
(참고: Fastcampus 강의, 강민철의 인공지능 시대 필수 컴퓨터 공학 지식)
7. GPU
Contents
- 병렬성과 동시성
- GPU (Graphic Processing Unit)
- GPU의 구조
- GPU의 세부 구조
- GPU의 실행 단위
- CUDA
(1) 병렬성과 동시성
용어/개념
-
“병렬” 실행 (“parallel” execution)
= 실제로 물리적으로 동시에 처리함
-
“동시” 실행 (concurrent execution)
= 실제로 물리적으로 동시에 처리하지 않으나, 동시에 하는 것 처럼 보일 뿐
-
(하드웨어의) “스레드”: 하나의 코어가 “동시에” 처리하는 명령어 단위


(2) GPU (Graphic Processing Unit)
a) GPU의 개요
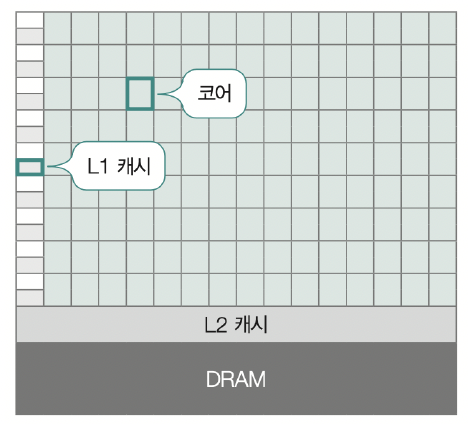
\(\rightarrow\) 매우 많은 코어를 가지고 있다.
b) GPU의 “병렬성” 예시
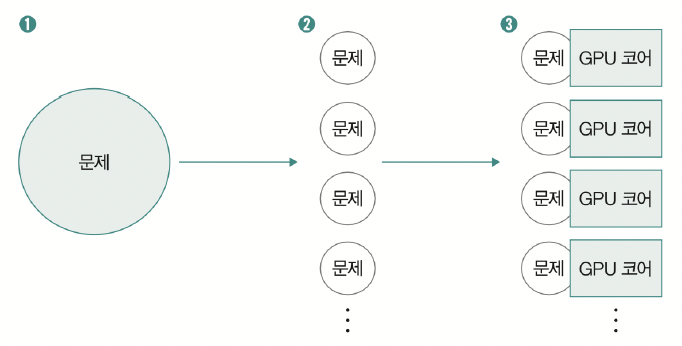
\(\rightarrow\) 큰 문제를 여러 문제로 나눠서, 각 코어들이 나눠서 푼다.
c) GPU의 “동시성” 예시
“굉장히 빠르게 번걸아”가면서 실행하므로, 동시에 하는 것 처럼 보임!
코어가 하나여도, 코어 하나 내에서 “멀티 스레드 프로그래밍”을 통해서!
(3) GPU의 구조
a) GPU vs. CPU
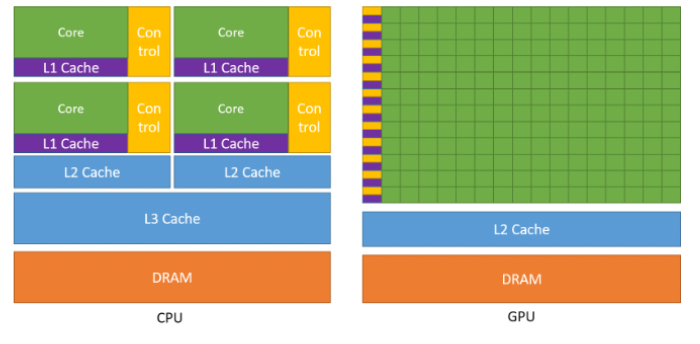
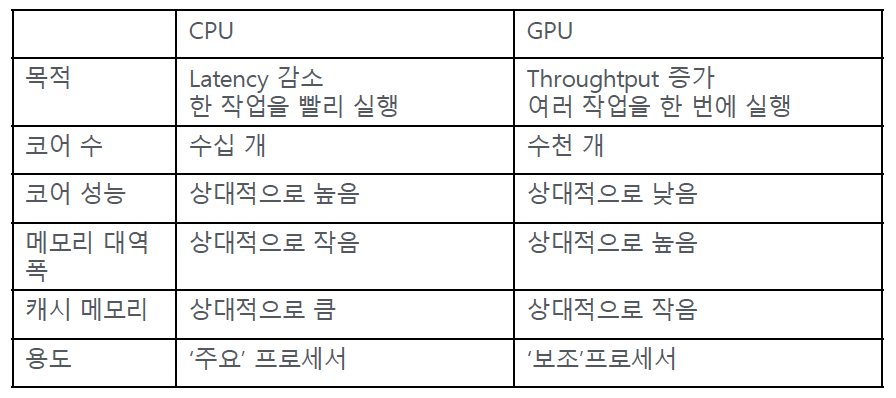
b) 딥러닝에서의 GPU
- 딥러닝 = 단순 연산의 반복 (e.g., 행렬 연산, 벡터 연산 등)
- GPU = 단순 연산에 특화!
