
(참고: Fastcampus 강의, 강민철의 인공지능 시대 필수 컴퓨터 공학 지식)
5. 컴퓨터 구조 - 메인 메모리 & 캐시 메모리
Contents
- RAM과 ROM
- 리틀 엔디안 & 빅 엔디안
- 논리 주소 & 물리 주소
- 저장 장치 계층 구조 & 캐시 메모리
(1) RAM과 ROM
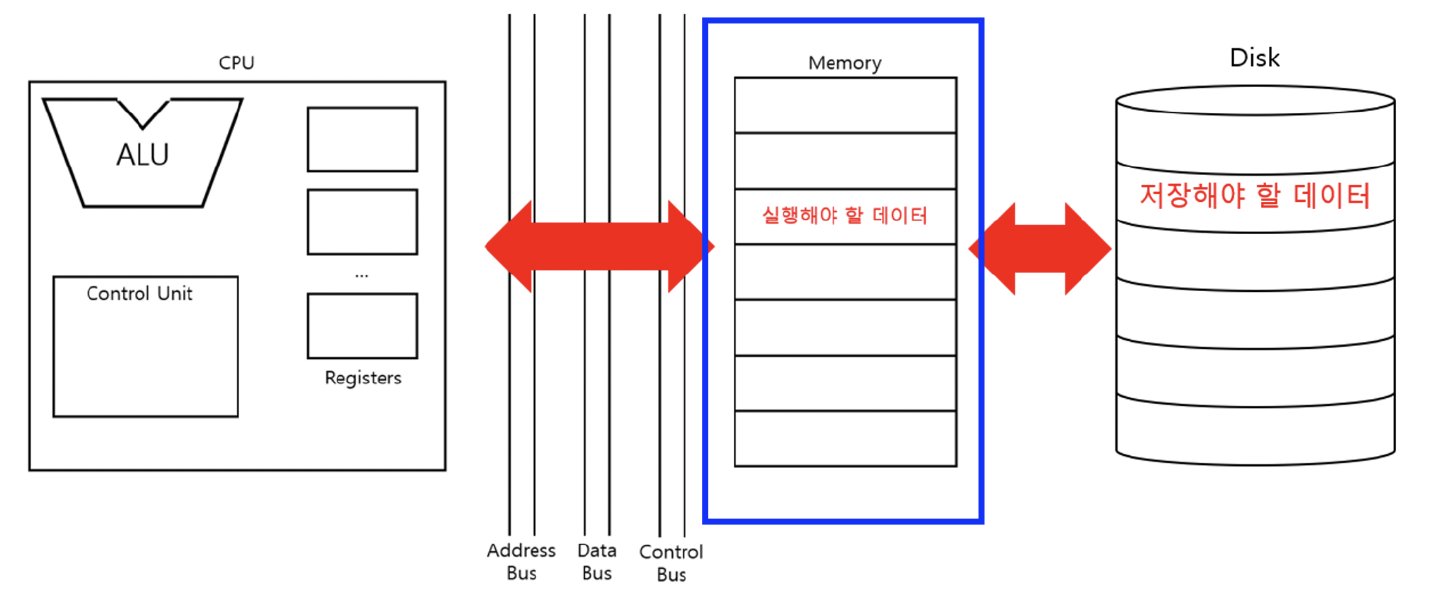
메인 메모리로 사용되는 2개의 하드웨어
- (1) RAM (Random Access Memory)
- (2) ROM (Read Only Memory)
( 주로 (메인) 메모리라고하면, 위의 (1) RAM을 이야기하는 경우가 많다 )
a) RAM의 핵심 특징
- (1) “휘발성” 저장장치 ( \(\leftrightarrow\) 디스크: “비휘발성” 저장장치 )
- (2) RAM의 크기 = 곧 성능
- RAM이 크다 = 많은 프로그램을 동시에 빠르게 실행할 수 있다
- (3) RAM의 종류
- DRAM, SRAM, SDRAM, DDRSDRAM
b) RAM의 종류
-
(1) DRAM (Dynamic)
- “메인 메모리”에서 주로 사용
- 시간이 지나면서 점차 사라짐 O
-
(2) SRAM (Static)
- “캐시 메모리”에서 주로 사용
- 시간이 지나도 저장된 데이터가 사라지지 X
-
(3) SDRAM (Syncrhonous + DRAM)
-
클럭과 동기화된 DRAM
(즉, 클럭의 타이밍에 맞게 CPU와 정보를 주고 받음)
-
-
(4) DDRSDRAM (Double Data Rate + SDRAM)
- 대역폭을 넓혀 속도를 높인 SDRAM
c) 요약
| 항목 | DRAM | SRAM |
|---|---|---|
| 속도 | 느림 | 빠름 |
| 가격 | 저렴 | 비쌈 |
| 집적도 | 높음 | 낮음 |
| 전력 소비 | 낮음 | 높음 |
d) ROM의 종류
ROM = 비석과도 같은 장치
(한번 기록 후, 수정 X)
- e.g., 냉장고, 전자레인지, 등의 가전제품에서 많이 사용
ROM의 종류
- (1) MaskROM
- 가장 기본적인 형태의 ROM
- 제조 과정에서 저장할 내용 미리 기록
