Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, Xiaokang, et al. "Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling." arXiv preprint arXiv:2501.17811 (2025).
참고:
- https://aipapersacademy.com/janus-pro/
- https://arxiv.org/pdf/2411.07975
- https://arxiv.org/pdf/2501.17811
- https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf
Contents
- Introduction
- UNIFIED multimodal understanding & generation
- Two types of tasks
- Unifying two tasks
- Architecture (Janus & Janus Pro)
- Main Design Principle
- Image Encoders
- LLM Processing & Outputs
- Details: Rectified Flow
- Training Process
- Stage 1: Adaptation
- Stage 2: Unified Pre-Training
- Stage 3: Supervised Fine-Tuning
- Experiments
1. Introduction
DeepSeek
- DeepSeek-R1: LLM
- DeekSeek Janus Pro: Multimodal AI model
Two versions
- v1) “JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation.”
- v2) “Jannus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling.”
2. UNIFIED multimodal understanding & generation
Large Language Models (LLMs)
Multimodal Large language Models (MLLMs)
- e.g.,LLaVA
- Can feed the models both a (1) text prompt and an (2) image
(1) Two types of task
- Task 1) Image understanding
- Task 2) Image generation
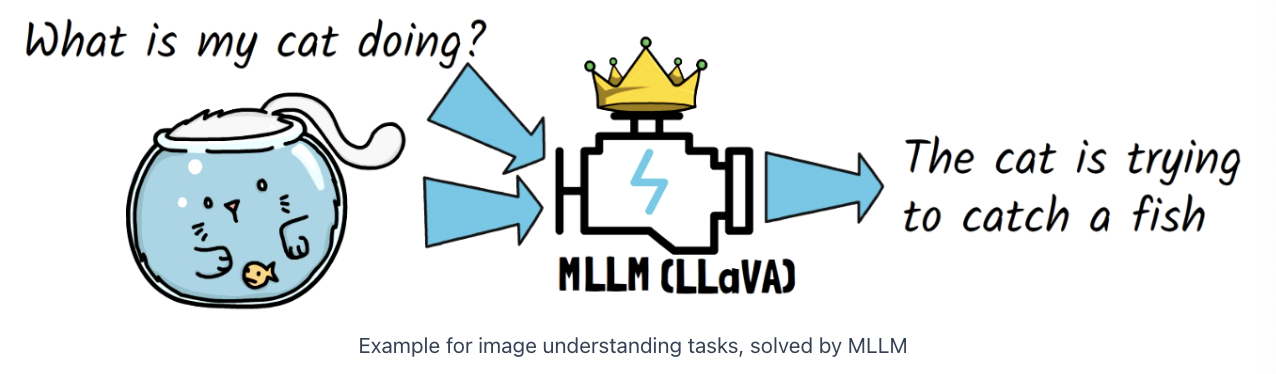

(2) Unifying two tasks
a) Unified model
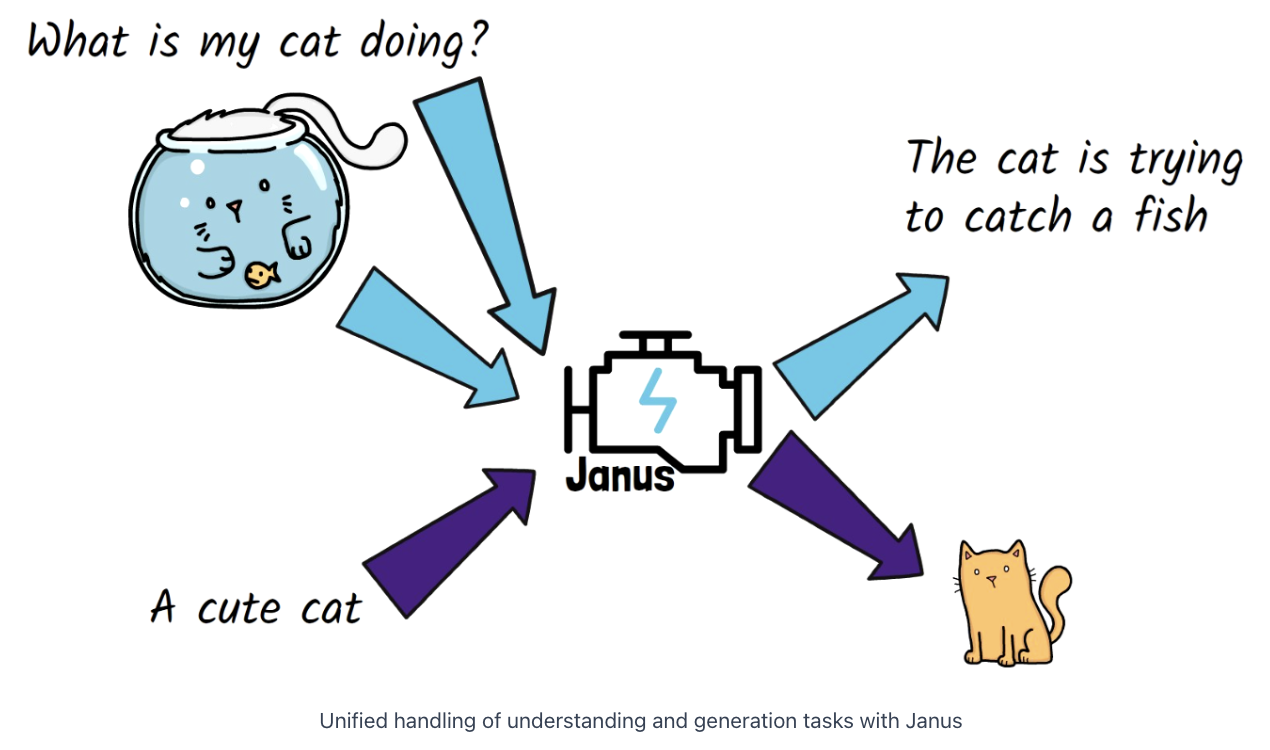
Unifying these two tasks into a single model!
\(\rightarrow\) Janus model
- Not the first attempt to achieve this unification…
- But why is it more successful?
b) Ex) Image understanding (by Janus Pro)
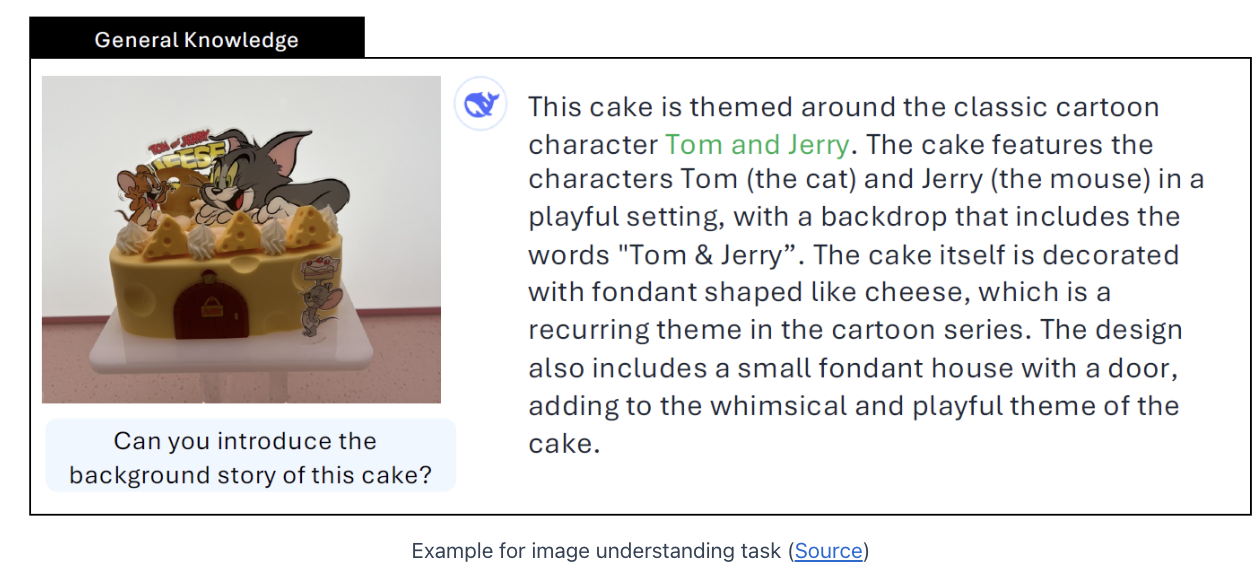
