
I-JEPA: The First Human-Like Computer Vision Model
Assran, Mahmoud, et al. "Self-supervised learning from images with a joint-embedding predictive architecture." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
참고:
- https://aipapersacademy.com/i-jepa-a-human-like-computer-vision-model/
- https://arxiv.org/pdf/2301.08243
Contents
- Introduction
- SSL for Images
- I-JEPA
- Introduction
- Architecture
1. Introduction
I-JEPA
-
Image-based Joint-Embedding Predictive Architecture
- Open-source computer vision model (from Meta AI)
- More human-like AI
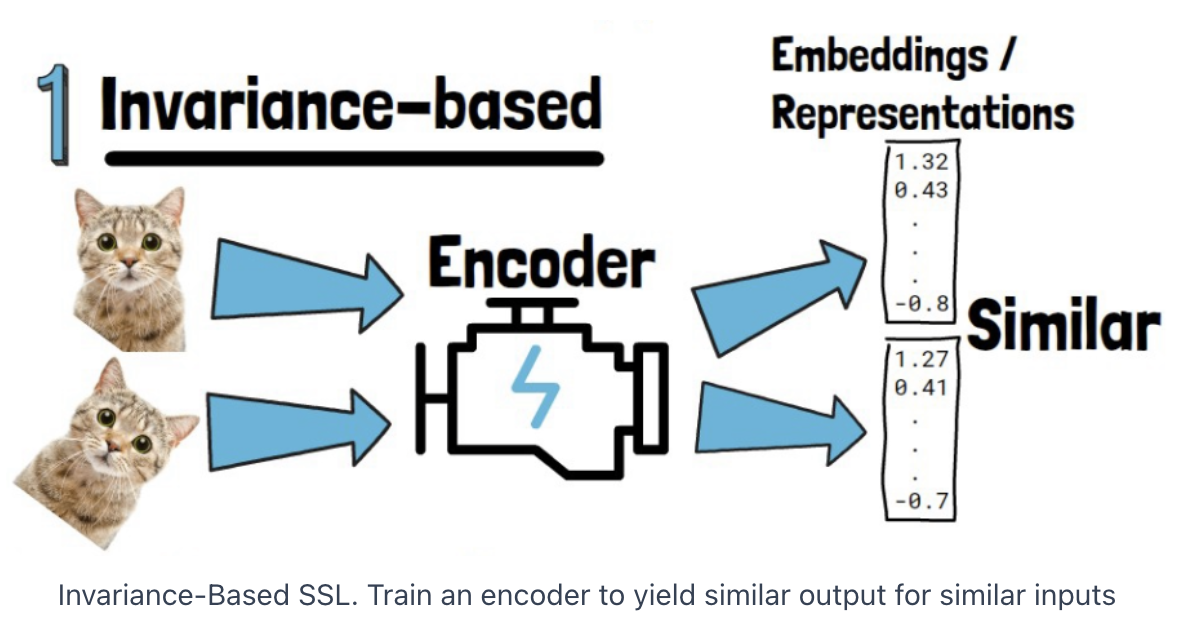
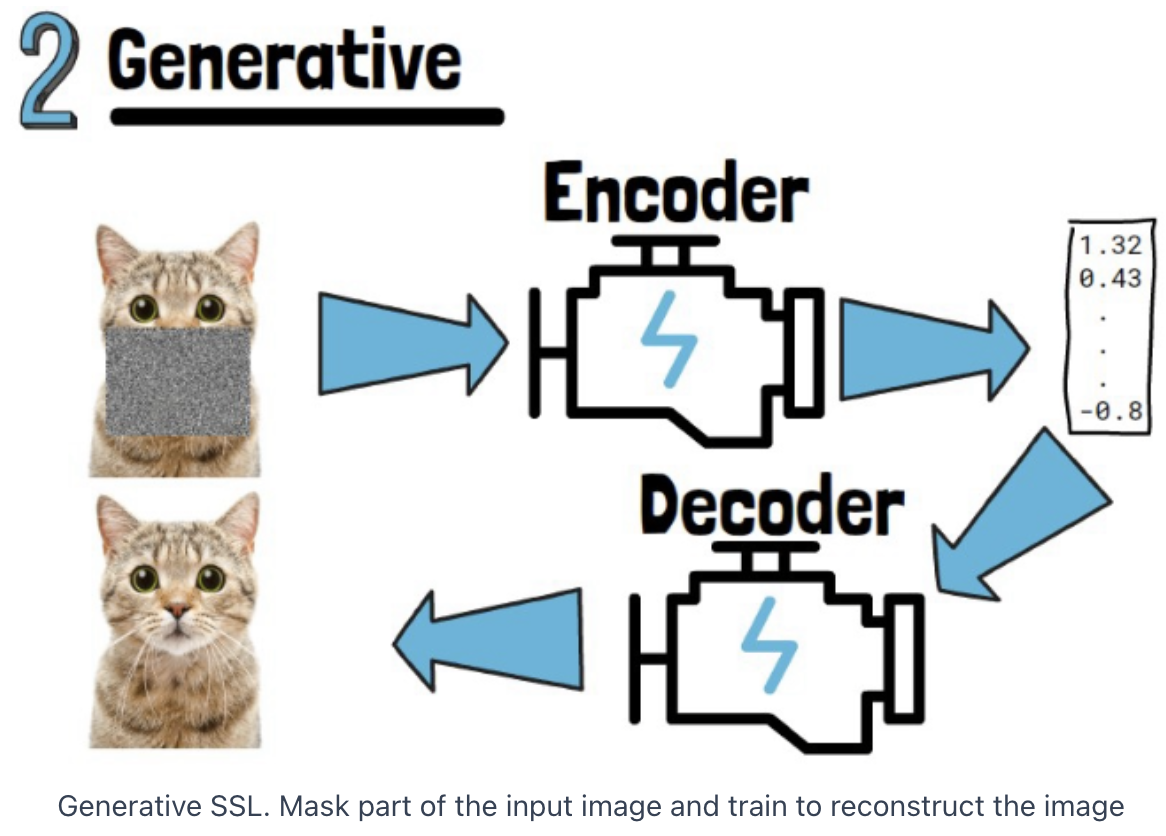
2. SSL for Images
2 common approaches for SSL from images
- (1) Invariance-based (e.g., CL)
- (2) Generative (e.g., MM)
Comparison
| Aspect | Invariance-based (e.g., CL) | Generative (e.g., MM) |
|---|---|---|
| Focus | Learns low-level features (e.g., textures, shapes) | Learns both low-level and high-level features (e.g., global context) |
