure
- 메모리에서 명령어를 가져오고 (인출하고),
- 가져온 명령어를 실행하고,
- 메모리에서 명령어를 가져오고 (인출하고)
- 가져온 명령어를 실행하고,
- ..
기타: (3) 간접 사이클
-
간접 주소 지정 방식 때문에, 실제 데이터를 얻기 전에 주소가 저장된 메모리에 한 번 더 접근하는 과정
-
상세 설명
- 어떤 명령어에 직접 데이터가 있는 게 아니라, 데이터의 주소가 저장된 메모리 주소를 가리키는 경우가 있음
- 이때, 먼저 그 주소 값을 메모리에서 꺼내온 다음에야 진짜 데이터를 읽을 수 있음
- 이 중간 주소를 얻는 과정이 바로 간접 사이클(indirect cycle)
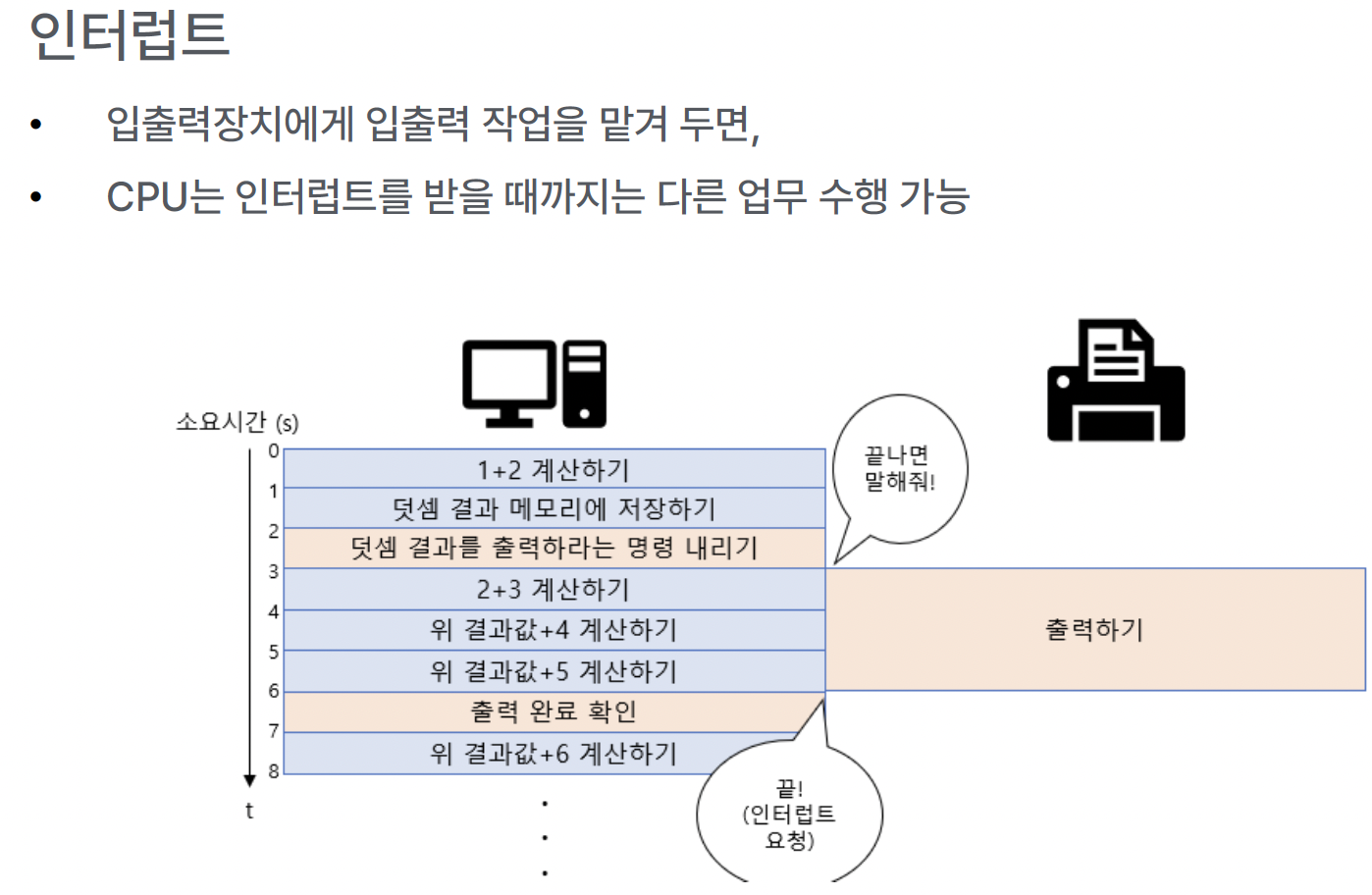
b) 인터럽트
- (1) 동기 인터럽트 (예외, Exception)
- 주로 CPU에 의해 발생
- 명령어 처리 도중, 비정상적인 상황 마주함
- 비유: 프로그램이 “내가 잘못해서 멈춘 것”
- (2) 비동기 인터럽트 (하드웨어 인터럽트)
