
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
Dai, Xiaoliang, et al. "Emu: Enhancing image generation models using photogenic needles in a haystack." arXiv preprint arXiv:2309.15807 (2023).
참고:
- https://aipapersacademy.com/emu/
- https://arxiv.org/pdf/2309.15807
Contents
- Introduction
- Examples
- Statistics
1. Introduction
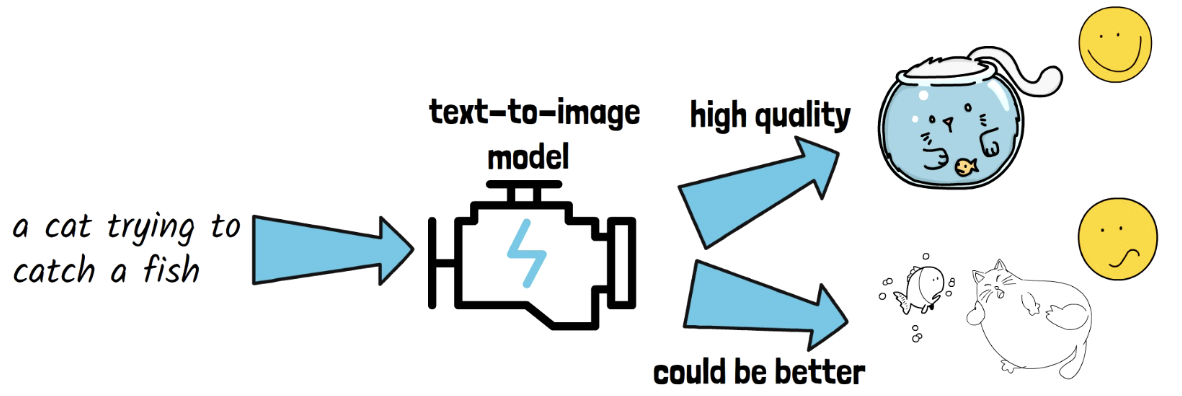
Motivation: It is not always easy to generate highly aesthetic images consistently with text-to-image models
Emu (by Meta AI)
(Enhancing Image Generation Models Using Photogenic Needles in a Haystack)
- Text-to-image generation model
- [Input] text prompt
- [Output] High-quality image
- Previous works: Not always easy to get high-quality results
- Emu: Quality-tuned to yield high quality results consistently
Examples


2. How Emu Was Created
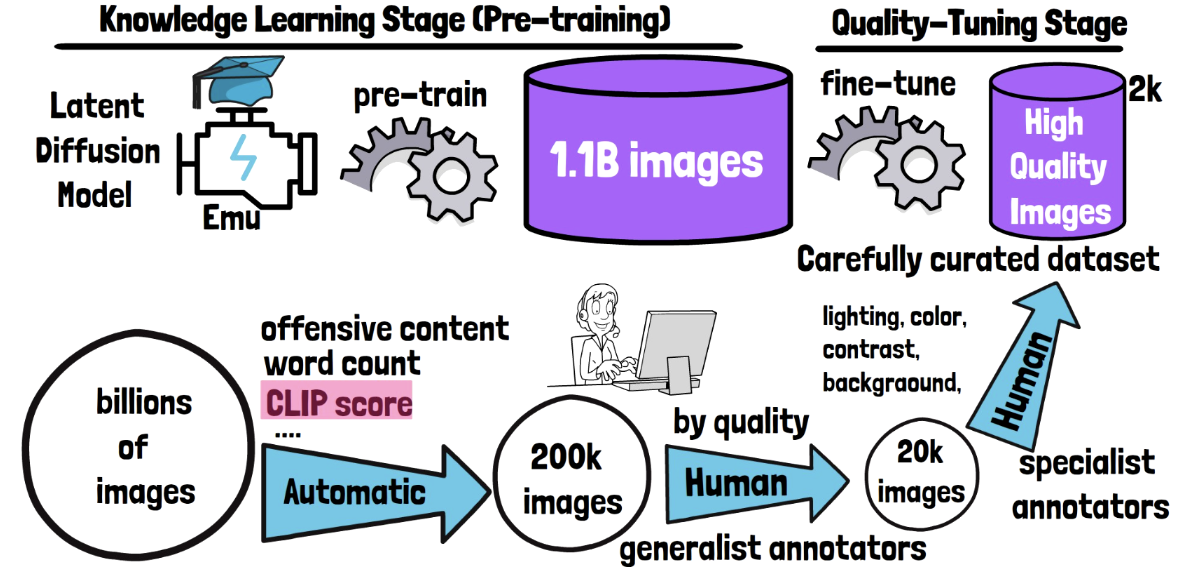
Two stages
- Stage 1) Knowledge learning stage (= Pre-training stage )
- Stage 2) Quality-tuning (= Fine-tuning stage)
Stage 1) Knowledge learning stage (= Pre-training stage)
- (1) Model: Latent diffusion model
- (2) Dataset: Large Meta internal dataset of 1.1 B images
- (3) Results: Capable of generating images for diverse domains and styles
- (4) Limitation: Not properly guided to always generate highly aesthetic images
Stage 2) Quality-tuning (= Fine-tuning stage)
- (1) Model: Pre-trained latent diffusion model
- (2) Dataset: Another dataset of high-quality images
- (3) Results: Strong in generating highly aesthetic images consistently
3. Curating High Quality Images for Quality-Tuning
4. Diffusion Model Architecture Change
Slightly different latent diffusion model!
-
(Previous) Latent diffusion models = U-Net
-
Learns to predict the noise in an image
-
Works in the latent space
( \(\therefore\) Before passing the input via the U-Net, it is being encoded by an autoencoder )
\(\rightarrow\) Commonly used autoencoder = 4 output latent channels
-
-
(Emu) 4 channels \(\rightarrow\) 16 channels
- Results: Improves reconstruction quality