All about “SAM”
(Reference: https://www.youtube.com/watch?v=eYhvJR4zFUM)
Contents
- Image Segmentation
- Introduction to Segment Anything (SAM)
- Promptable Segmentation Task
- Segment Anything Model
- Segment Anything Dataset
- [A] Promptable Segmentation Task
- [B] Segment Anything Model
- Image Encoder
- Prompt Encoder
- Mask Decoder
1. Image Segmentation
Definition
Process of partitioning a digital image into multiple regions (or segments)
- Pixels belonging to the same region share some (semantic) characteristics
Challenges
- Difficult & Expensive to label
- Models are usually application-specific
- e.g., Medical \(\rightarrow\) Pedistrian detection (?)
- Previous models are usually not promptable
- e.g., can’t tell the model to only segment “people”
2. Introduction to Segment Anything (SAM)
Three innovations
-
Promptable Segmentation Task
- Segment Anything Model
- Segment Anything Dataset (and its Segment Anything Engine)
(1) Promptable Segmentation Task
Allows to find masks given a prompt of …
- (1) Points (e.g., mouse click)
- (2) Boxes (e.g., rectangle defined by user)
- (3) Text prompts (e.g., “find all dogs”)
(2) Segment Anything Model
- (1) Fast encoder-decoder model
- (2) Ambiguity-aware
- e.g., Given a point … it may correspond to (a) or (b) or (c)
