
Vision Transformers Need Registers – Fixing a Bug in DINOv2?
Darcet, Timothée, et al. "Vision transformers need registers." ICLR 2024
참고:
- https://aipapersacademy.com/vision-transformers-need-registers/
- https://arxiv.org/pdf/2309.16588
Contents
- Background: Visual Features
- The Problem: Attention Map Artifacts
- The Fix: Registers
- Results
- Conclusion
Abstract
Proposal: Vision Transformers (ViTs) registers
- Share authors with DINOv2 paper
1. Background: Visual Features
-
Models from scratch (X)
-
Pre-trained large computer vision model (O)
-
e.g., DINOv2 ( a large Vision Transformer (ViT) model )
-
Output = visual features or embeddings
\(\rightarrow\) Capture the semantic of the input image
-
2. The Problem: Attention Map Artifacts
(1) Attention Map
ViT = Attention mechanism
-
Attention map = Visualization of the attention values
\(\rightarrow\) Which parts of the image are important!
(2) Object Discovery
Object Discovery: One usage for attention maps
- Object detection = Locates only known labeled object
- Object discovery = Also locates unknown not-labeled object
- e.g.,) Object discovery using attention maps method = LOST (using DINOv1)

(3) Artifacts
LOST method
\(\rightarrow\) Found that the attention map in DINOv2 is not as semantically clear as in DINOv1 !!
- Ex) Outlier peaks in DINOv2 attention map = artifacts

Not only DINOv2, but other large visual transformer models!
(e.g., OpenCLIP, DeIT)
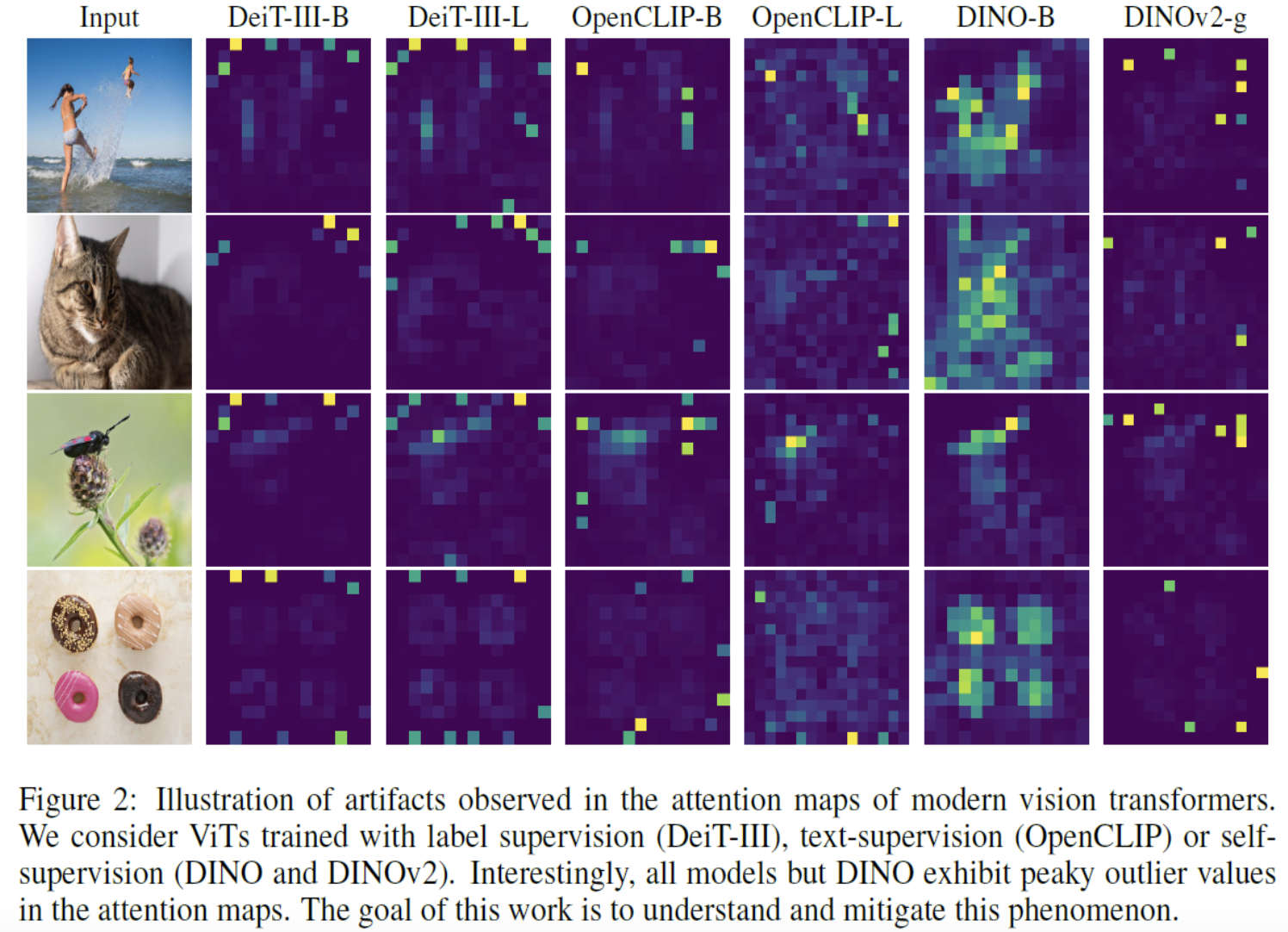
(4) Analyzing the Artifacts
L2 norm values of the features extracted for image patches
- DINOv1: OK
- DINOv2:
- Majority of features are of low value
- But a small proportion of patches have high norm!

