
ImageBind: One Embedding Space To Bind Them All
Girdhar, Rohit, et al. "Imagebind: One embedding space to bind them all." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
참고:
- https://aipapersacademy.com/imagebind/
- https://arxiv.org/abs/2305.05665
Contents
- Introduction
- Cross-Modal Retrieval
- Embedding Space Arithmetic
- Audio to Image Generation
- Building ImageBind Model
1. Introduction
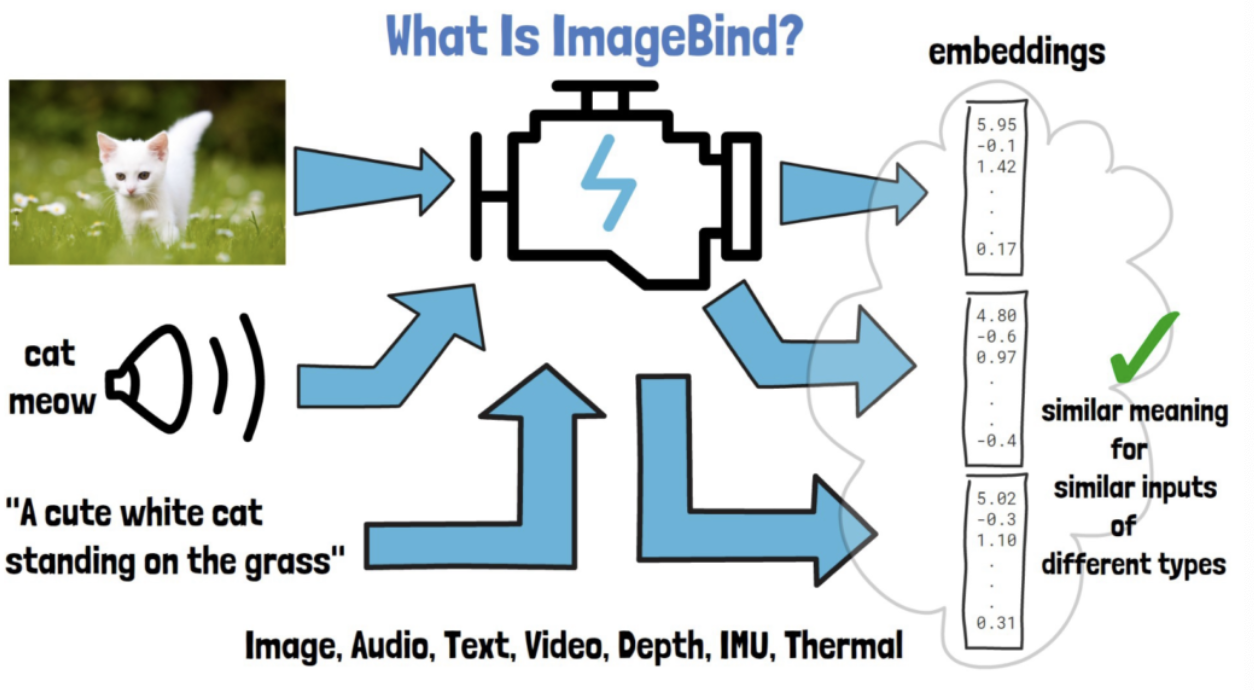
ImageBind (by Meta AI)
- Handles six different types of data
- Image, audio, text, video, depth sensor data, IMU (sensors that detect phone tilts and shakes), thermal data
- Embeddings of various modalities
- Share a common embedding space!
