
( 참고 : 패스트 캠퍼스 , 한번에 끝내는 컴퓨터비전 초격차 패키지 )
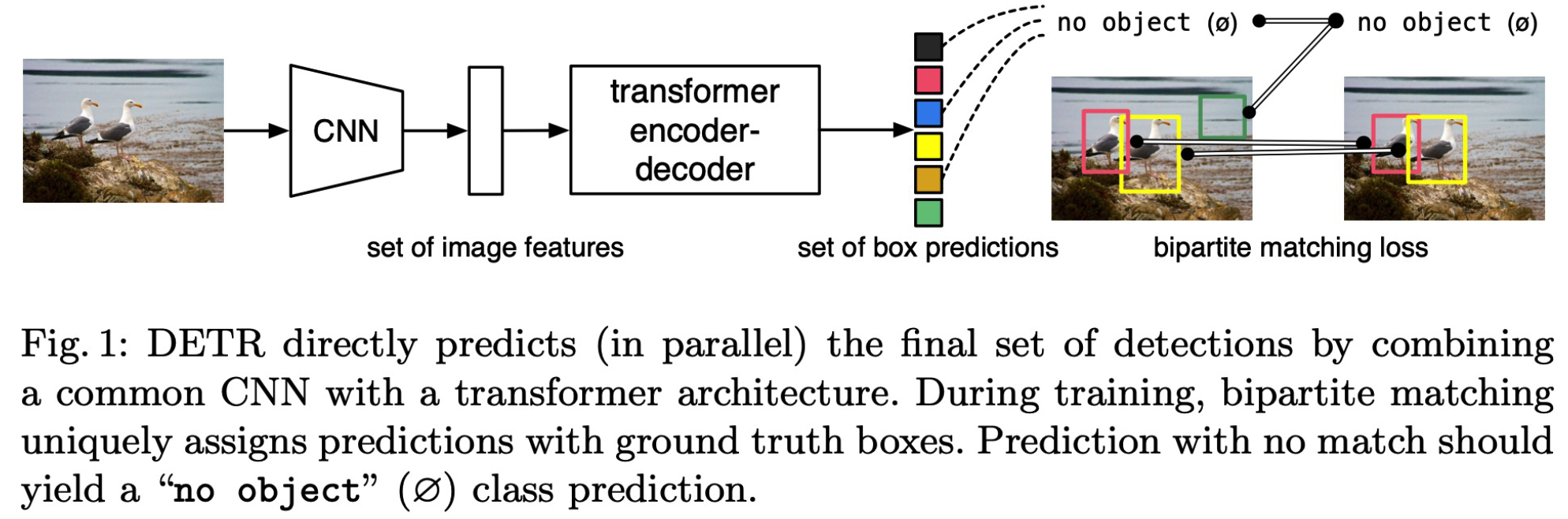
DeTR - Detection Transformer
( End-to-End Object Detection with Transformers, Carion et al. ECCV 2020 )
DeTR = Vision Transformer for Object Detection
- no need for hand-crafted engineering! ( NMS, RPN … )
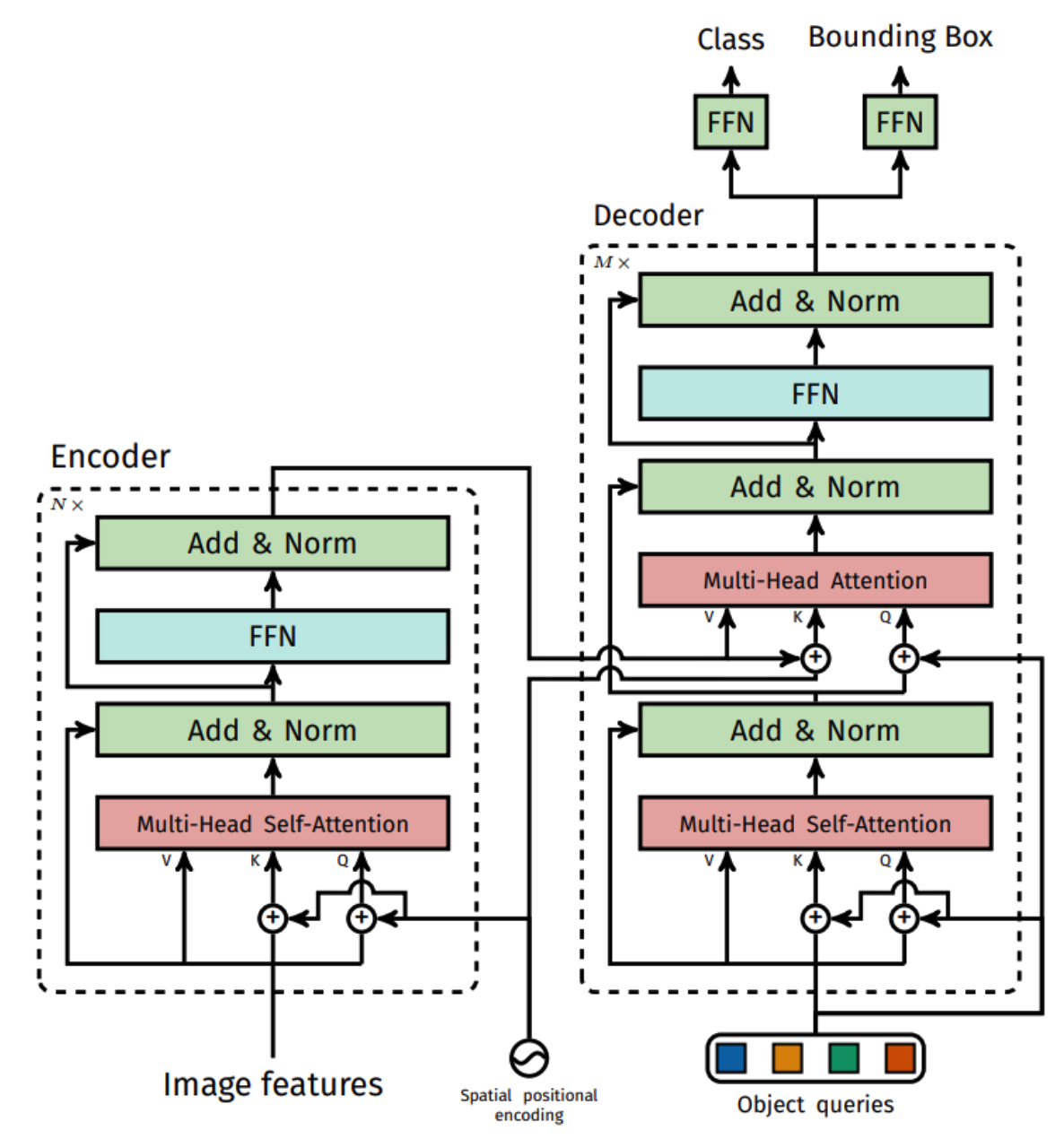
1. BackBone & Encoder
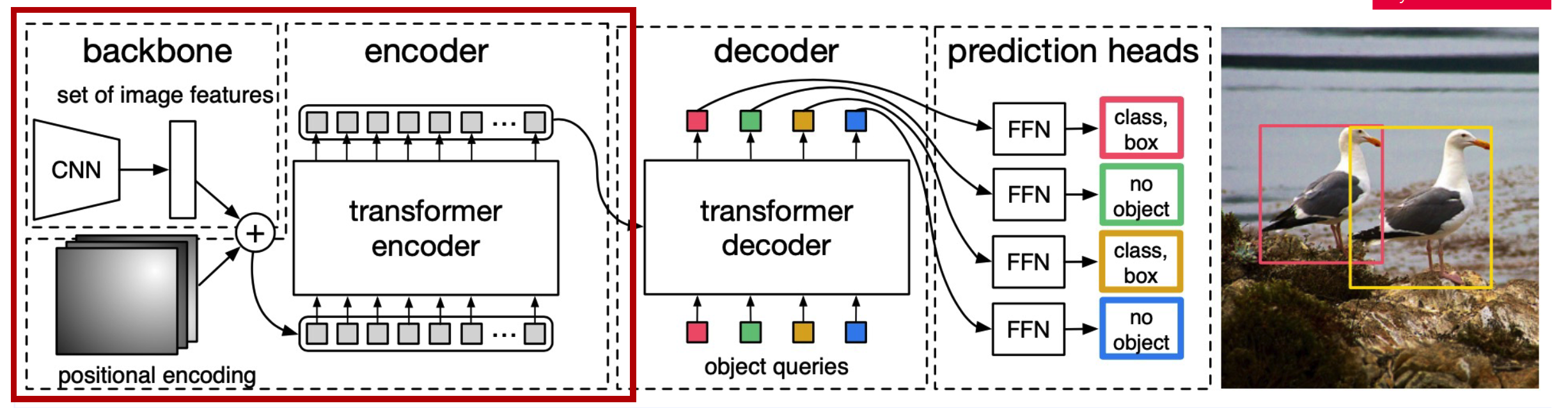
-
feature extraction with CNN Backbone