- Q) [Image] Asked about the background story of a cake
- A)
- Detects that the cake theme is Tom and Jerry
- Provides its background story
- Key point: Not only (1), but also (2)
- (1) Understand the image
- (2) Leverages its backbone to provide information beyond the image’s scope
- with general-purpose knowledge embedded in the LLM
3. Architecture (Janus & Janus Pro)
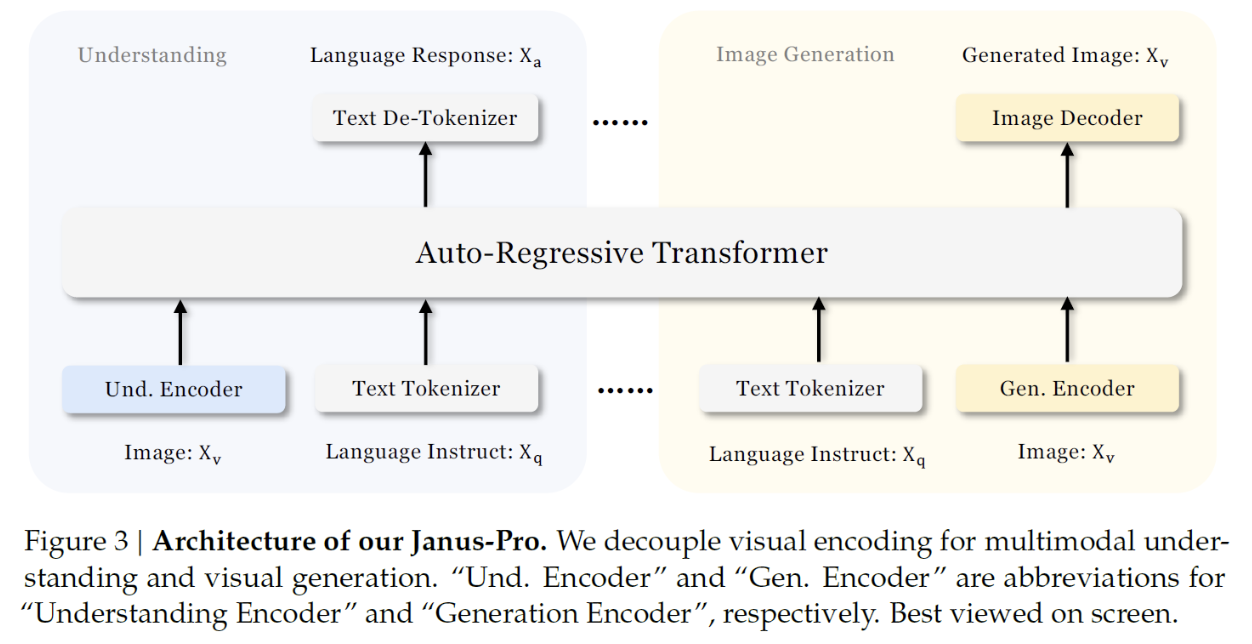
Core of the model = LLM (Autoregressive Transformer)
(1) Main Design Principle
(Previous) unified models
- Use a single image encoder (regardless to tasks)
Janus Pro
-
Findings: Encodings needed for each type of task are different
( \(\because\) Task interference )
-
Solution: Decouple visual encoding for ..
- (a) understanding
- (b) generation
\(\rightarrow\) Use different encoders for each type of task!