- 주로 입출력장치에 의해 발생
- 비유: “밖에서 누가 불러서 잠깐 멈춘 것”
| 구분 | 동기 인터럽트 (Synchronous) | 비동기 인터럽트 (Asynchronous) |
|---|---|---|
| 발생 시점 | 명령어 실행 중에 예측 가능한 순간 | 명령어 실행과 무관하게 예측 불가능한 순간 |
| 원인 | 프로그램 내부 원인 (예: 0으로 나누기, 잘못된 접근) | 외부 장치 원인 (예: 키보드 입력, 타이머 완료) |
| 처리 시점 | 현재 명령어 완료 후 바로 처리됨 | 현재 명령어와 무관하게 언제든지 발생 가능 |
| 예시 | 산술 오버플로, 잘못된 메모리 접근 등 | I/O 완료, 네트워크 패킷 도착, 하드웨어 신호 등 |
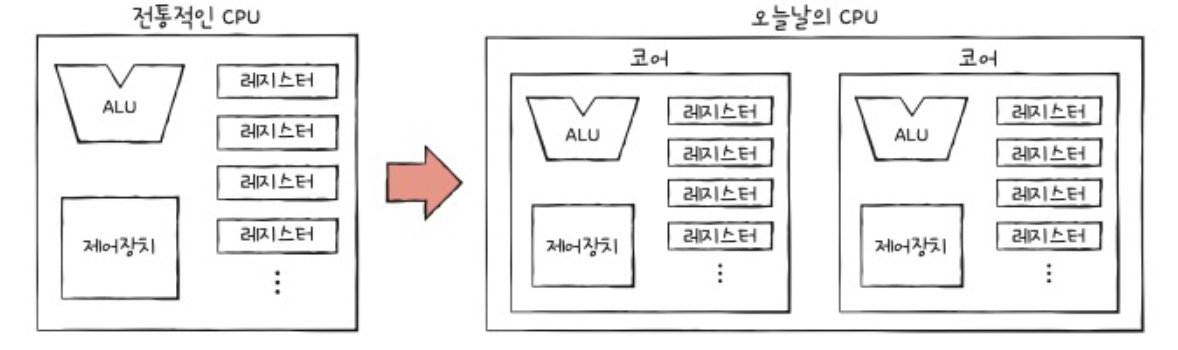
(3) 멀티 코어와 멀티 프로세서
멀티 코어
멀티 프로세스
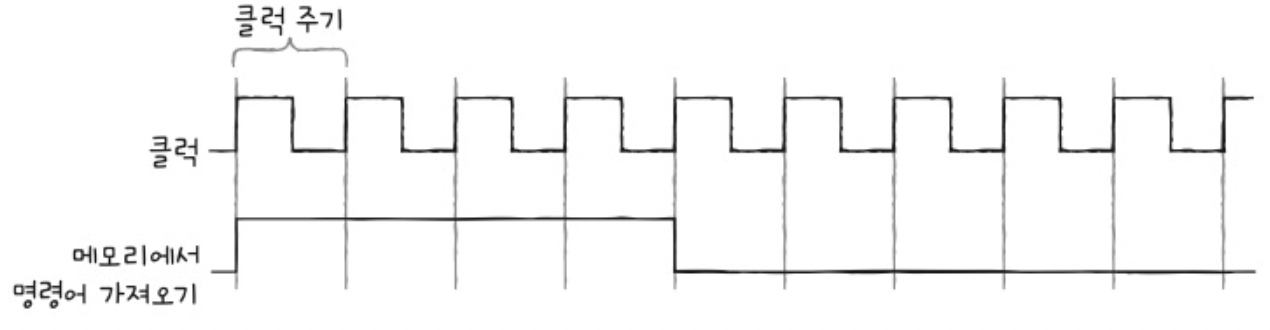
컴퓨터 부품: “클럭 신호”에 맞게 움직임.