( + fixed positional encoding )
-
Transformer encoder :
- Input : pixels ( \(d \times HW\) ) of feature map
- stack multiple multi-head self attention
2. Decoder
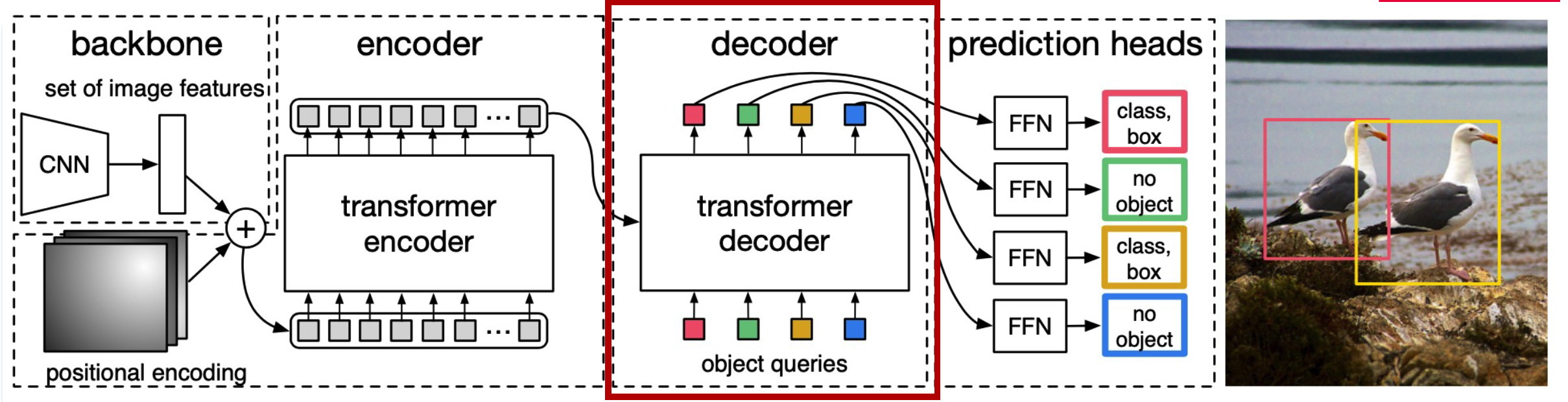
-
Transformer decoder :
-
input : object queries ( = predefined number … 100 )
-
Attention
- (1) Multi-head Self-Attention
- Q,K,V : from object queries
- (2) Multi-head Attention
- Q : from object queries
- K,V : from encoder embedding