(5) What Data Do The Artifacts Capture?
Conclusion
- Artifacts lack spatial information
- Artifacts hold global information
a) Artifacts lack spatial information
High-norm features
-
Contain less information about their position in the original image
-
(Left chart) Orange line
-
Artifacts are located in patches that are very similar to their surrounding patches
( = Confirms that the artifacts appear in background )
-
-
(Right chart) Trained models to ..
-
Task 1) predict the original position of a token
-
Task 2) reconstruct the original pixels
\(\rightarrow\) In both tasks, performs worse for the high-norm tokens!
-

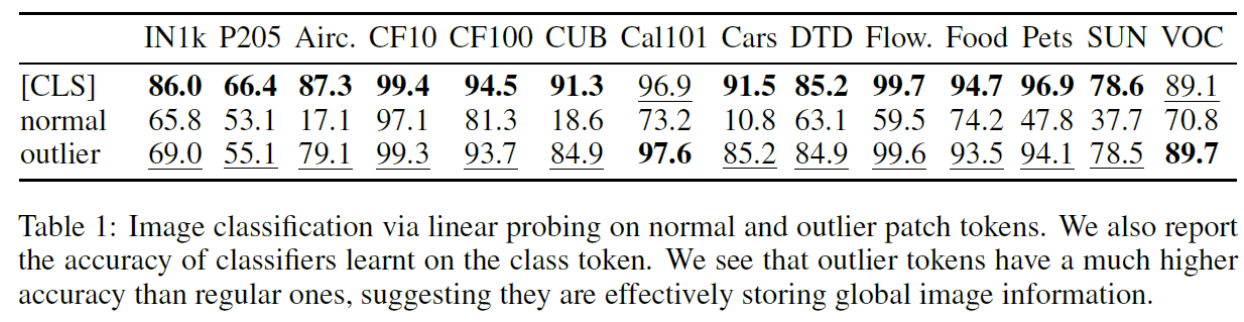
b) Artifacts hold global information
Classification results when using embeddings from DINOv2 as inputs
- (Row 1) class token
- (Row 3) > (Row 2)
(6) When do the High-Norm Tokens Appear?