- (2) PROM (Programmable ROM)
- (1회에 한해) 사용자가 직접 원하는 데이터를 새길 수 있는 ROM
- (3) EPROM (Erasable PROM)
- 지우고 다시 저장 가능한 PROM
- 지우는 방법: 자외선 (UVEPROM) 혹은 전기 (EEPROM)
- (4) 플래시 메모리
- EEPROM의 발전된 반도체 기반의 저장장치
- 보조기억장치로도 사용 (USB, SD카드, SSD)
(2) 리틀 엔디안 & 빅 엔디안
핵심: 메모리에 데이터를 넣는 순서
기초적 내용
- 메모리는 “바이트” 단위로 저장
- CPU로부터 메모리가 받아들이는 데이터는 4바이트 (32비트) 혹은 8바이트 (64비트) 워드 단위
- 1 바이트씩 저장하는 경우:
- 4바이트 데이터는 4개의 주소에 걸쳐 저장
- 8바이트 데이터는 8개의 주소에 걸쳐 저장
엔디안 = 메모리를 넣는 순서
- (Notation) 1A2B3C4D -> 1A / 2B / 3C / 4D로 나눠서 4개의 주소에 걸쳐 저장
-
연속해서 저장해야하는 바이트를 저장하는 순서
- 두 종류
- 빅 엔디안
- 리틀 엔디안
a) 빅 엔디안
-
“낮은” 번지 주소부터 “상위” 바이트부터 저장하는 방식
- 상위 바이트 = 수를 이루는 가장 큰 값
-
e.g., 1A2B3C4D에서 최상위 바이트 = 1A
따라서, 1A \(\rightarrow\) 2B \(\rightarrow\) 3C \(\rightarrow\) 4D 순으로 저장
b) 리틀 엔디안
-
“낮은” 번지 주소부터 “하위” 바이트부터 저장하는 방식
- 하위 바이트 = 수를 이루는 가장 작은 값
-
e.g., 1A2B3C4D에서 최하위 바이트 = 4D
따라서, 4D \(\rightarrow\) 3C \(\rightarrow\) 2B \(\rightarrow\) 1A 순으로 저장
c) 빅 & 리틀 엔디안의 장점
빅 엔디안
- 일상 체계와 동일한 순서 \(\rightarrow\) 메모리 값을 직접 읽기 편리 (쉬운 디버깅)
- 오늘 날, 데이터 송수신 시, 엔디안 특별히 고려 X 이유? “빅 엔디안”으로 통일!