- (1) Multi-head Self-Attention
-
3. Prediction Head
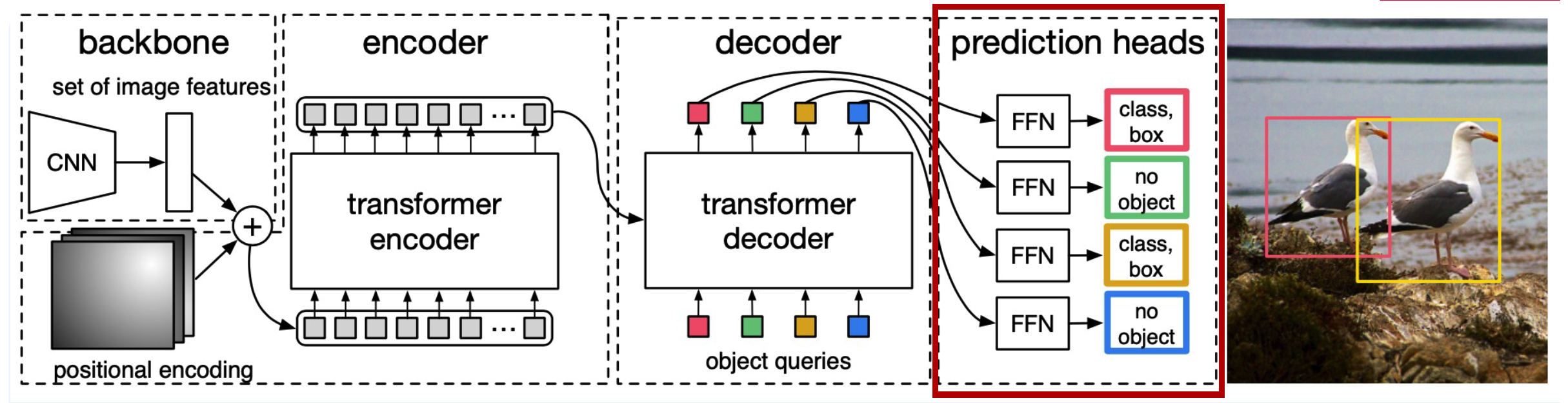
with FC layers… estimate a
- bounding box
- bounding box’s class label
per object query
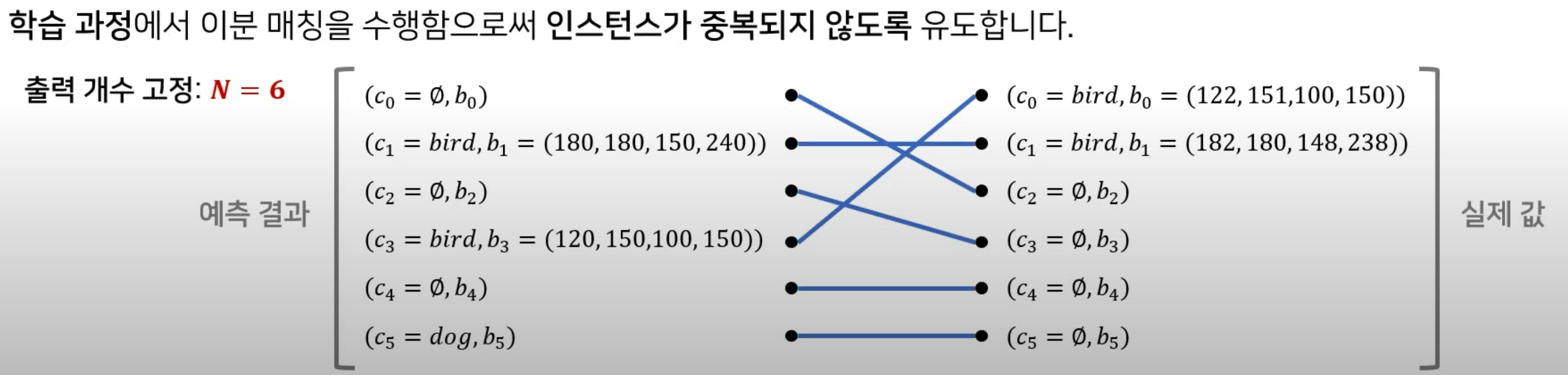
4. Bipartite Matching
how to match Y_real.& Y_pred ?
\(\rightarrow\) Hungarian Matching!
5. Loss Function
Notation
- Y_pred : set of \(N\) predictions \(\hat{Y}\)
- Y_real : set of groundtruth \(Y\)