- CPU는 클럭 신호에 따라 명령어 사이클에 맞춰 명령어를 실행
\(\rightarrow\) 클럭 속도가 높은 CPU가 대체로 성능이 좋다
클럭 속도 (Hz) = 1초에 반복된 클럭의 횟수로 측정
- 1GHz = \(10^9\) Hz
a) CPU 오버 클러킹
- 임의로 클럭 속도 끌어올리는 기술
- 부팅 시, BIOS에서 설정 가능
\(\rightarrow\) 무조건 높이는 것이 좋나? No! 발열 issue!
b) 코어 & 멀티 코어
클럭 수 높이는 것 외에….다른 방법은?
\(\rightarrow\) 멀티 코어 프로세서! (=코어 수 늘리기)
- 코어: 명령어 인출/해석/실행하는 CPU의 핵심 부품
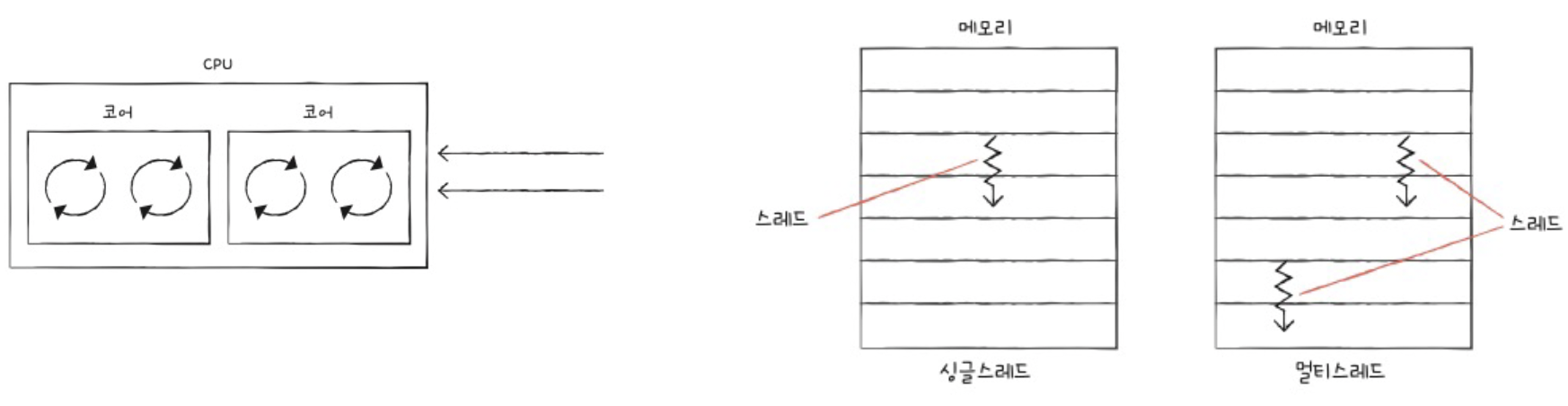
c) 스레드 & 멀티 스레드
스레드의 용어 정리
- “하드웨어”의 스레드: 하나의 코어가 동시에 처리하는 명령어 단위
- “소프트웨어”의 스레드: 하나의 프로그램을 독립적으로 실행하는 단위
멀티 스레드 CPU
= 여러 개의 (하드웨어의) 스레드를 1개의 코어로!