리틀 엔디안
- 수치 계산 (자리 올림 등)이 편리
(3) 논리 주소 & 물리 주소
a) 주소의 필요성
(복습) CPU, 메모리, 프로그램
- 실행 중인 프로그램이 적재되는 메모리 주소는 “시시때때 바뀔 수 있음”
- 같은 프로그램 두번 실행 시, “다른 메모리에 적재될 수 있음”
Q) CPU/메모리는, 메모리 몇 번지에 무엇이 저장되어있는지 알 고 있나?
A) No!
\(\rightarrow\) 그렇다면, 어떻게 찾지??
b) 논리 주소와 물리 주소
주소 체계의 두 종류
- (1) 논리 주소 = 실제 메모리의 “하드웨어 상”의 주소
- (2) 물리 주소 = CPU & 실행 중인 프로그램이 사용하는 주소 (0번지부터 시작)
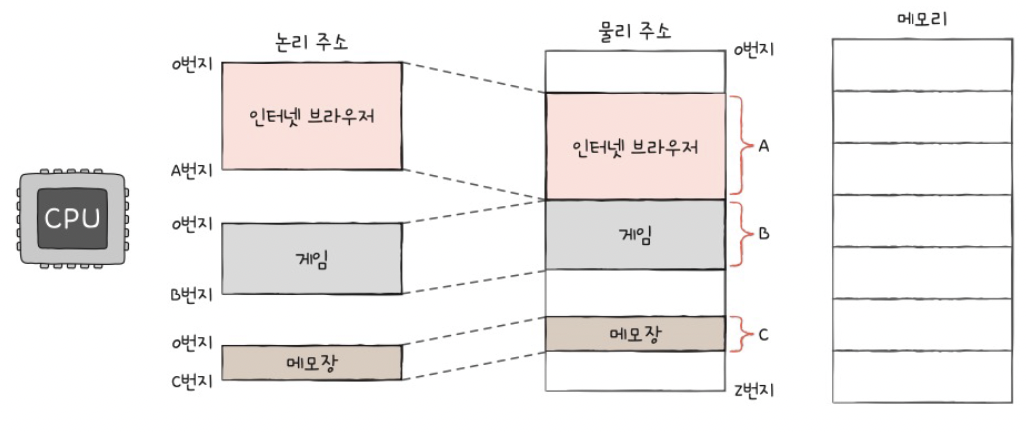
논리 주소
- 모든 프로그램은 “0번지”부터 시작하는 “각자의 논리 주소” 사용
- Q) 논리주소 & 물리주소가 다르다면, 부품 간 통신은 어떻게…?
- A) MMU (Memory Management Unit)
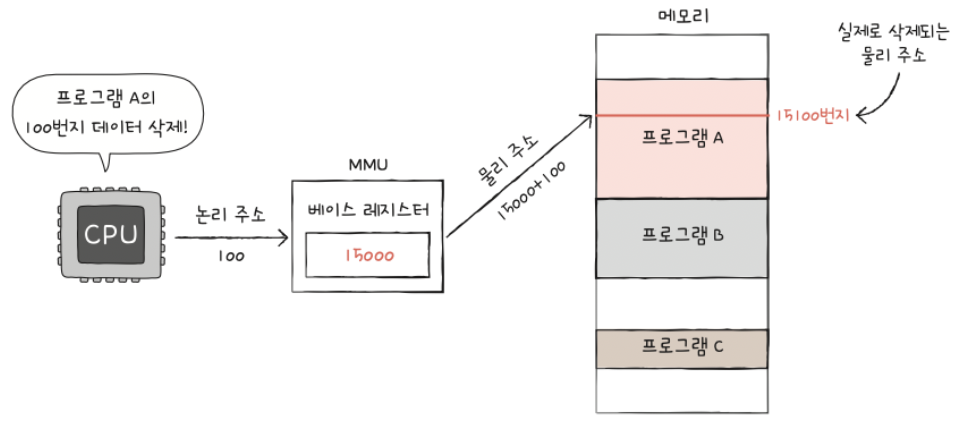
MMU (Memory Management Unit)
= 논리주소(가상주소)를 물리주소(실제 메모리 주소)로 변환하는 하드웨어 (베이스 레지스터)
- a) CPU는 프로그램을 실행할 때 논리주소를 사용함
- b) MMU는 이 논리주소를 실제 메모리 위치인 물리주소로 변환함
\(\rightarrow\) 이 변환 과정을 통해 각 프로세스는 독립된 메모리 공간을 가진 것처럼 작동할 수 있음!