(2) Image Encoders
a) Encoder 1: for image understanding
- Step 1) Encoder: SigLIP
- Improved version of OpenAI’s CLIP model
- Extract representaiton with SigLIP
- Step 2) Mapping
- Linearly mapped to the input space of the LLM
b) Encoder 2: for image generation
- Step 1) Encoder: LlamaGen
- Autoregressive image generation model
- Vector quantization (VQ) tokenizer that converts an image to a list of IDs
- Step 2) Mapping
- Mapped to the input space of the LLM using a trained module
(3) LLM Processing & Outputs
LLM Processing
-
Concatenate “text” & “image” embeddings
\(\rightarrow\) Becomes the input sequence to LLM
Outputs for ..
- (1) Image understanding
- Generated using the LLM’s built-in prediction head
- (2) Image generation
- Another head is added to the LLM to consume its last hidden state
(4) Details: Rectified Flow
How is image generation performed?
\(\rightarrow\) Rectified flow method
-
Similar to diffusion models
-
Tries to find shortcuts and reduce noise,
in a way that significantly reduces the number of steps needed to reach a clear image
4. Training Process
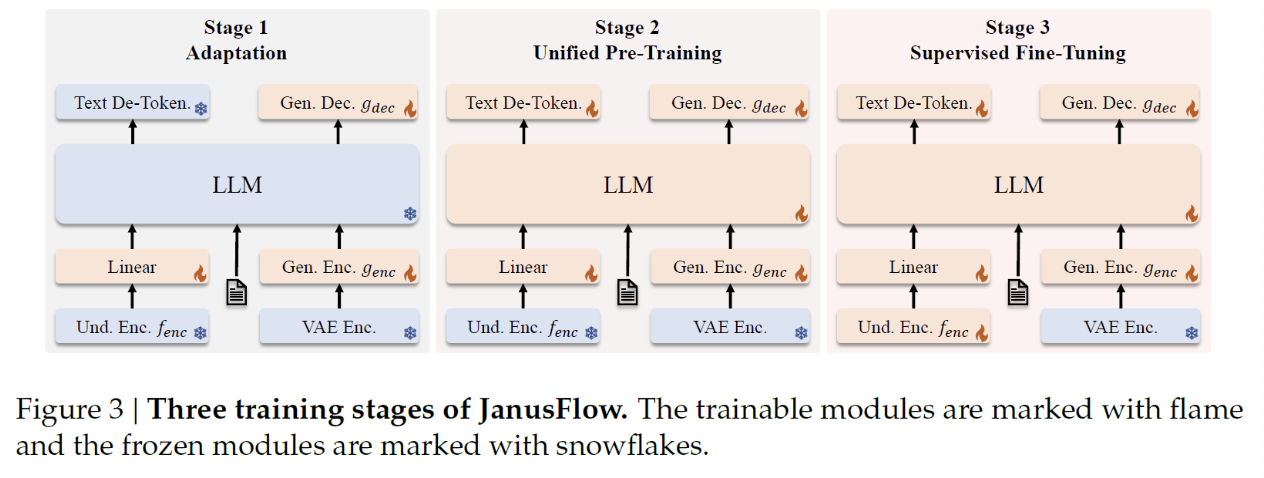
(Corresponds to both Janus & Janus Pro)
Both are trained in 3 stages!
(1) Stage 1: Adaptation
Goal: Adapt the new modules to work properly with the pre-trained components
Details:
- (1) Freeze: LLM & Image encoders
- (2) Tune: Newly introduced components
- (1) Linear: Map the encoded images to the LLM input space
- (2) Image generation head (Gen. Enc. \(g_{\text{enc}}\))
- (3) Dataset: ImageNet
- (4) Janus vs. Janus Pro
- Training steps on ImageNet are increased for Janus Pro
(2) Stage 2: Unified Pre-Training
Goal: Continue to train the new modules, but now we also train the LLM and its built-in text prediction head
Details
-
(1) Janus vs. Janus Pro
- Removal of ImageNet from this stage
- Janus Pro: Text-to-image data is directly utilized
- Janus: Starts with ImageNet data and gradually increased the ratio of text-to-image data
- Removal of ImageNet from this stage
-
(2) Others
-
Note that the image encoder representations are aligned in training with the image generation latent output
\(\rightarrow\) To strengthen the semantic coherence in the generation process!