- (a) Part
- (b) Subpart
- (c) Whole
- e.g., Given a point … it may correspond to (a) or (b) or (c)
(3) Segment Anything Dataset
- (1) 1.1 billion segmentation masks
- Collected with the Segment Anything Engine
- (2) No human supervision
- All the masks have been generated automatically!
3. [A] Promptable Segmentation Task
Pretraining task: Foundation model …
- for NLP: Next token prediction
- for CV: Promptable Segmentation Task
Goal: Return a “valid” segmentation mask given any prompt
What is “valid” mask?
\(\rightarrow\) Even when prompt is ambiguous, the output should be a reasonable mask!

4. [B] Segment Anything Model
(1) Image Encocer
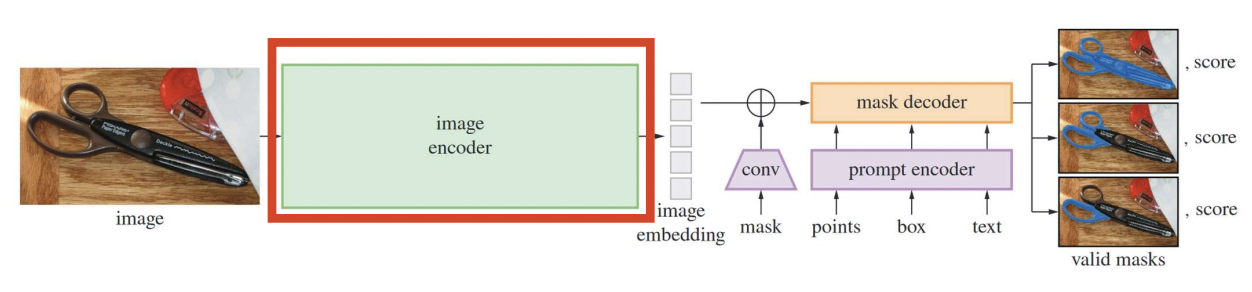
- MAE pretrained ViT
- Applied prior to prompting the model!
(2) Prompt Encoder
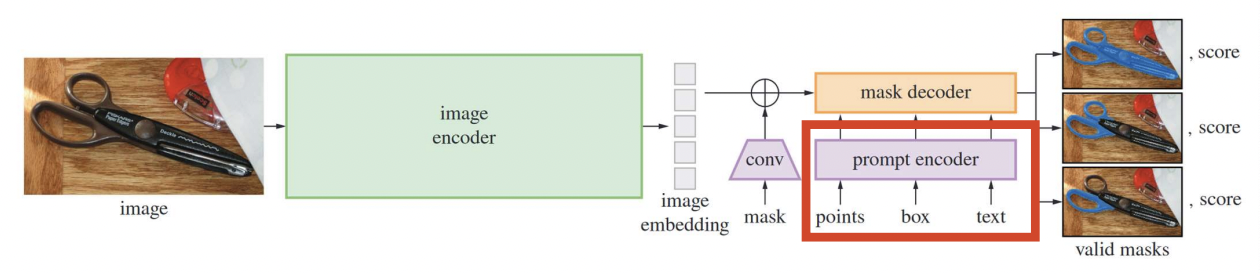
a) Two sets of prompts
(1) Sparse (points, boxes, text)
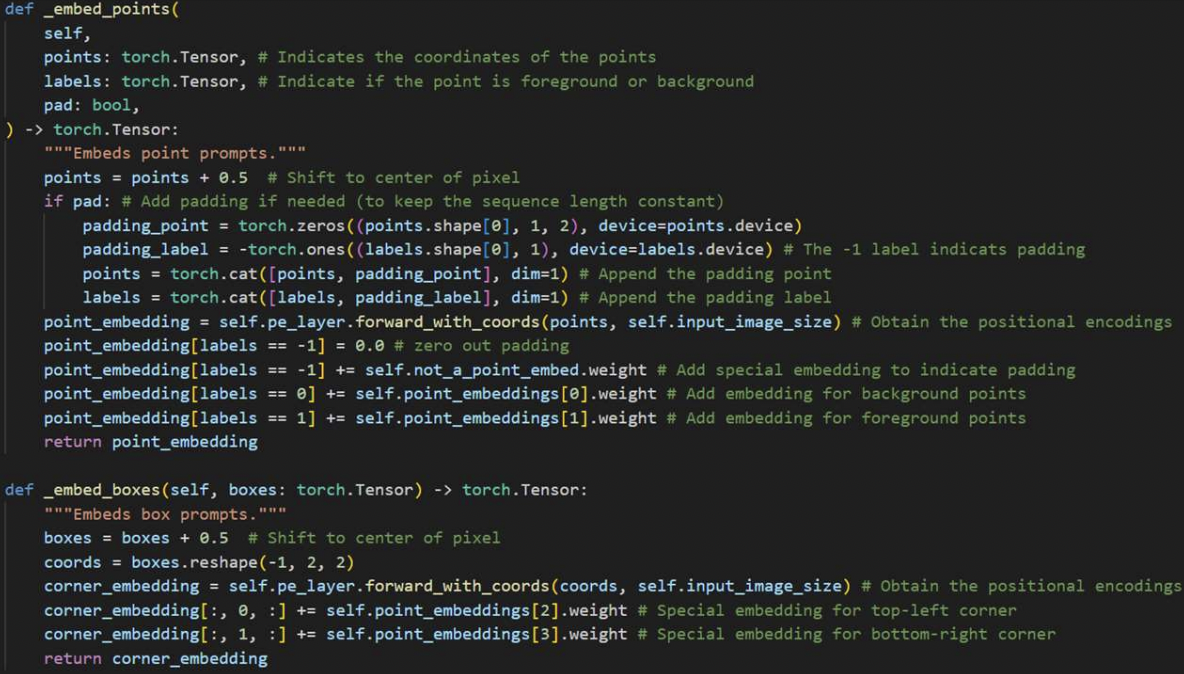
- 1-a) Points & Boxes: Represent by (1) + (2)
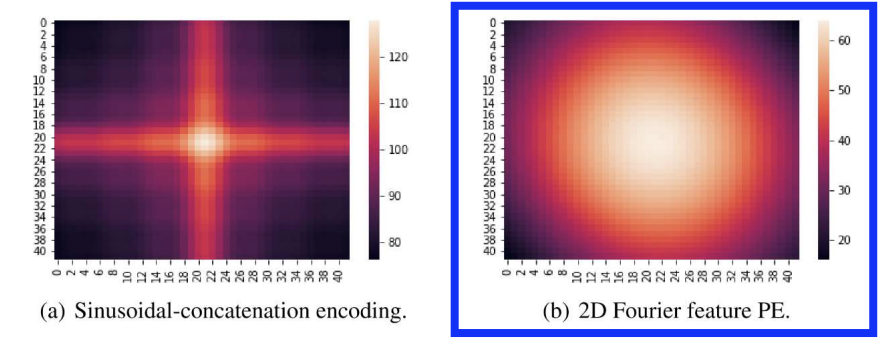
- (1) Positional encodings (PE)
- (2) Learned embeddings for each prompt type
- 1-b) Text: Represent with text encoder from CLIP
(2) Dense (masks)
- Embedded using convolutions
- Summed element-wise with image embedding
b) Details of Sparse prompts