(4) GPU의 세부 구조
GPU 구조는, 모델마다 차이가 난다!
그럼에도, 여러 모델들이 공유하는 구성에 대해서 설명!
a) PCIe & GigaThread Engine
(NVIDIA H100 GPU 모습)
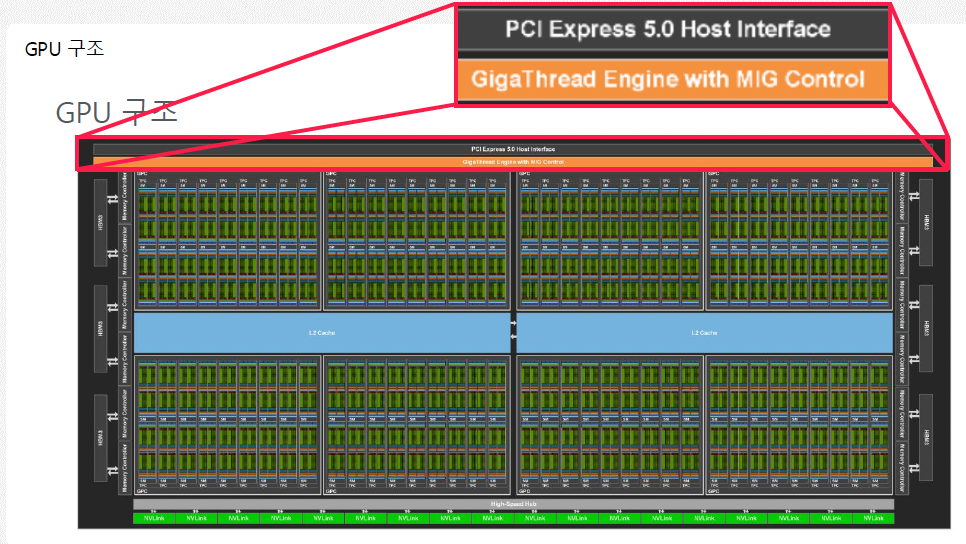
PCI Express 5.0 Host Interface
-
PCI Express (PCIe): 입출력 버스의 일종
-
GPU와 CPU(메인 보드) 간의 데이터 전송 통로
\(\rightarrow\) 이를 통해 GPU가 메모리나 CPU와 더 빠르게 통신할 수 있음
GigaThread Engine with MIG Control
-
NVIDIA GPU 내에서 수천 개의 스레드를 효율적으로 스케줄링하고 분배하는 하드웨어
(즉, “어떤 스레드”를 “어떤 코어”가 수행할지!)
-
여기에 MIG (Multi-Instance GPU) 기능이 결합되면, 하나의 GPU를 최대 7개의 독립적인 인스턴스로 나눌 수 있음
- MIG Control 기능이 포함된 GigaThread Engine은 각 인스턴스의 스레드를 격리하면서도 효율적으로 처리
-
ex) 여러 사용자가 동시에 하나의 GPU를 사용하는 클라우드 환경에서 유용함.
