
( 참고 : 패스트 캠퍼스 , 한번에 끝내는 컴퓨터비전 초격차 패키지 )
Transformer for OD and HOI
1. DETR (Detection Transformer)
( Carion, Nicolas, et al. “End-to-end object detection with transformers.” European conference on computer vision. Springer, Cham, 2020. )
- https://arxiv.org/pdf/2005.12872
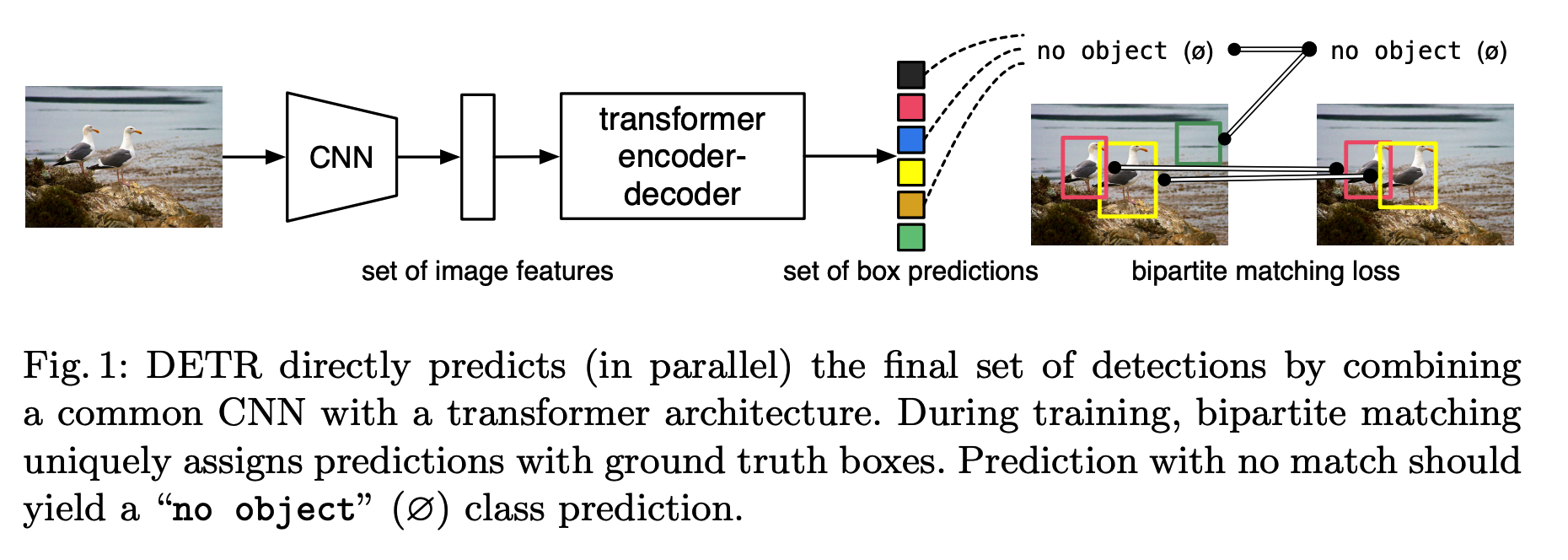
- for more details… https://seunghan96.github.io/cv/vision_22_DETR/
DETR = 3 main components
- (1) CNN backbone
- to extract compact feature representation
- (2) encoder-decoder transformer
- (3) simple FFN
- makes final prediction
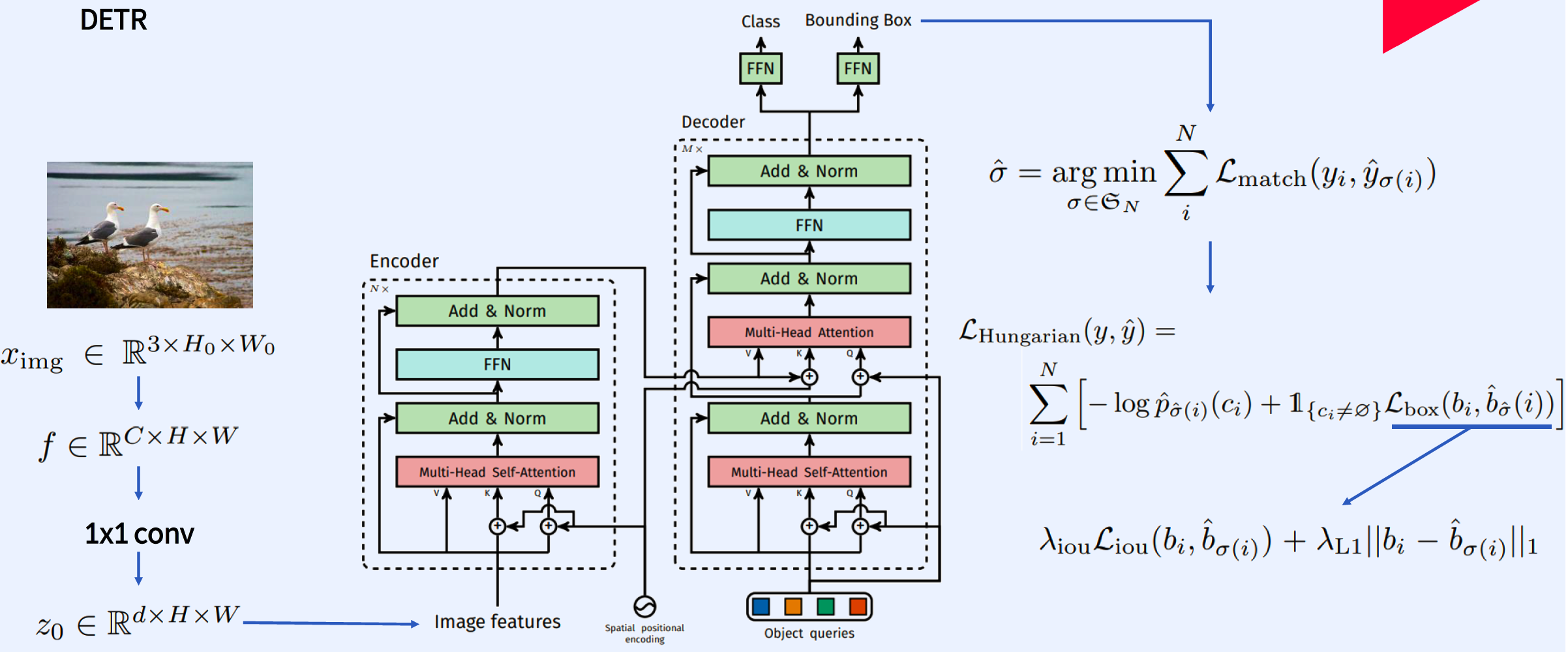
(1) CNN backbone
- Input image : $x_{\mathrm{img}} \in \mathbb{R}^{3 \times H_{0} \times W_{0}}$
- Lower-resolution activation map : $f \in \mathbb{R}^{C \times H \times W}$
- $C=2048$
- $H, W=\frac{H_{0}}{32}, \frac{W_{0}}{32}$.
(2-1) Transformer Encoder
-
1x1 convolution : reduce channel dimension of $f$
-
from $C$ to $d$
-
new feature map : $z_{0} \in \mathbb{R}^{d \times H \times W}$
-
-
squeeze : $d \times H \times W \rightarrow d \times H $
- (since encoder expects a sequence as input)
- total of $d$ sequences, with $HW$ dimension
-
Encoder
- multi-head self-attention module
- feed forward network (FFN)
-
Fixed positional encodings
- $\because$ transformer architecture = permutation-invariant
(2-2) Transformer Decoder
- transforming $N$ embeddings of size $d$
- difference with original transformer :
- (original) autoregressive model that predicts the output sequence one element at a time