Mapped to 256-dim
- Point: (1) + (2)
- (1) PE of the point’s location
- (2) One of two learned embeddings
- indicate either in the foreground or background
- Box: Embedding pair ((1),(2))
- (1) PE of “top-left corner” + Learned embedding of “top-left corner”
- (2) PE of “bottom-right corner” + Learned embedding of “bottom-lright ft corner”
- Text: embedding vector from text encoder of CLIP
c) Details of Dense prompts
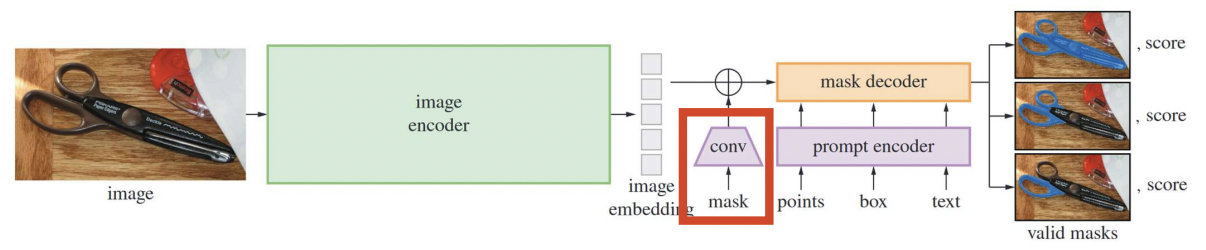
Dense prompts
- Have a spatial correspondence with the image
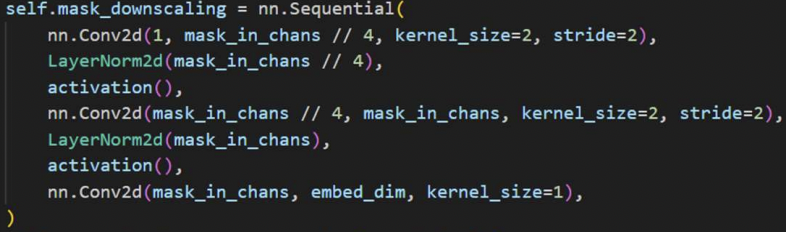
Downscale the input masks
-
Step 1) Downscale 1: “4x lower resolution” than input image
\(\rightarrow\) Output channels of 16
-
Step 2) Downscale 2: Additional “4x lower resolution”
\(\rightarrow\) Output channels of 4
-
Step 3) Into 256 channels (with 1x1 convolution)
d) Positional Encodings
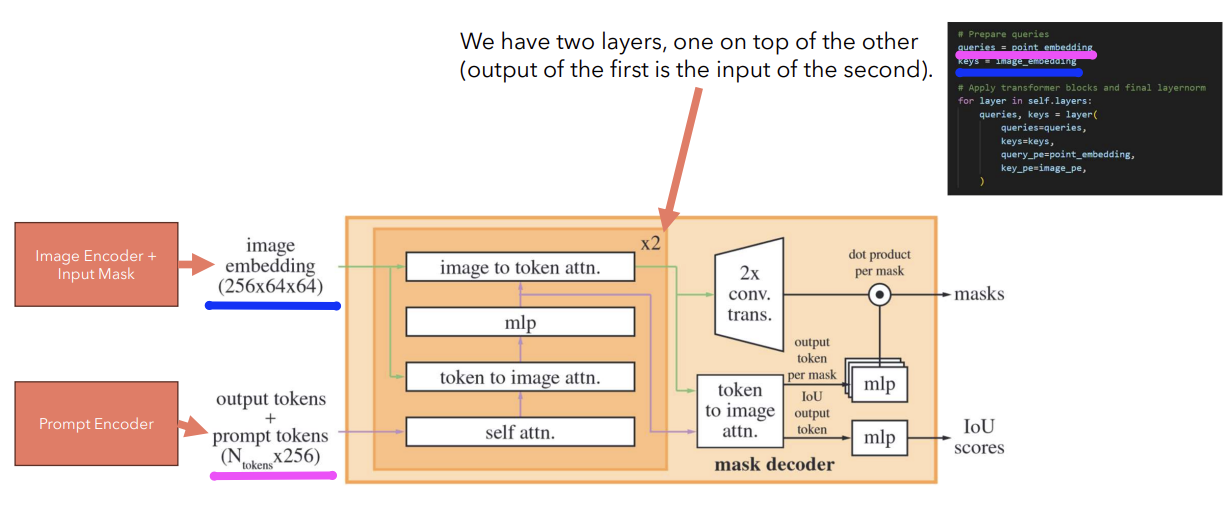
(3) Mask Decoder
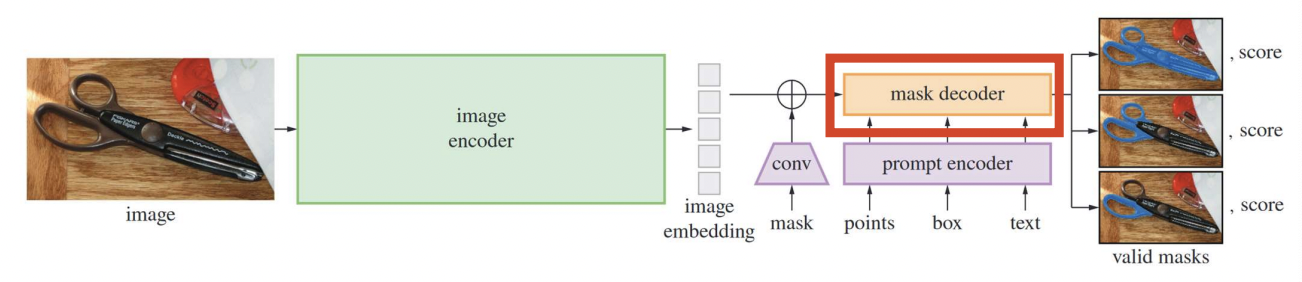
Lightweight mask decoder
- [Input] Image embedding & Prompt Embeddings
- Image embedding: 256x64x64
- Prompt Embeddings ( with Output tokens): \(N_{\text{tokens}}\) x 256
- Output tokens = [CLS] token
- [Output] Output mask & IoU scores
Output tokens: two types of tokens
- (1) For IoU
- (2) For Mask