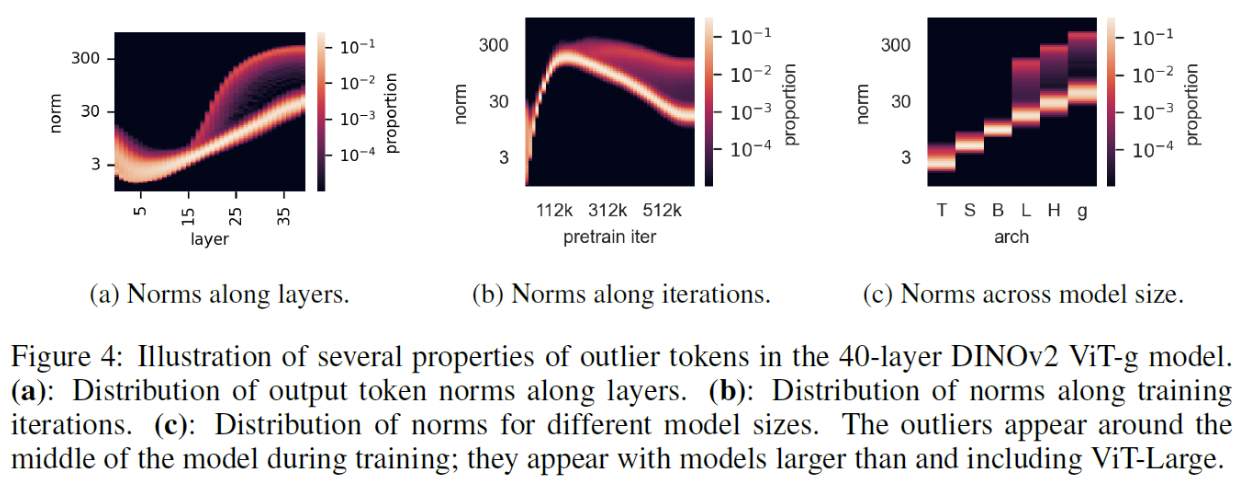
Figure 4(a)
- More common from the middle to the last layers
Figure 4(b)
-
Start to appear after training the model for a while
( Not at the beginning of the training process )
Figure 4(c)
- Only appear on larger models
Conclusion: large and sufficiently trained models learn to recognize redundant tokens, and use them to store global information.
3. The Fix: Registers
(1) Key Idea
Key idea) If the model learns to use tokens that are less important in order to store global information…
\(\rightarrow\) We can add more tokens that the model will use to store that information
( instead of the tokens from the original image )
(2) Registers
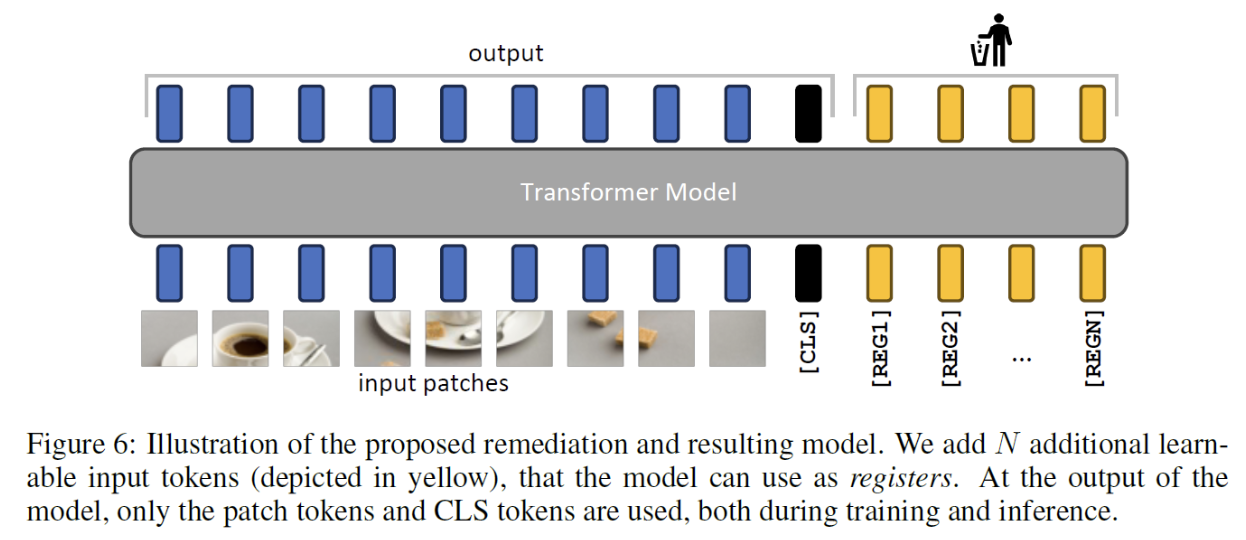
Solution: Registers (= The added tokens)
- (1) Added to the input
- (2) Discarded from the output
- Assumption: The model will use them instead of the image patch tokens to store the global information
(3) Do Registers Prevent Artifacts?