- 대신, 그만큼 복수의 레지스터 세트 필요!
(하드웨어의) 스레드 = 논리 프로세서
-
메모리/프로그램 입장에서는, 스레드와 코어 구분 X
(즉, 각 하드웨어를 마치 하나의 단일 스레드/코어 프로세서로 인식 )
(4) 명령어 병렬 처리: 파이프라이닝
a) CPU 성능 높이기
- a) 높은 클럭 수
- b) 멀티 코어
-
c) 멀티 프로세서
- d) 명령어 병럴 처리 \(\rightarrow\) “명령어 파이프라이닝”
b) 명령어 파이프라이닝
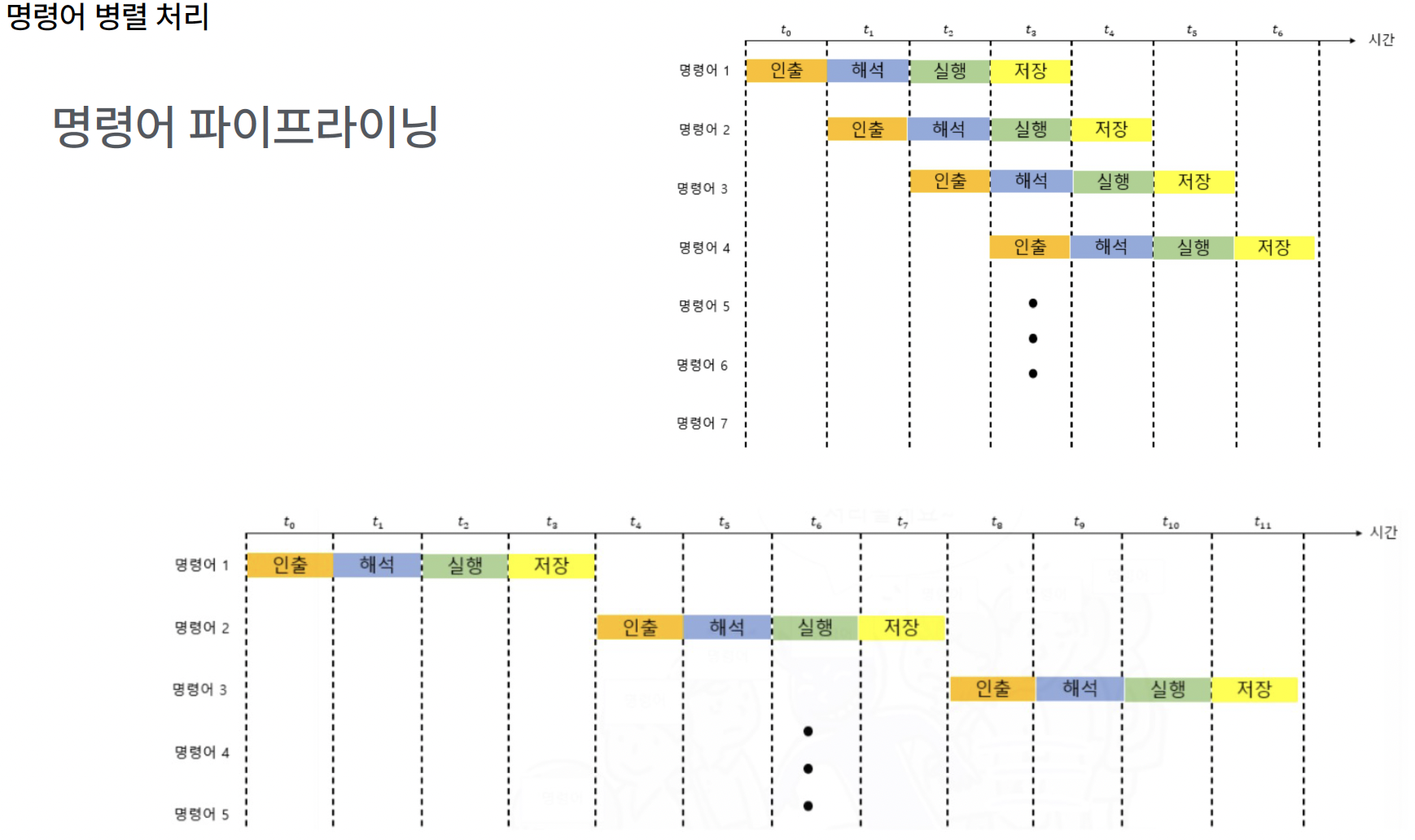
하나의 명령어가 처리되는 과정을 나누자면?