b) NVLink
(Multi-GPU 환경에서) GPU간 PCIe 통신 병목 발생 가능성 ↑
- (1) NVLInk: 고성능 GPU 통신 NVIDIA 인터커넥트 기술
- PCIe (수십 GB/s) 대비 높은 대역폭 (수백 GB/s)
- (2) NVLink Bridge: NVLink를 구현하는 하드웨어

c) HBM & Memory Controller & L2 Cache
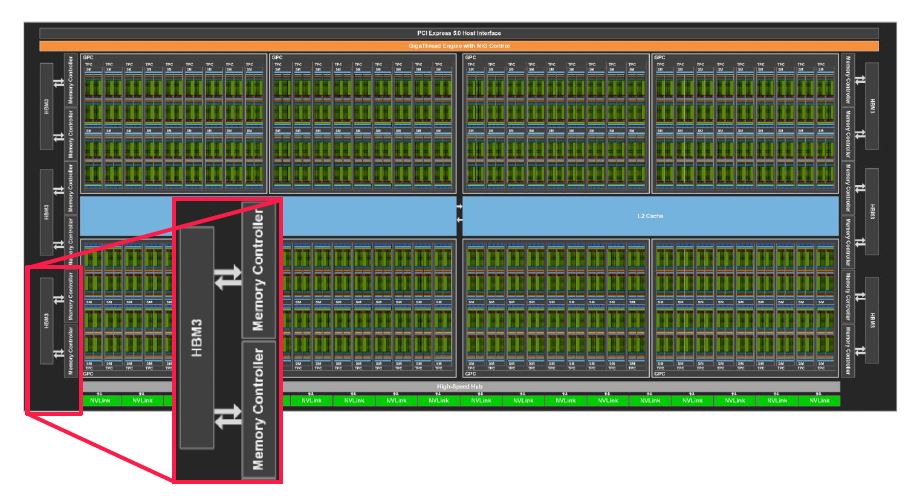
- (1) HBM (High Bandwith Memory)
- 고대역폭 메모리
- 여러 DRAM 칩을 수직으로 쌓아올려 대역폭을 높임
- 오늘날 GPU에 대부분 장착
- (2) Memory Controller
- HBM의 장치 컨트롤러
- (3) L2 Cache
- GPU 내부 “코어 간” 공유되는 L2 Cache
d) HBM vs. Memory Controller vs. L2 Cache (feat. ChatGPT)
(공통) 모두 GPU에서 데이터를 저장하고 주고받는 역할
(차이) 위치와 속도, 목적이 다름
HBM (High Bandwidth Memory)
- 📍 GPU 외부에 위치 (GPU 칩 옆에 붙어 있음)
- 💾 많은 데이터를 저장 (수~수십 GB)
- 🐢 상대적으로 느리지만 용량이 큼
- 📦 데이터를 대량으로 GPU로 보내주는 역할
- 🔗 예: 모델 파라미터, 이미지, 벡터 등 큰 데이터
Memory Controller
- 🔁 HBM과 GPU 내부 사이를 연결해주는 다리
- 🧠 데이터가 오고 갈 때, 어떤 데이터를 언제 가져올지 스케줄링하고 조율함
- 📏 HBM을 어떻게 접근할지 제어하는 중간 관리자 역할
- 예: 필요한 데이터만 HBM에서 가져오게 함
L2 Cache
- 📍 GPU 내부에 위치 (HBM보다 가까움)
- ⚡ HBM보다 훨씬 빠름
- 🧠 자주 사용하는 데이터나 연산 결과를 임시로 저장
- 📉 HBM 접근을 줄여 속도 향상과 전력 절감에 도움
비교 요약
- HBM: 도서관 (큰 창고, 책이 많고 큼직함, 접근은 느림)
- Memory Controller: 사서 (어떤 책을 꺼낼지 결정하고 전달)
- L2 Cache: 책상 위 메모지 (자주 쓰는 정보만 빠르게 볼 수 있음)
e) SM (Streaming Multiprocessor) unit
-
GPU 코어의 핵심 unit
( = 실제 연산을 수행하는 작업 단위 )
-
1개의 GPU = 여러 개의 반복적인 SM
( GPU 전체가 공장이라면, SM은 생산 라인 하나 )
-
SM core도 내부적으로 여러가지 구성 요소로 이뤄짐
- CUDA Cores: 덧셈, 곱셈 같은 일반 연산 처리
- Tensor Cores: 행렬 연산 가속 (딥러닝에 중요)
- Warp Scheduler: 병렬 스레드 실행 제어
- Register File & Shared Memory: 각 스레드/블록의 데이터 저장
f) SM의 구성 요소 (상세)
1. CUDA Cores
- 기본 정수 및 부동소수점 연산 처리
- CPU의 ALU에 해당함
- 하나의 warp(32 threads)가 이 코어들에서 동시 실행됨
2. Tensor Cores
- 행렬 곱 연산(MATMUL)을 빠르게 처리
- 딥러닝 모델 학습 및 추론에 특화됨
- FP16, BF16, TF32, INT8 등 다양한 정밀도 지원
3. Warp Scheduler
- warp(= 32개의 스레드 묶음)의 실행을 관리
- SM 하나당 여러 개의 스케줄러가 있음 (보통 2개 또는 4개)
- 동시에 여러 warp를 실행하도록 명령어 발행
4. Register File
- 각 스레드가 사용하는 로컬 변수 저장 공간
- 매우 빠른 접근 속도를 가짐
- 용량은 고정되어 있어서 register pressure가 생기면 occupancy 감소
5. Shared Memory
- 같은 thread block 내의 스레드들이 공유하는 메모리
- L1 캐시처럼 작동 가능 (configurable)
- bank conflict 없이 쓰면 빠르게 연산 가능
6. Instruction Cache (I-Cache)
- 스레드에서 실행할 명령어들을 캐싱
- warp 단위로 명령어를 fetch하기 때문에 중요한 구성 요소
참고로 SM의 개수는 GPU의 병렬 처리 능력에 직결되며,
SM 안의 구성 요소 수(예: CUDA core 개수, Tensor core 개수 등)는 GPU 아키텍처에 따라 다르다!