| High-level Semantics | Struggles with high-level context (e.g., object relationships) | Better at understanding high-level concepts (e.g., scene or object understanding) |
| Low-level Semantics | Strong at low-level details (e.g., edges, patterns) | Good at low-level details, with more context around them |
| Best for High-level Tasks | Not ideal for tasks needing big-picture understanding | Great for tasks that need overall context (e.g., segmentation, captioning) |
| Best for Low-level Tasks | Excellent for detailed tasks (e.g., texture recognition) | Works well, but might be more complex than needed for simple tasks |
3. I-JEPA
(1) Introduction
Goal: Improve the semantic level of the representations
- w/o prior knowledge (e.g., data augmentation)
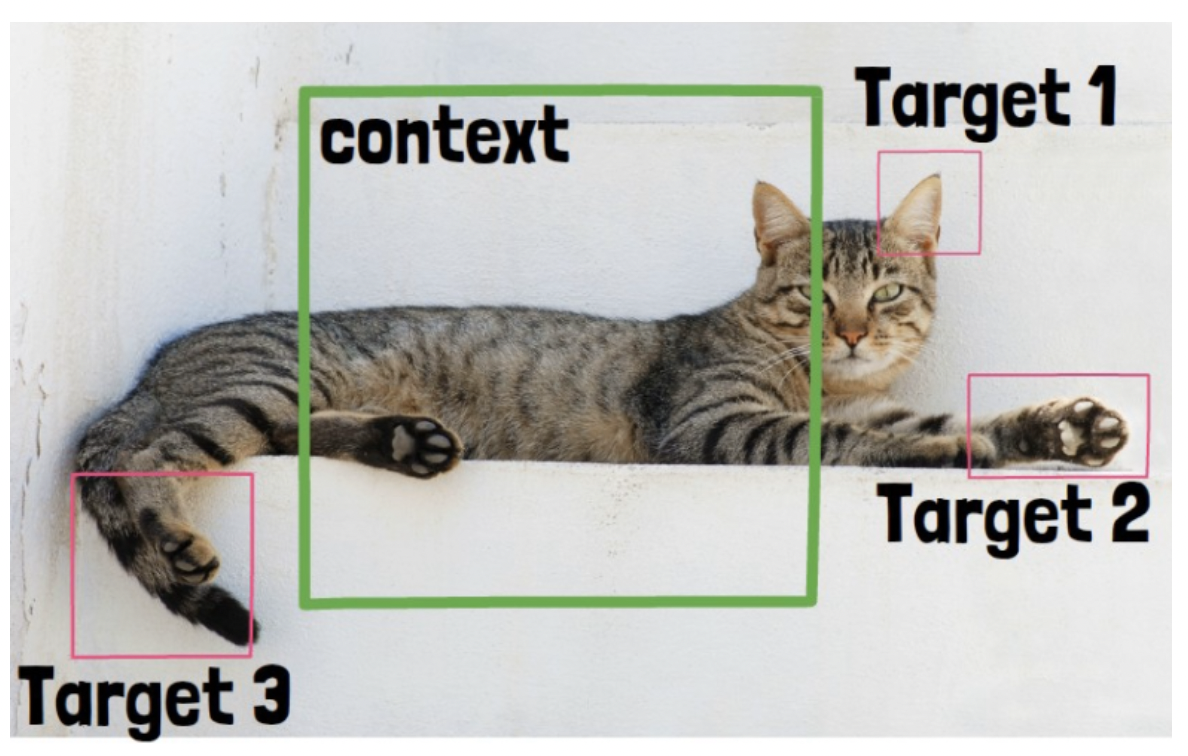
Main Idea: predict missing information in abstract representation space
(2) Architecture
Patchily: non-overlapping patches
3 components
- (1) Context encoder
- (2) Target encoder
- (3) Predictor
\(\rightarrow\) Each of them is a different Visual Transformer model.