- (proposed) decodes the $N$ objects in parallel
(3) simple FFN
-
$N$ object queries are transformed into an output embedding by the decoder
-
then, independently decoded into
- (1) box coordinates
- **(2) class labels
by FFN
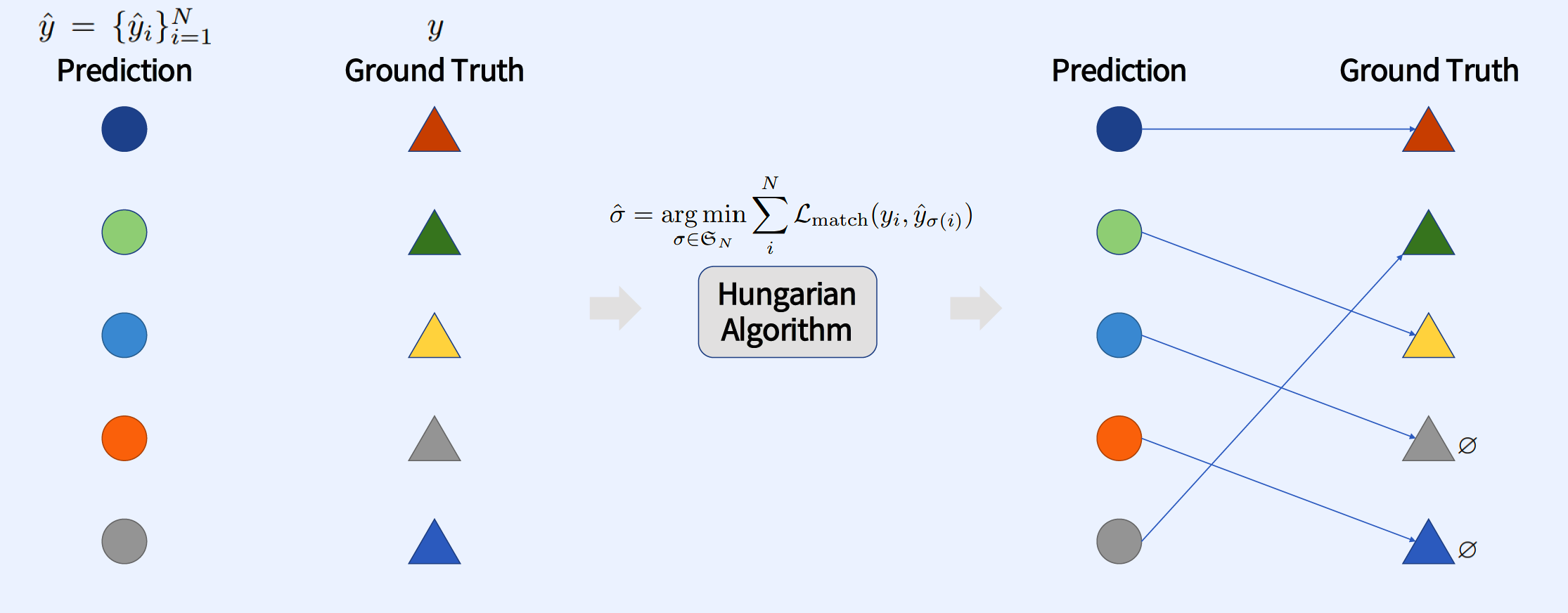
Hungarian Algorithm
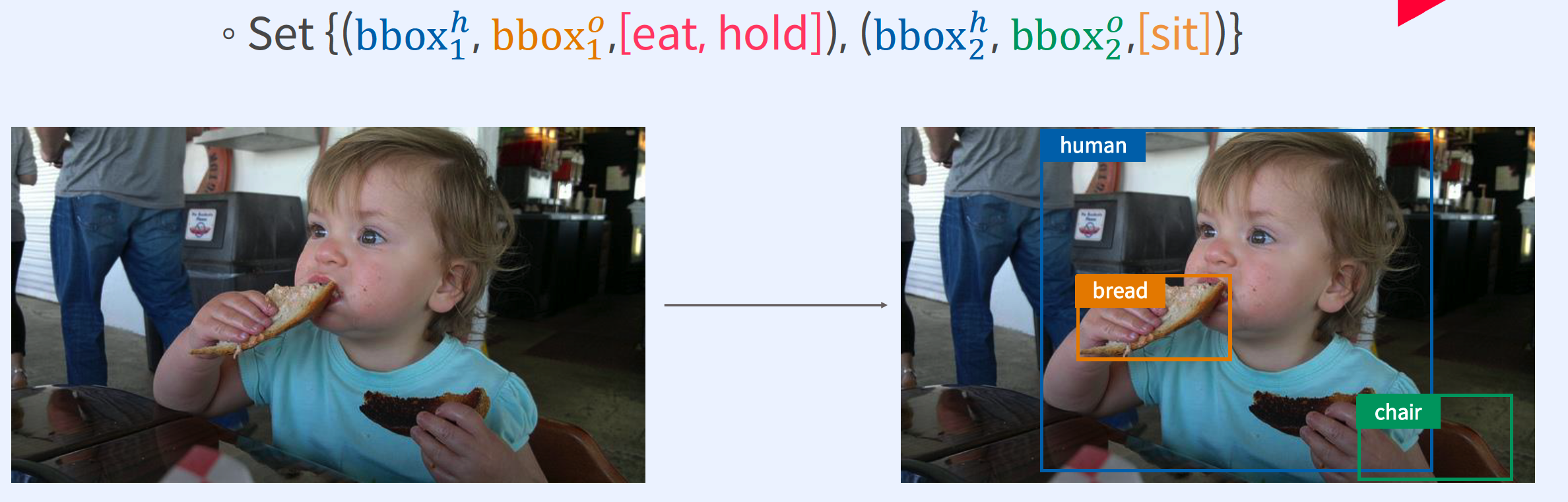
2. HOI Detection Task?
HOI = Human-Object Interaction
3. InteractNet
( Gkioxari, Georgia, et al. “Detecting and recognizing human-object interactions.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. )
- https://arxiv.org/pdf/1704.07333
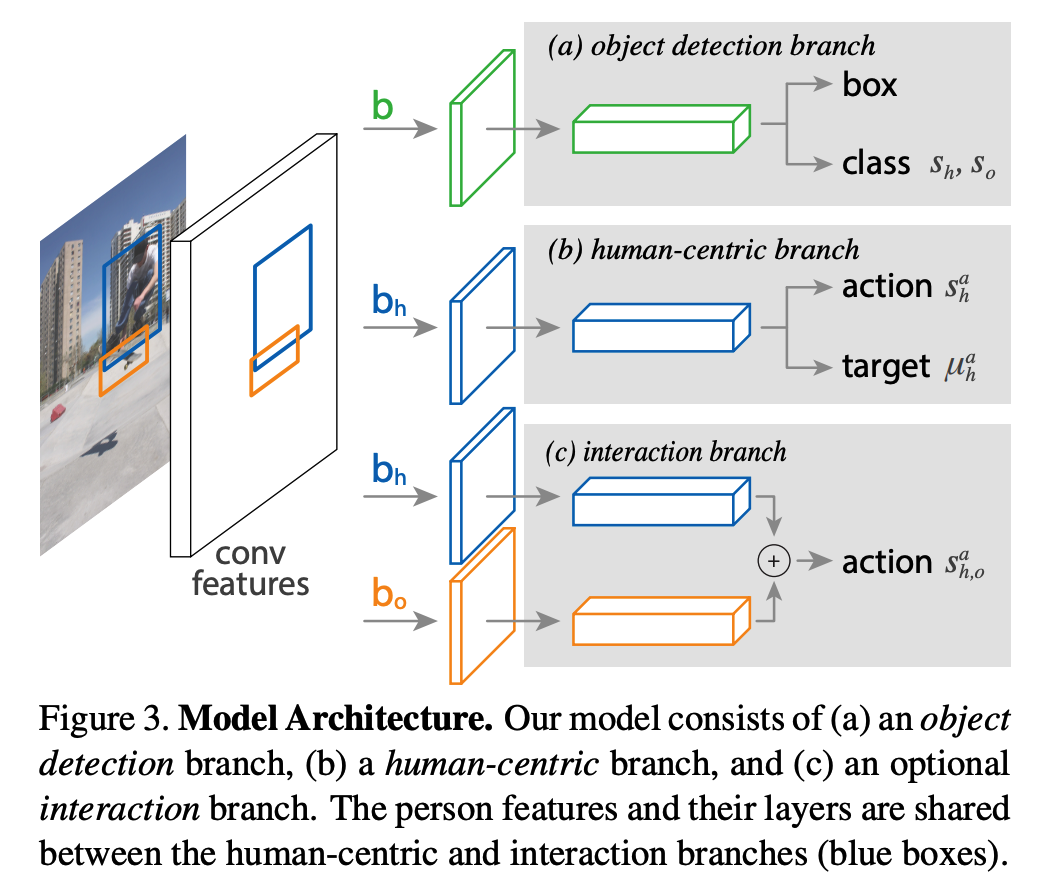
Goal : detect triplets of the form < human, verb, objective >
- (1) localize the …
- box containing a human ( $b_h$ )
- box for the associated object of interaction ( $b_o$ )
- (2) identify the action ( selected from among $A$ actions )
(1) Object Detection branch
( identical to that of Faster RCNN )
- step 1) generate object proposals with RPN
- step 2) for each proposal box $b$…
- extract features with RoiAlign
- perform (1) object classification & (2) bounding-box regression
(2) Human Centric branch
Role 1) Action Classification
assign an action classification score $s^a_h$ to each human box $b_h$ and action $a$
( just like Object Detection branch … )
- extract features with RoiAlign from $b_h$
Human can simultaneously perform multiple actions…
- output layer : binary sigmoid classifiers for multilabel action classification
Role 2) Target Localization
predict the target object location based on a person’s appearance
- predict a density over possible locations, and use this output together with the location of actual detected objects to precisely localize the target.