g) A100 vs. V100 vs. H100
| 구성 요소 | V100 (Volta) | A100 (Ampere) | H100 (Hopper) |
|---|---|---|---|
| 아키텍처 | Volta | Ampere | Hopper |
| CUDA Cores / SM | 64 | 64 | 128 |
| Tensor Cores / SM | 8 (1세대, FP16) | 4 (2세대, FP16, TF32) | 4 (4세대, FP8, FP16, BF16, INT8 등 지원) |
| SM 수 | 80 | 108 | 132 |
| 특이점 | Volta: Tensor Core 최초 도입 | Ampere: TF32 도입, 구조적 희소성 지원 | Hopper: FP8 도입, 새로운 SM 파이프라인 구조 |
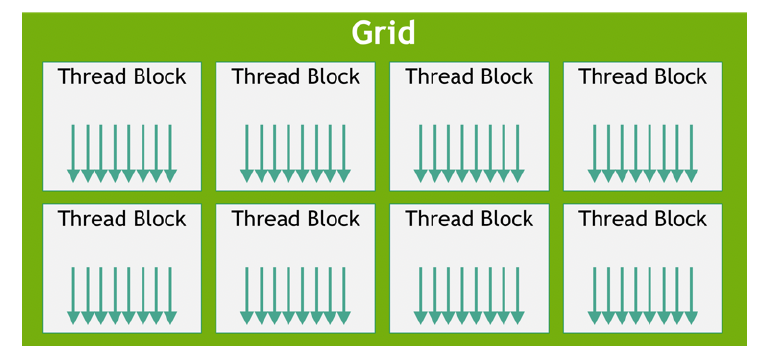
(5) GPU의 실행 단위
계층적으로 구분!
| 계층 | 용어 | 설명 | 실행 측면에서의 역할 |
|---|---|---|---|
| 1️⃣ | 커널 (Kernel) | GPU에서 실행되는 하나의 함수 | 호스트(CPU)가 GPU에 명령을 내릴 때 사용하는 단위 |
| 2️⃣ | 그리드 (Grid) | 여러 개의 블록으로 구성된 전체 실행 구조 | GPU 전체의 병렬 작업 단위 |
| 3️⃣ | 블록 (Block) | 여러 개의 스레드로 구성 | 보통 하나의 SM에서 처리되는 단위 |
| 4️⃣ | 워프 (Warp) | 보통 32개 스레드로 구성된 묶음 | 실행 유닛(SIMD)가 실제로 명령어를 실행하는 단위 |
| 5️⃣ | 스레드 (Thread) | 가장 작은 실행 단위 | 실제로 데이터를 처리하는 기본 단위 |
- 개발자가 작성한 코드 단위는 → 커널
- 논리적으로 작업을 나누는 단위는 → 스레드 / 블록 / 그리드
- GPU 하드웨어가 실제로 명령어를 실행하는 단위는 → 워프
(6) CUDA (Compute Unified Device Architecture)
기본 특징
- NVIDIA GPU에서 “병렬 프로그래밍”을 수행하기 위해 만든 프로그래밍 인터페이스
- C++ 확장을 통해 GPU 병렬코드 쉽게 작성 가능
- 커널 정의 & 메모리 및 실행 단위 관리