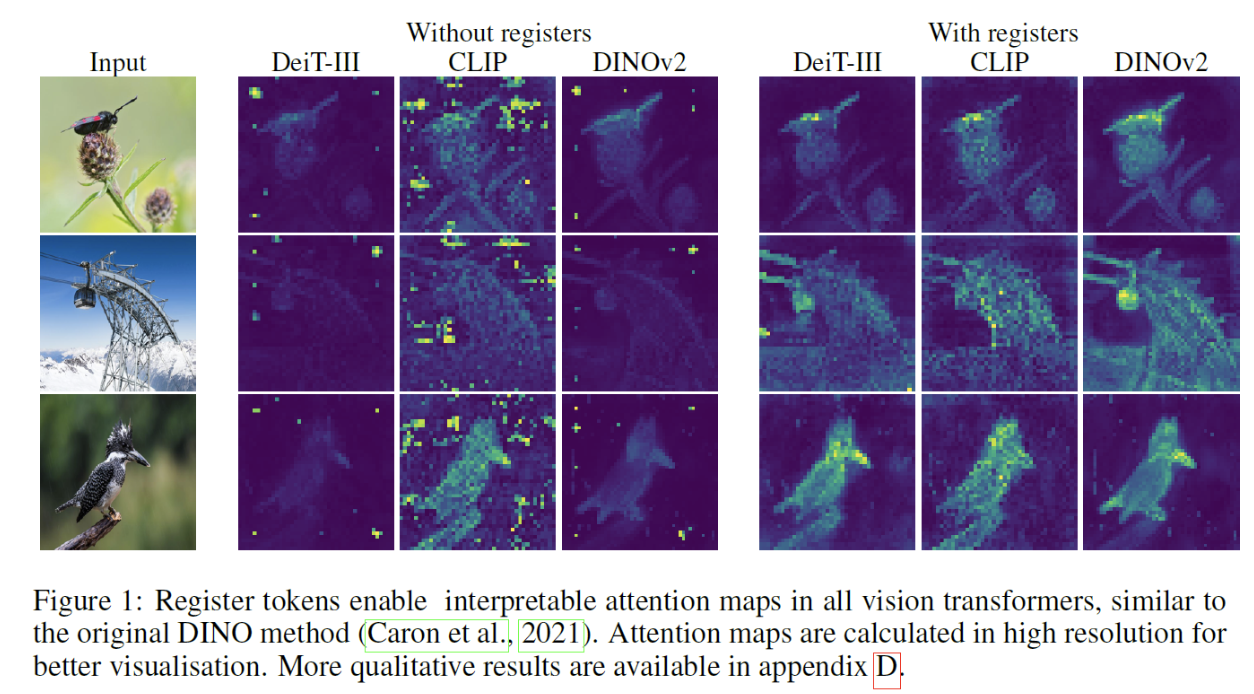
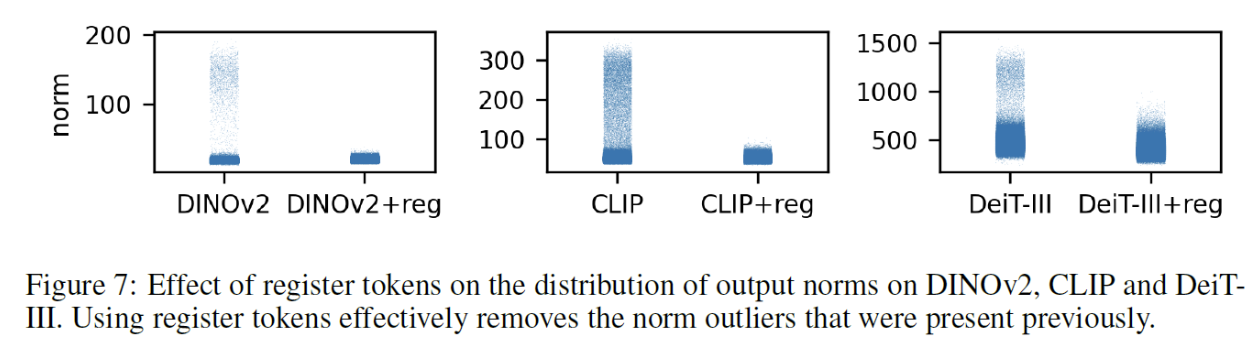
4. Results
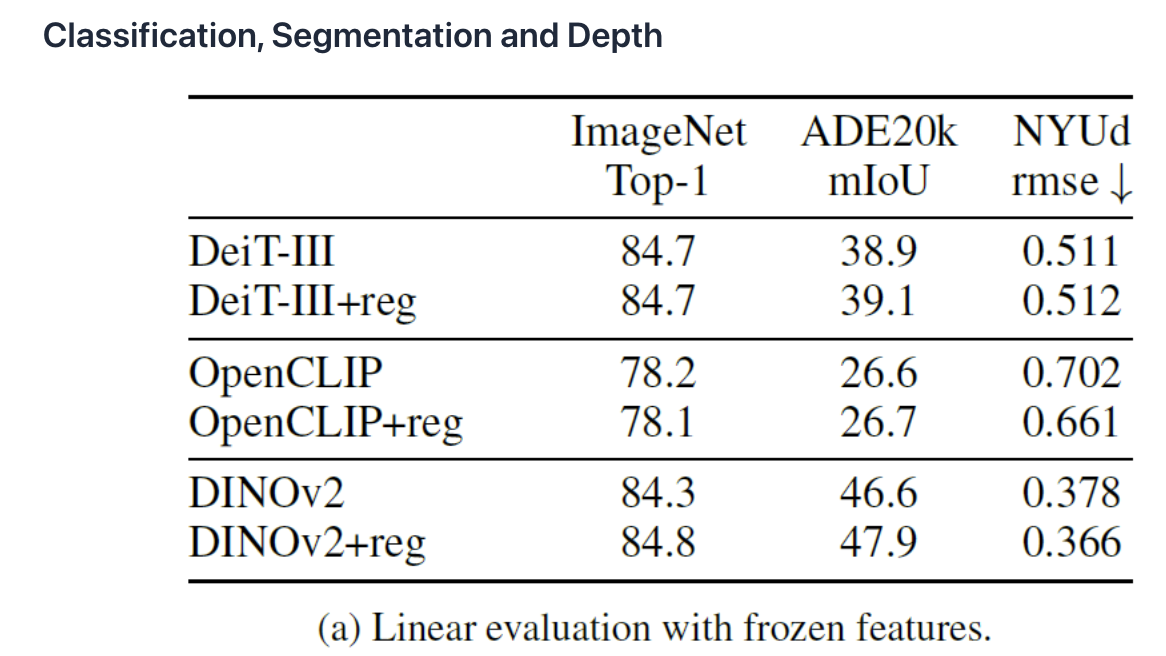
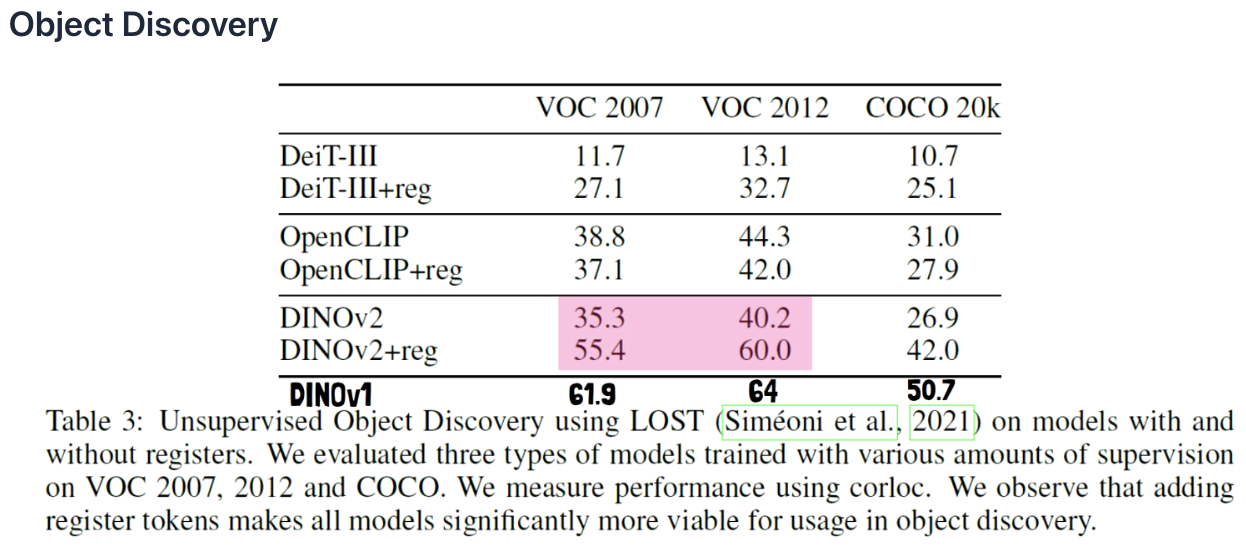
5. Conclusion
- Highlights how unimportant tokens store useful information.
- Registers nearly eliminate these artifacts.
- (Experiment 1) Classification, segmentation, and depth
- Registers yield minor gains but increase memory and latency, making their use case-dependent.
- (Experiment 2) Object discovery
- Improves significantly with DINOv2 but remains inferior to DINOv1.