
Sapiens: Foundation for Human Vision Models
Khirodkar, Rawal, et al. "Sapiens: Foundation for human vision models." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024.
참고:
- https://aipapersacademy.com/sapiens/
- https://arxiv.org/pdf/2408.12569
Contents
- Various tasks
- Humans-300M
- Construction
- Statistics
- Dataset Comparison
- SSL Pretraining
- Task-specific Models
- Experiments
1. Various tasks
Sapiens: Foundation for Human Vision Models
- Family of models that target four fundamental human-centric tasks
- by Meta AI

- Pose Estimation: Detects the location of key points of the human body in the input image.
- Body-part Segmentation: Determines which pixels combine the different body parts.
- Depth Estimation: Determines the depth of the pixels
- front = brighter, back = darker
- Surface Normal Estimation: Provides orientation about the shape of the object
2. Humans-300M
(1) Construction
Curating a Human Images Dataset
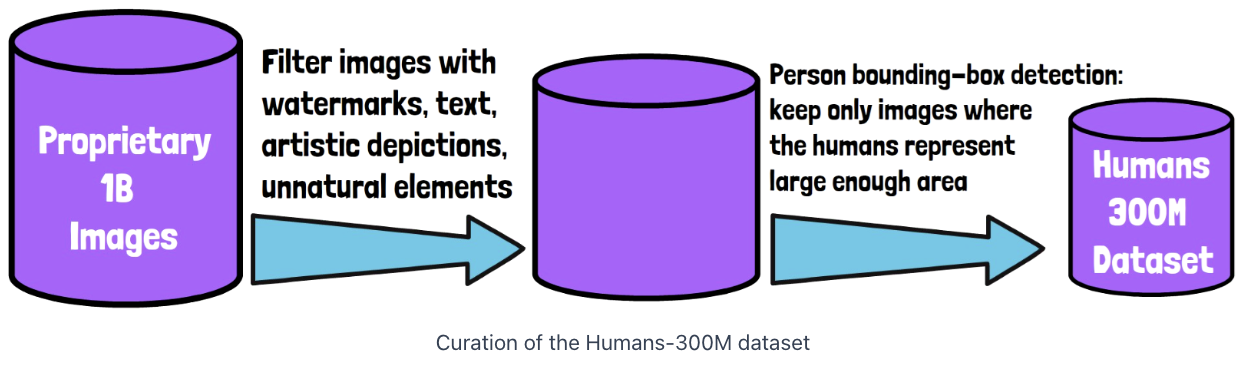
(2) Statistics