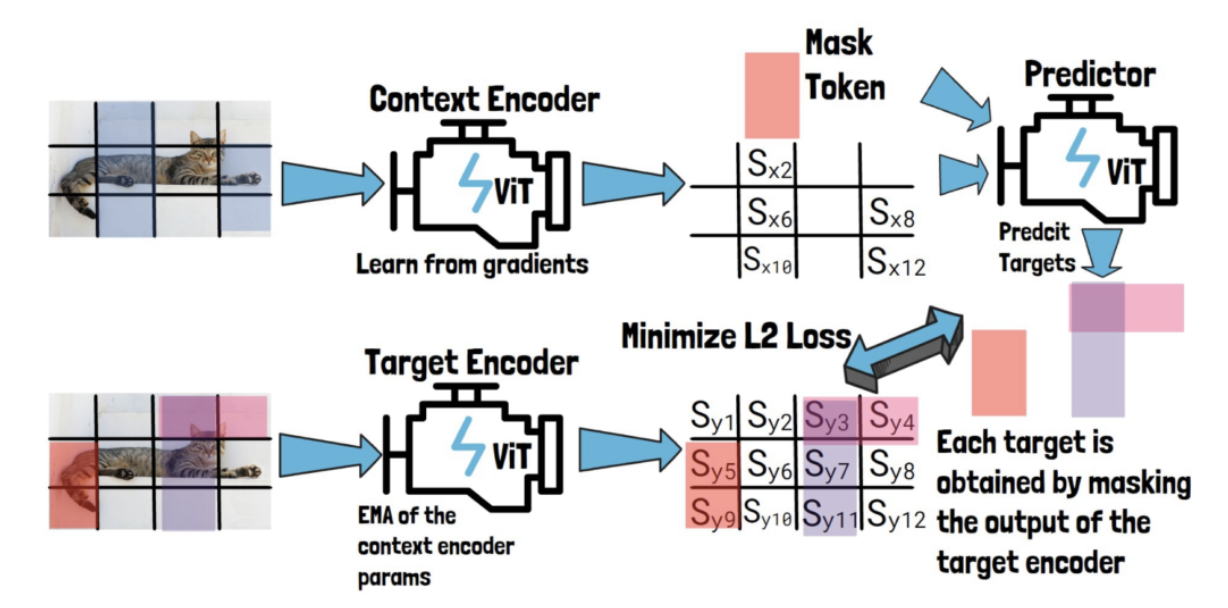
a) Target Encoder
-
(Input) Sequence of patches
-
(Output) Patch-level representations
-
Sampling target blocks
-
Sample blocks of patch-level representations (with possible overlapping)
\(\rightarrow\) Becomes a target blocks
-
Note that targets are in the representation space.
\(\rightarrow\) Thus, each target is obtained by masking “after” the target encoder!
-
b) Context Encoder
-
(Input) Sequence of patches
-
(Output) Patch-level representations
-
Sampling context blocks
-
Significantly larger in size than the target blocks
-
Sampled independently from the target block
\(\rightarrow\) There could be an overlap
\(\rightarrow\) Thus, remove the overlapping patches!
-

c) Predictor
-
Predict three target block representations.
-
For each target block representation, we feed the predictor with ..
-
(1) Output from the context encoder
-
(2) Mask token
( = Includes learnable vector and positional embeddings that match the target block location )
-
-
Loss: Average L2 distance between the predictions
EMA
Target encoder parameters are updated using EMA of the context encoder parameters.