2. Cross-Modal Retrieval
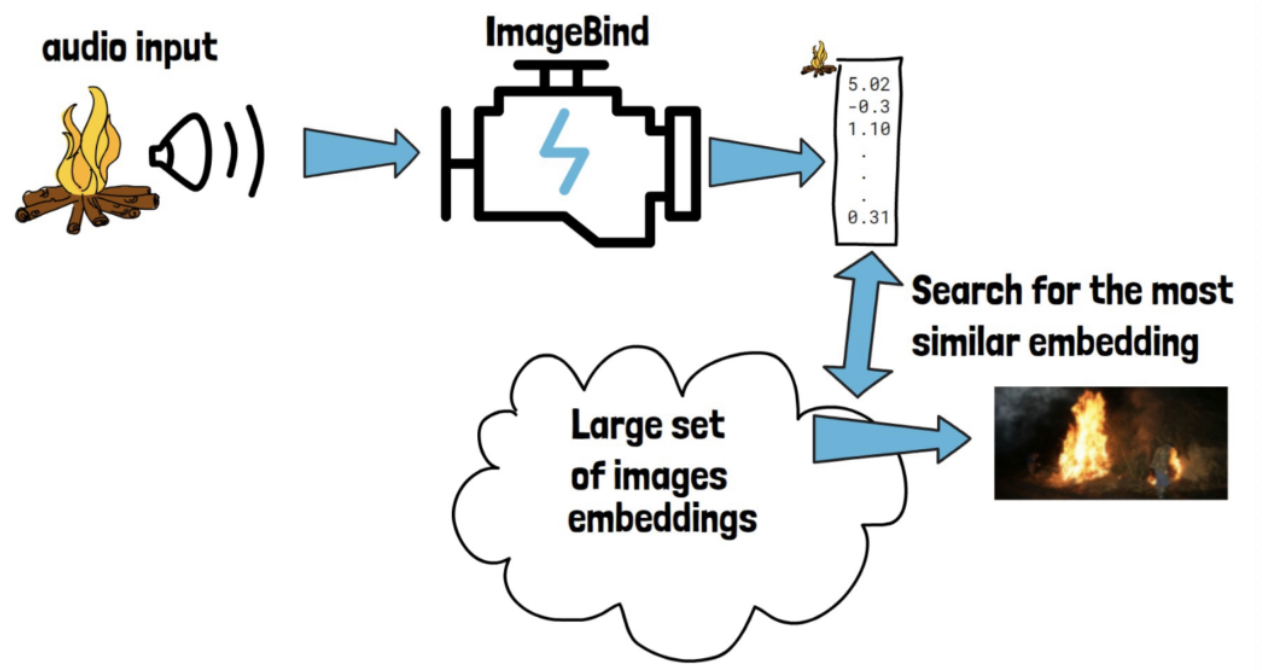
Cross-modal retrieval
- Providing a query input from “one modality”
- Retrieving a matching item from “another modality”
How?
- Step 1) Process the modality 1 (audio) to generate an embedding.
- Step 2) Search for the image (modality 2) with the most similar embedding to the (query) modality 1
3. Embedding Space Arithmetic
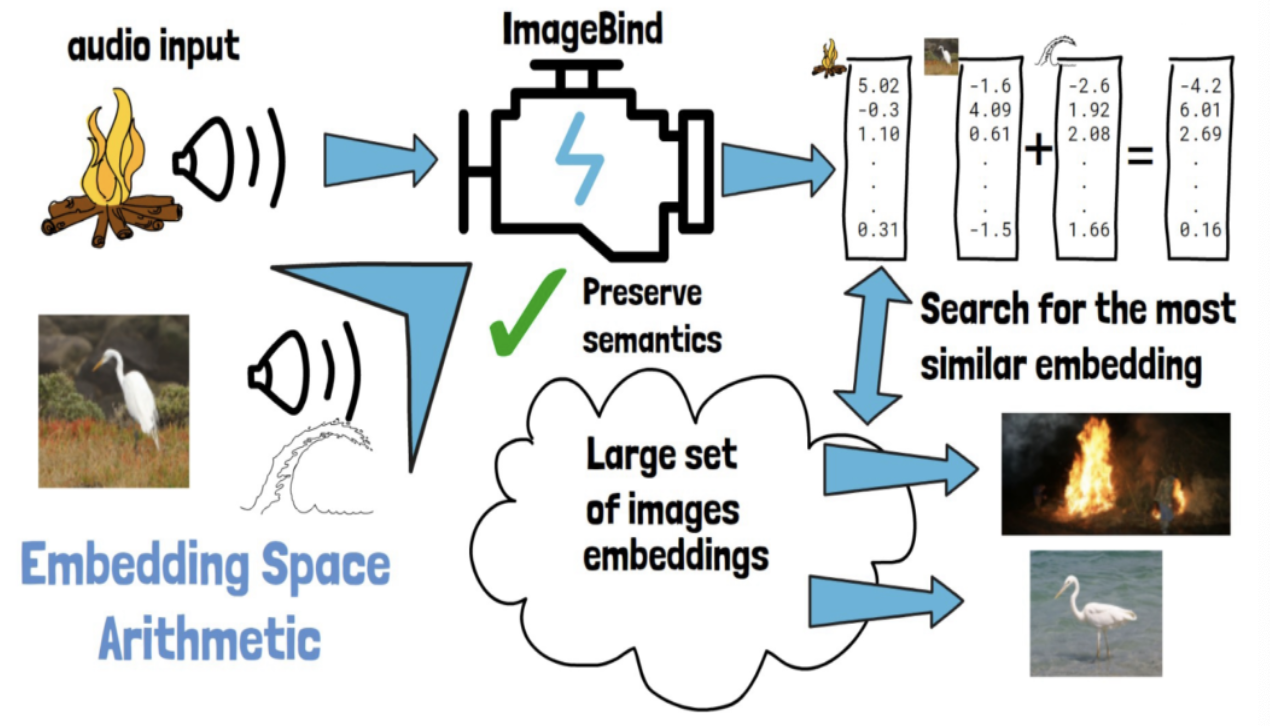
Example: Sum of embeddings
- (Image) bird + (Sound) wave = (Image) Same bird in the sea
\(\rightarrow\) Embedding space arithmetic naturally composes their semantics!
