
DINOv2: Learning Robust Visual Features without Supervision
Oquab, Maxime, et al. "Dinov2: Learning robust visual features without supervision." arXiv preprint arXiv:2304.07193 (2023).
참고:
- https://aipapersacademy.com/dinov2-from-meta-ai-finally-a-foundational-model-in-computer-vision/
- https://arxiv.org/pdf/2304.07193
Contents
- Introduction
- How to use DINO v2
- DINO v2 Models Distillation
- SSL with Large Curated Data
- Pixel Level Understanding
1. Introduction
DINOv2
- Computer vision model from Meta AI
- Foundational model
- Pretrained ViT model (1B params)
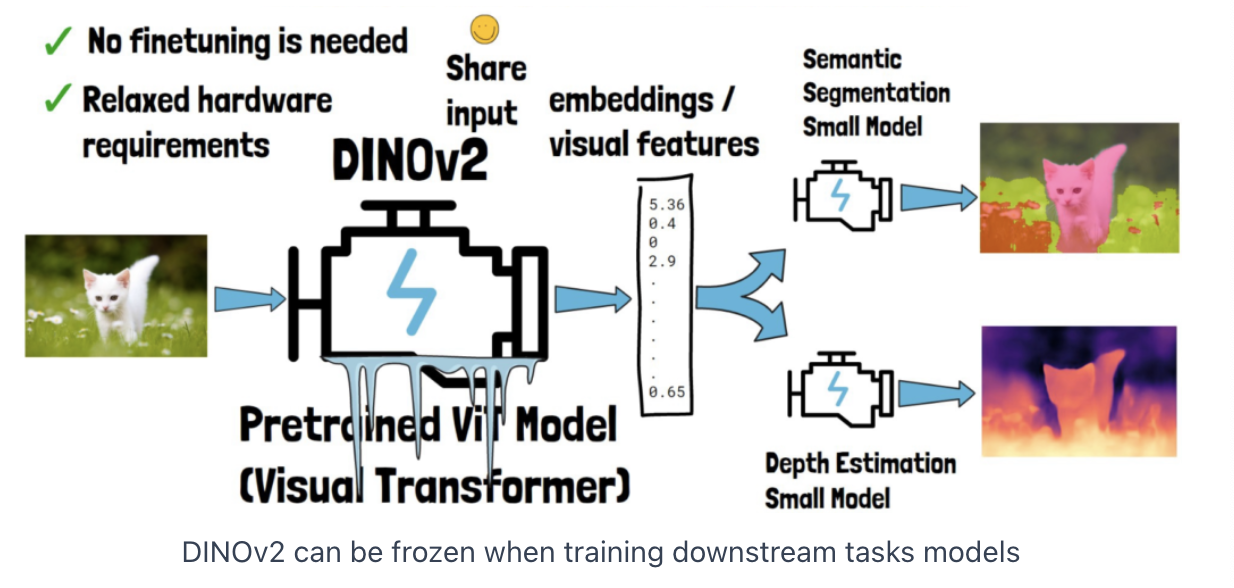
2. How to use DINO v2
Load it using pytorch code from DINOv2 GitHub page.)
import torch
dinov2_vits14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vits14')
dinov2_vitb14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14')
dinov2_vitl14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitl14')
dinov2_vitg14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitg14')
3. DINO v2 Models Distillation
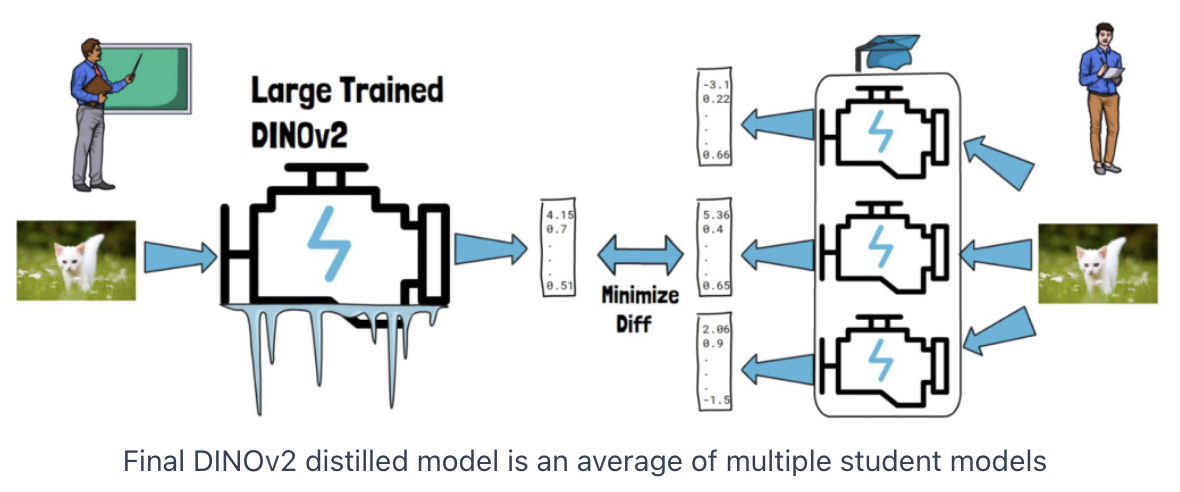
Teacher-student distillation
- (Teacher) Large pretrained DINOv2 model \(\rightarrow\) Freeze
- (Student) Smaller model \(\rightarrow\) Train
Distillation process
- Aims to minimize the difference between the embeddings
Findings: Better results with distillation (comparing to training smaller models from scratch)
- (In practice) Use multiple students (use the average values)
4. SSL with Large Curated Data
(Model size) DINOv2 > DINO
\(\rightarrow\) Need for more training data to train DINOv2 using SSL!