(4) 저장 장치 계층 구조 & 캐시 메모리
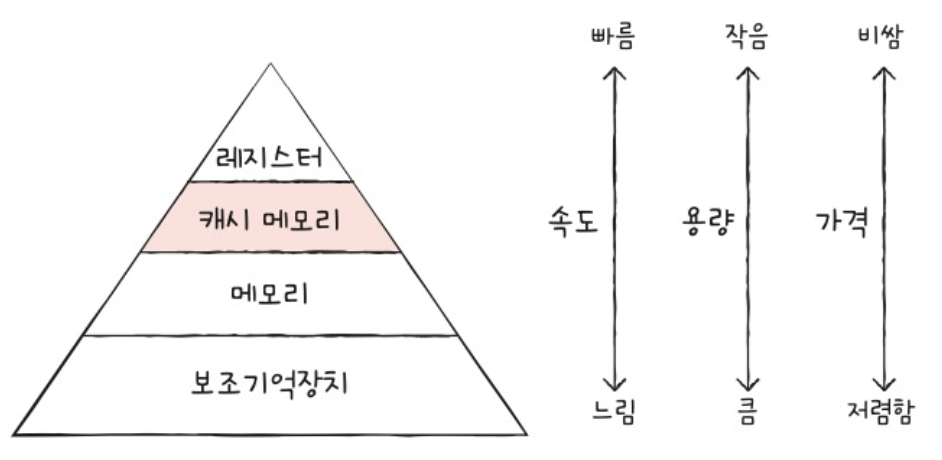
a) 저장장치의 특성
- (1) 레지스터 vs 메인 메모리
- (2) 메인 메모리 vs 보조 기억장치
- (3) 보조 기억장치 vs 클라우드 저장 장치
b) 양립 불가능성
- CPU와
- “가까울수록” 빠르고
- “멀리있을수록” 느리다
- 저장장치의 속도가
- “빠를수록” 용량이 작고 비싸고
- “느릴수록” 용량이 크고 싸다
c) 캐시 메모리
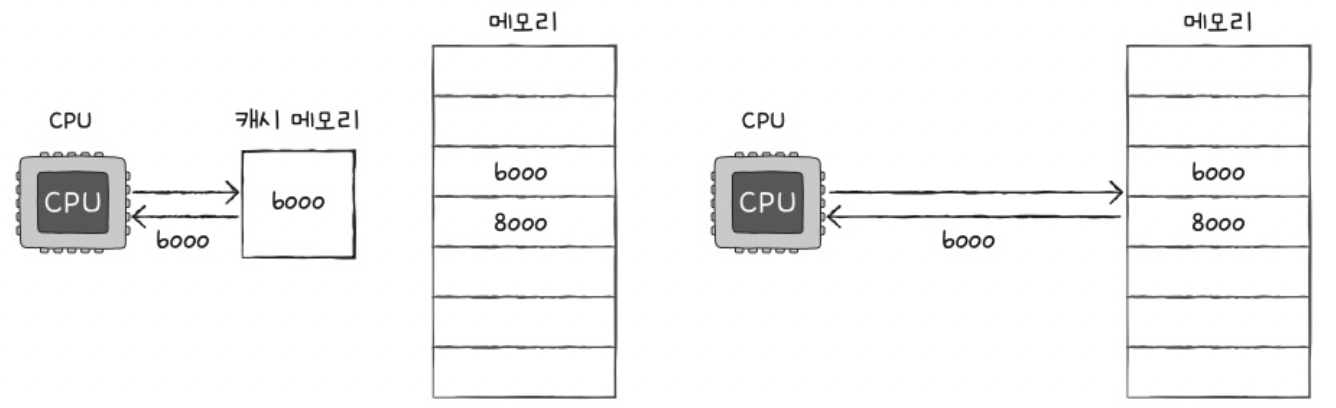
Motivation: CPU가 아무리 빨리 정보를 처리해도 … 메모리가 발맞춰주지 않으면 말짱 헛수고!