- 명령어 “인출”
- 명령어 “해석”
- 명령어 “실행”
- 명령어 “저장”
\(\rightarrow\) 위의 4가지는 겹치지 않는 한, 동시에 실행 가능!
- ex) 작업 A의 명령어 인출 & 작업 B의 명령어 해석 & 작업 C의 명령어 실행 ..
c) 파이프라인 위험 (Pipeline hazard)
파이프라이닝이 불가능한 (실패하는) 경우는?
- 데이터 위험 (Data hazard)
- “명령어 간 의존성” 때문에 동시 실행 불가!
- case 1) RAW (Read After Write): 데이터가 쓰여진 직후, 그 데이터를 읽는 경우
- 명령어 1: R1 <- R2 + R3
- 명령어 2: R4 <- R1 + R5
- case 2) WAW (Write After Write): 데이터를 쓴 직후, 그 데이터에 새 내용을 쓰는 경우
- 명령어 1: R1 <- R2 + R3
- 명령어 2: R1 <- R4 + R5
- case 3) WAR (Write After Read): 데이터를 읽어들인 직후, 그 데이터에 새 내용을 쓰는 경우
- 명령어 1: R3 <- R1 + R2
- 명령어 2: R1 <- R4 + R5
- 제어 위험 (Control hazard)
- 프로그램 카운터에 갑작스러운 변화에 의해 발생 (분기)
- e.g., 60번지로 분기합니다!
- 프로그램 카운터에 갑작스러운 변화에 의해 발생 (분기)
- 구조적 위험 (Structural hazard)
- 서로 다른 명령어가 같은 자원을 사용하려 하는 경우 발생
d) 슈퍼 스칼라
다수의 명렁어 파이프라인
- 여러 명령어를 동시에 인출/해석/실행/저장이 가능한 CPU
e) 파이프라이닝을 십분 활용하기 위한 CPU 구조
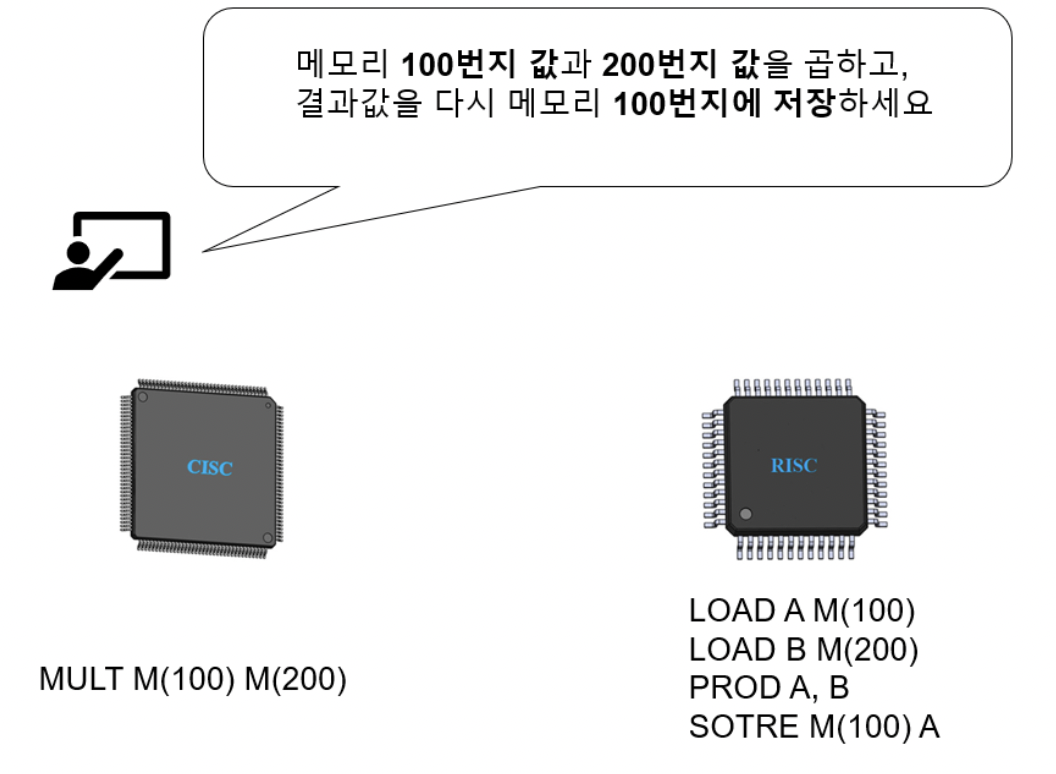
CISC vs. RISC
CISC (Complex Instruction Set Computer) … e.g., Intel x86 CPU
-
장점
- 복잡 & 다양한 기능의 명령어 (+ 다양한 주소 지정 방식 제공)
- 적은 명령어 수로 메모리 아껴가며 명령어 실행 가능
-
단점
-
명령어 별 일정하지 않은 클록 수 \(\rightarrow\) 파이프라이닝에 불리
-
대부분의 명령어가 실질적으로 사용 X