How to increase data size?
(Previous works) Increase uncurated data size with SSL
\(\rightarrow\) Drop in quality
-
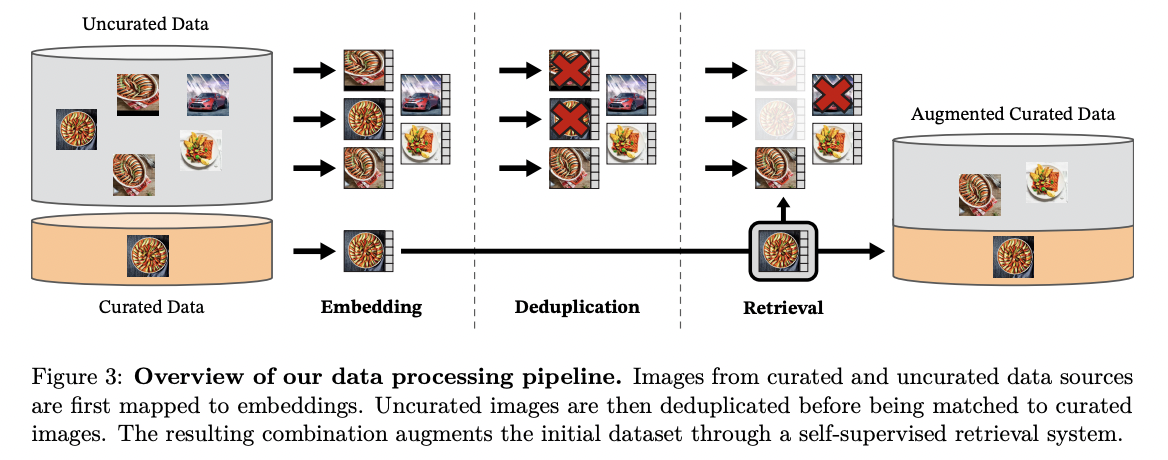
(DINOv2) Automated pipeline to create a curated dataset
\(\rightarrow\) Key factor for reaching SOTA
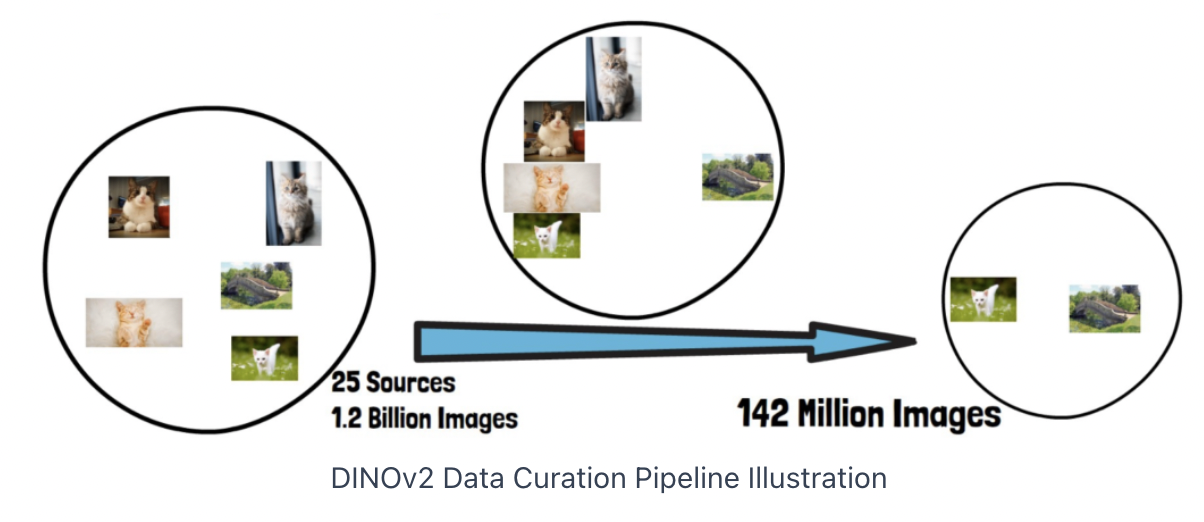
# of Data
- Starts from 25 sources of data that include 1.2 B images
- Results with 142M curated images.
Curation pipeline: Multiple filtering steps
- (Original uncurated dataset) Lot of cat images (comparing to non-cat images)
- Good in cat
- Bad in other domains
\(\rightarrow\) Solution: clustering
-
Grouping images based on similarities
-
Sample from each group a similar number of images
\(\rightarrow\) Enable to create a smaller but more diverse dataset!
5. Pixel Lvel Understanding
Remarkable capability to grasp pixel level information!