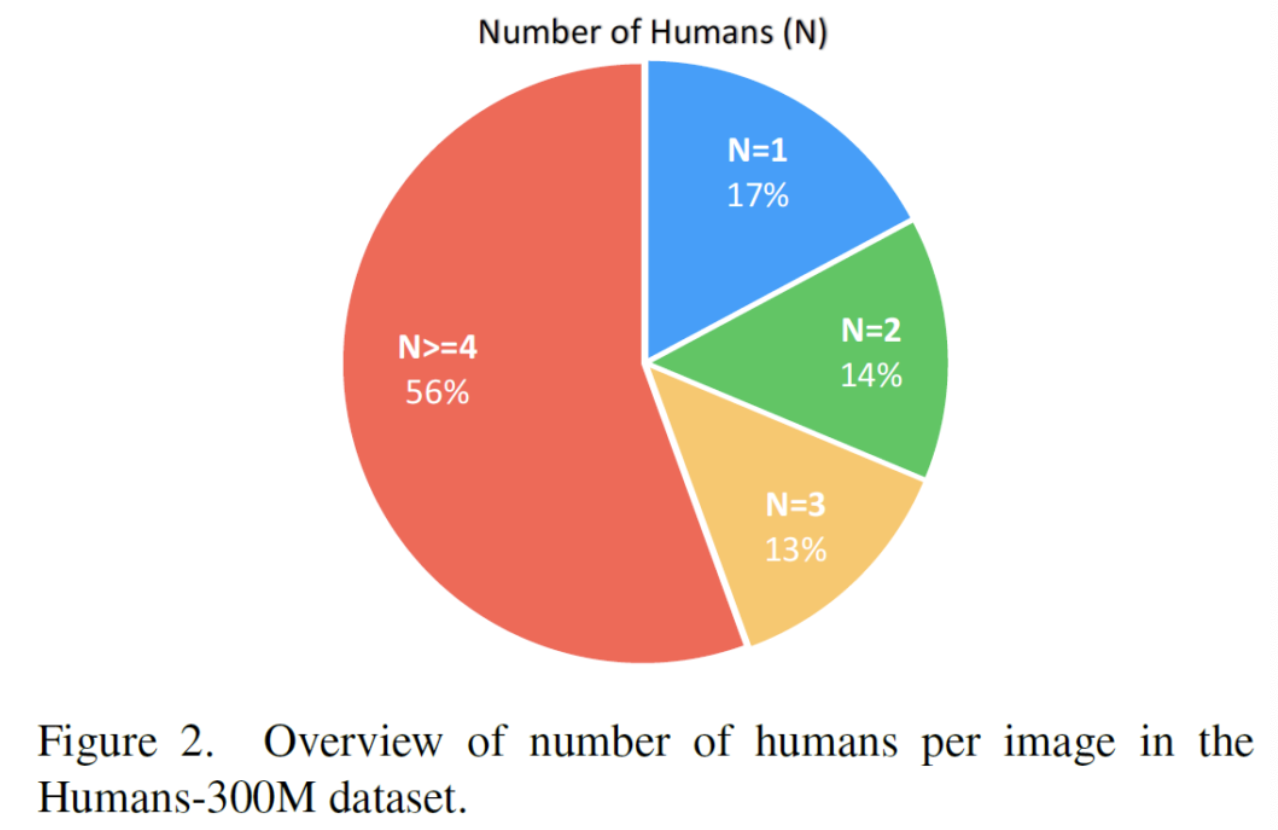
(3) Dataset Comparison
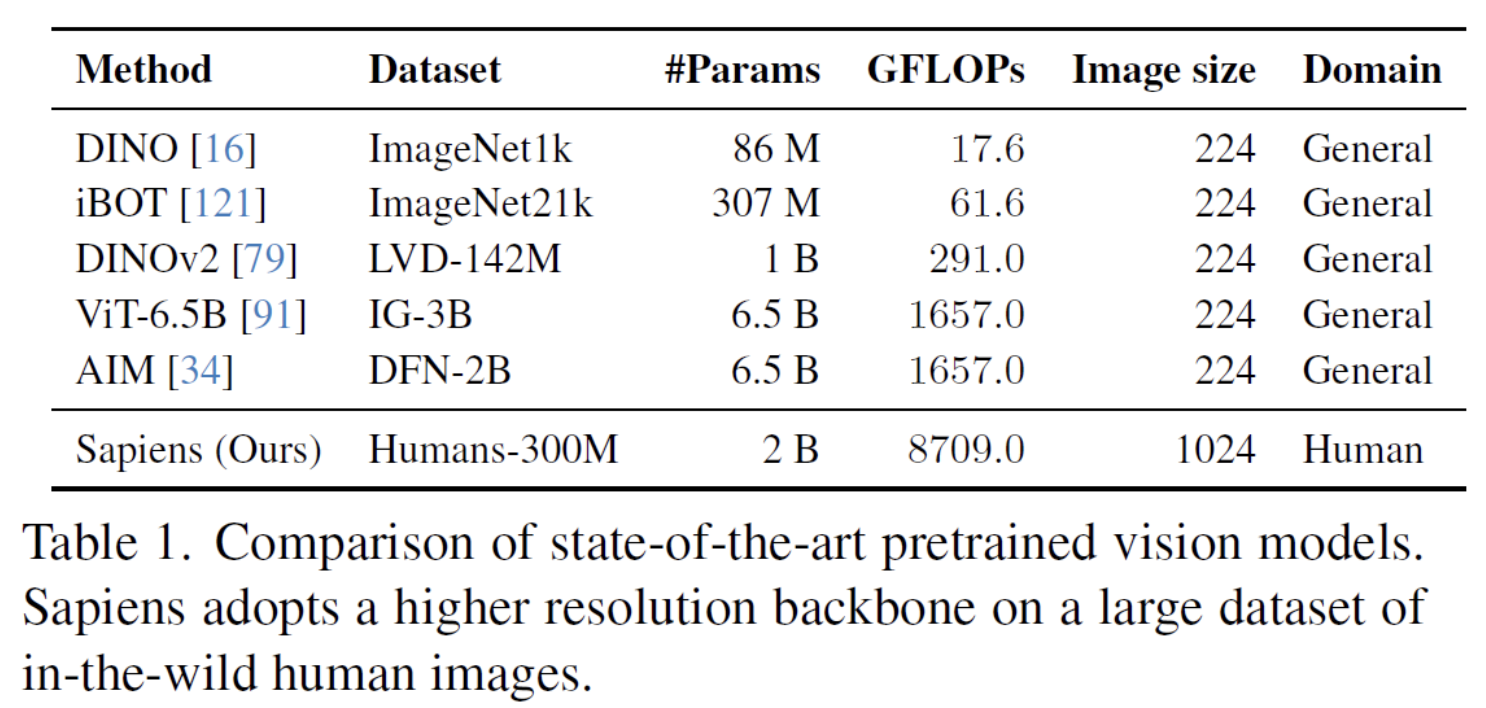
3. SSL Pretraining
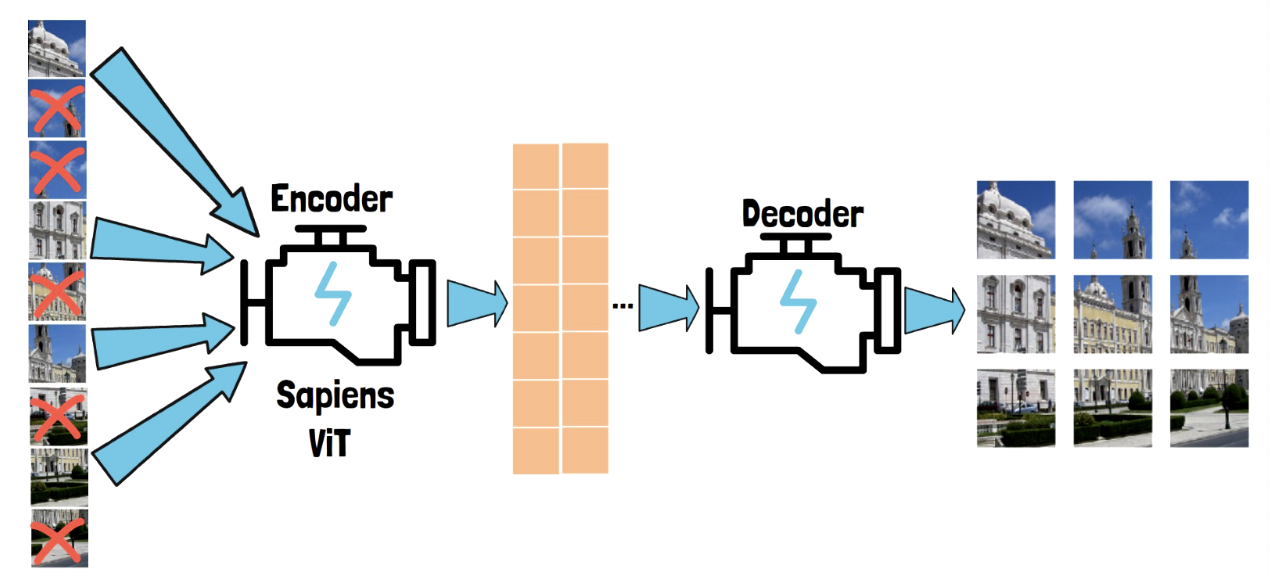
- Pretraining task: MAE (Masked Auto Encoder)
- Encoder: Vision Transformer (ViT) architecture
4. Task-specific Models
Using the pretrained model..
- Add a new task-specific decoder model
- For each task: Small labeled dataset
\(\rightarrow\) Do this for 4 different tasks!
5. Experiments
(1) Reconstructed Results
Reconstructed results (Pretraining quality)