( CISC 명령어 중 20% 정도의 명령어가 전체 명령어의 80%를 차지 )
-

RISC (Reduced Instruction Set Computer) … e.g., ARM CPU
-
장점
- 짧고 & 규격화된 명령어 \(\rightarrow\) 파이프라이닝에 유리
- 메모리 접근 최소화 (레지스터 활용)
-
단점
-
적은 수의 명령어만을 제공 \(\rightarrow\) CISC이 비해 더 많은 명령어로 실행
(따라서, 컴파일러 역할이 더 중요해짐)
-
최근 트렌드:
- (1) RISC 같은 CISC
- (2) CISC 같은 RISC
| 구분 | CISC (Complex Instruction Set Computer) | RISC (Reduced Instruction Set Computer) |
|---|---|---|
| 명령어 세트 크기 | 큼 (복잡하고 다양한 수) | 작음 (단순하고 적은 수) |
| 명령어 실행 시간 | 여러 사이클 (명령어마다 다름) | 대부분 한 사이클 (고정된 시간) |
| 명령어 복잡도 | 복잡함 | 단순함 |
| 하드웨어 설계 | 복잡 (명령어 해석이 어려움) | 단순 (명령어 해석이 쉬움) |
| 메모리 접근 | 메모리 접근 빈번 (명령어 안에 포함됨) | 메모리 접근 최소화 (Load/Store 아키텍처) |
| 코드 크기 | 더 작음 (한 명령어가 많은 작업 수행) | 더 큼 (명령어 수가 많아짐) |
| 최적화 방향 | 하드웨어 최적화 | 소프트웨어(컴파일러) 최적화 |
| 대표 예시 | x86, Intel 8086, VAX | ARM, MIPS, RISC-V |
(5) 비순차적 명령어 처리
명령어 파이프라인의 성능을 더 높이는 법은?
\(\rightarrow\) “비순차적” 명령어 처리 (“Out-of-Order” Execution)
- 즉, “의존 관계가 없는” 명령어를 굳이 “순차적으로 처리하지 않는” 방법
예시:
1. a = load(memory_address) (메모리 읽기 → 지연 발생)
2. b = 2 * 3 (곱셈 → 바로 계산 가능)
3. c = d + e (d, e 레지스터에 이미 있음)
한 줄 요약:
- 순서를 바꿔도 프로그램 실행에 문제 없는 것은 바꿔서 처리 함으로써, 더 빠르게 처리하자!