4. Audio to Image Generation
Remarkable capabilities
= Ability to generate images from audio
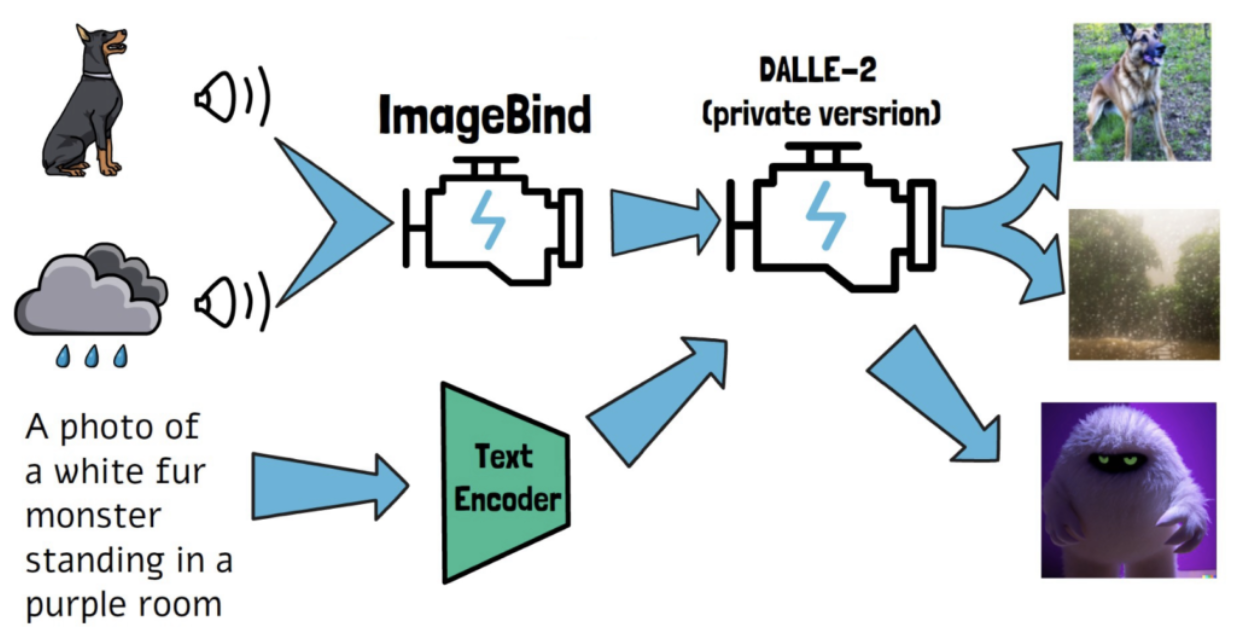
How to achieve this?
- (Pretrained) Text-to-image model = DALLE-2
- Instead of using “text” as a prompt, use “audio embedding”!
5. Building ImageBind Model
(1) 6 channels: Each channel = Each modality
(2) 5 types of encoders
-
Same encoder for images and videos
-
Distinct encoders for other modalities
(3) Model architecture
-
Image & Text encoder: from CLIP \(\rightarrow\) Freeze!
( This reliance on CLIP is likely what enabled the text encoder replacement in DALLE-2 for generating images from audio! )
-
Other 4 encoders
- Pairs of naturally matching samples
- e.g., (audio, video) from Audioset dataset ….
- Pretrain with contrastive learning (CL)
- Pairs of naturally matching samples
(Details) For CL, finding matching pairs for all different modalities is impractical!
\(\rightarrow\) Pair each modality with images (Why the model is called ImageBind)