- padding \(\empty\) for “no object”
Bipartite Matching : with Hungarian Matching
\(\rightarrow\) search for a permutation with lowest matching cost
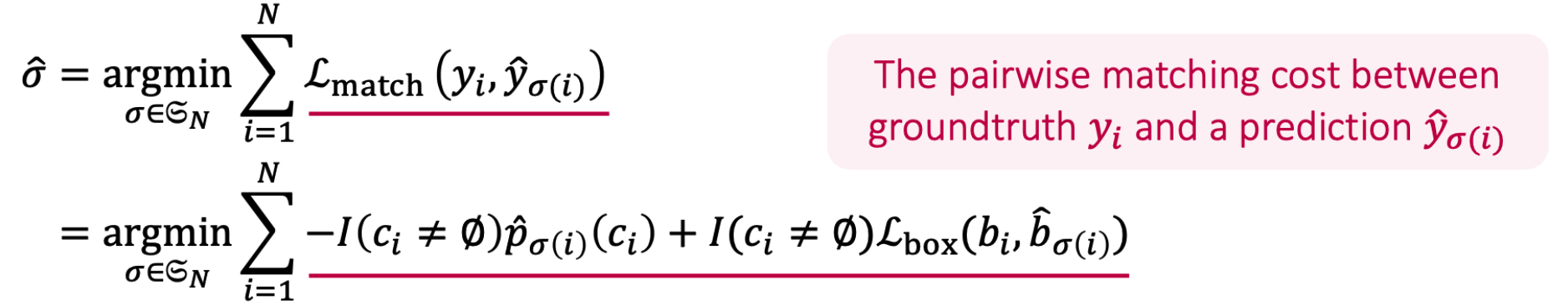
Final Loss Function
- \(\mathcal{L}(Y, \widehat{Y})=\sum_{i=1}^{N}\left[-\log \hat{p}_{\widehat{\sigma}(i)}\left(c_{i}\right)+I\left(c_{i} \neq \varnothing\right) \mathcal{L}_{\mathrm{box}}\left(b_{i}, \hat{b}_{\widehat{\sigma}(i)}\right)\right]\).