\(\rightarrow\) CPU & 메모리 간의 속도 차이를 극복하기 위해, “캐시 메모리” 탄생
- CPU & 메모리 사이에 위치
- 레지스터보다 용량이 큼& 메모리보다 빠름 (SRAM 기반)
- 취지: CPU에서 “사용할 법한” 정보를 “미리” 가져와서 저장
d) 여러 단계의 캐시 메모리
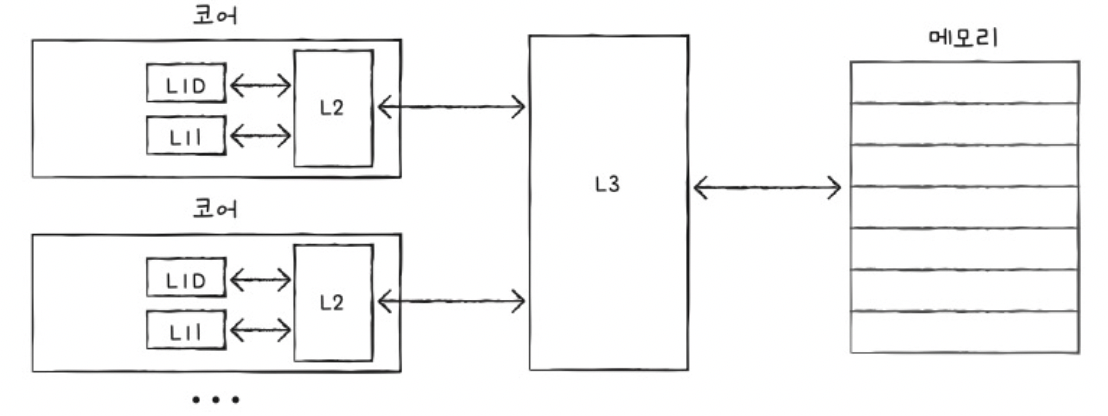
- L1 캐시 메모리: CPU와 가까움 & 용량 작음
- L2 캐시 메모리: -
- L3 캐시 메모리: CPU와 멈 & 용량 큼
- 분리형 캐시: L1D (데이터 저장) + L1I (명령어 저장)
e) 캐시 히트/미스
캐시 메모리가 CPU가 요구하는 정보를
- 저장 O고 있을 경우: “캐시 히트” (굳이 메모리 접근 X)
- 저장 X고 있을 경우: “캐시 미스” (메모리 접근 O 해야)
캐시 히트율 = 캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
f) 캐시 메모리는 어떠한 데이터를 저장?
자주 사용할 법한 내용!
\(\rightarrow\) 그걸 어떻게 알지?
\(\rightarrow\) “참조 지역성의 원리 (locality of reference)”
- (1) 시간 지역성
- CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다!
- (2) 공간 지역성
- CPU는 접근한 메모리 공간 근처를 접근하려는 경향이 있다!
g) 캐시 친화적 코드
캐시 친화적 코드
= 캐시 미스가 최소화 되는 코드
= 시간 지역성 / 공간 지역성을 준수하는 코드
h) Summary
| 속도 | 용량 | 가격 | |
|---|---|---|---|
| 레지스터 | 빠름 | 작음 | 비쌈 |
| 캐시 메모리 | - | - | - |
| 메모리 | - | - | - |
| 보조기억장치 | 느림 | 큼 | 쌈 |