-
(3) Stage 3: Supervised Fine-Tuning
Goal: Finetune on the instruction tuning dataset
Details
- (1) Dataset: instruction tuning dataset
- Comprises dialogues and high-quality text-to-image samples
- (2) Others
- Image understanding encoder is also trained
- (3) Janus vs. Janus Pro
- No difference
[LLM size] Janus vs. Janus Pro
- Janus: 1.5B
- Janus Pro: 7B
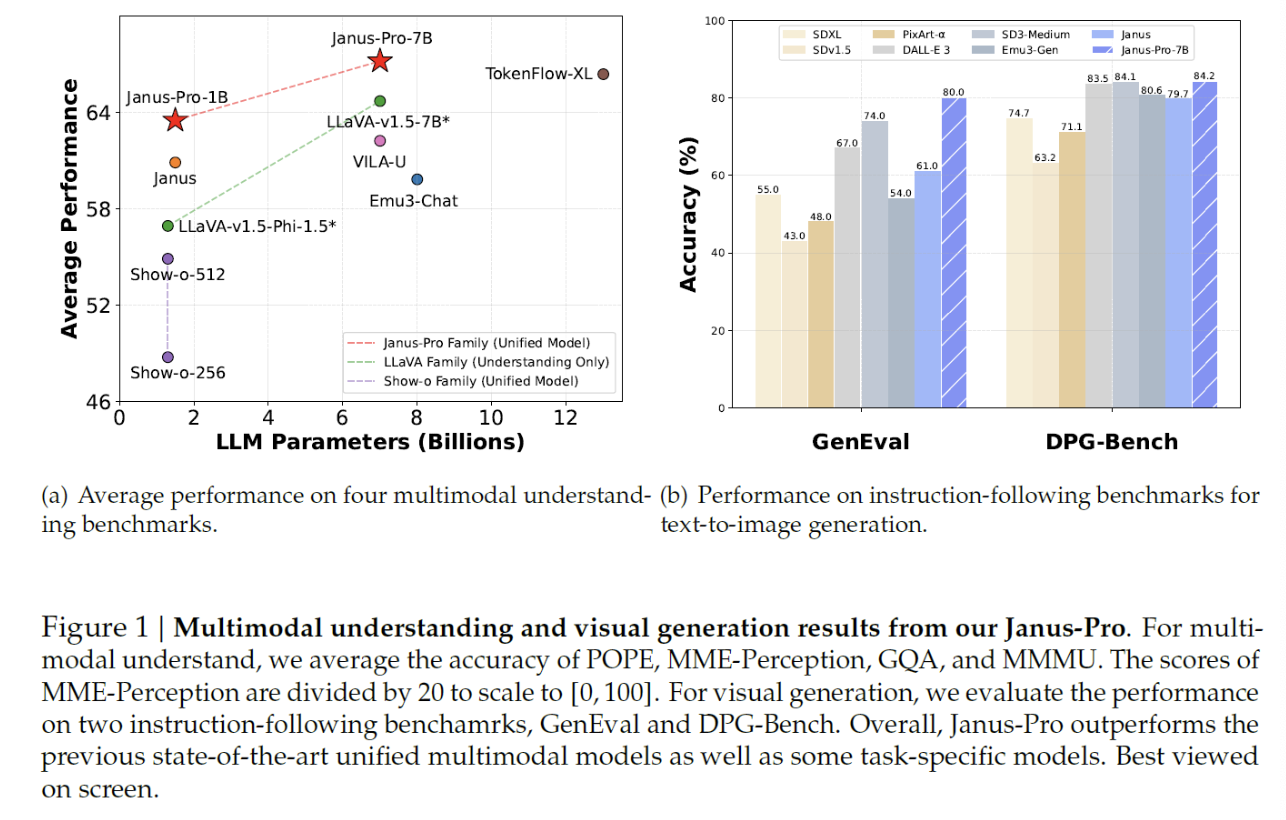
5. Experiments