(3) Interaction branch
human-centric model
-
scores actions based on the HUMAN appearance
-
problem : does not take into account the appearance of the TARGET object
3. iCAN
( Gao, Chen, Yuliang Zou, and Jia-Bin Huang. “ican: Instance-centric attention network for human-object interaction detection.” arXiv preprint arXiv:1808.10437 (2018). )
- https://arxiv.org/pdf/1808.10437.pdf
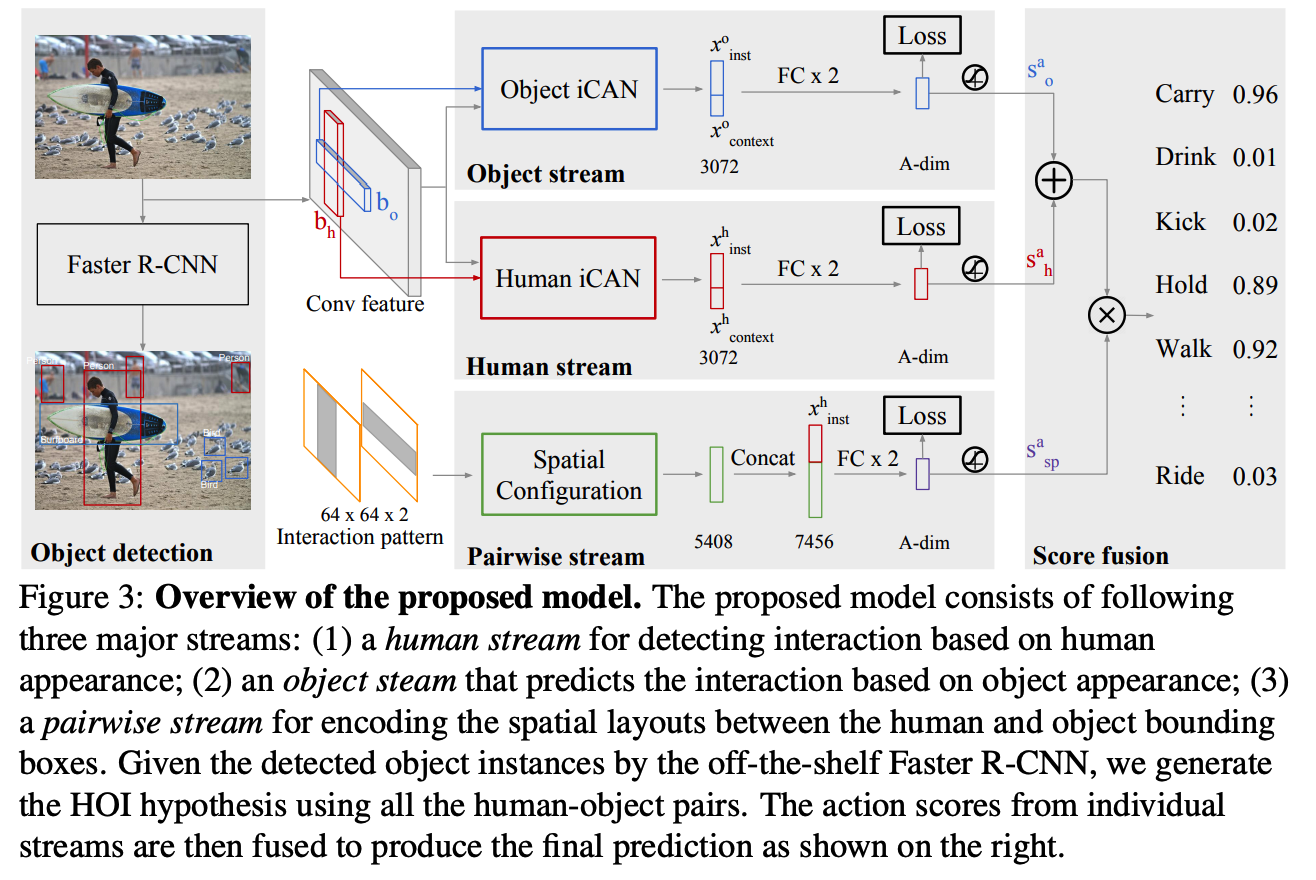
(1) Notation
- goal : predict HOI scores $S_{h, o}^{a}$, for each action $a \in{1, \cdots, A}$
- human-object bounding box pair : $\left(b_{h}, b_{o}\right)$
- $S_{h, o}^{a}=s_{h} \cdot s_{o} \cdot\left(s_{h}^{a}+s_{o}^{a}\right) \cdot s_{s p}^{a}$.
- score $S_{h, o}^{a}$ depends on..
- (1) confidence for the individual object detections ( $s_h$ & $s_o$ )
- (2) interaction prediction based on the appearance of the person $s_{h}^{a}$ and the object $s_{h}^{a}$
- (3) score prediction based on the spatial relationship between the person and the object $s_{s p}^{a}$.
- For some action classes w.o objectes ( ex. walk & smile )
- final scores : $s_{h} \cdot s_{h}^{a}$
(2) iCAN (Instance-Centric Attention Network) module
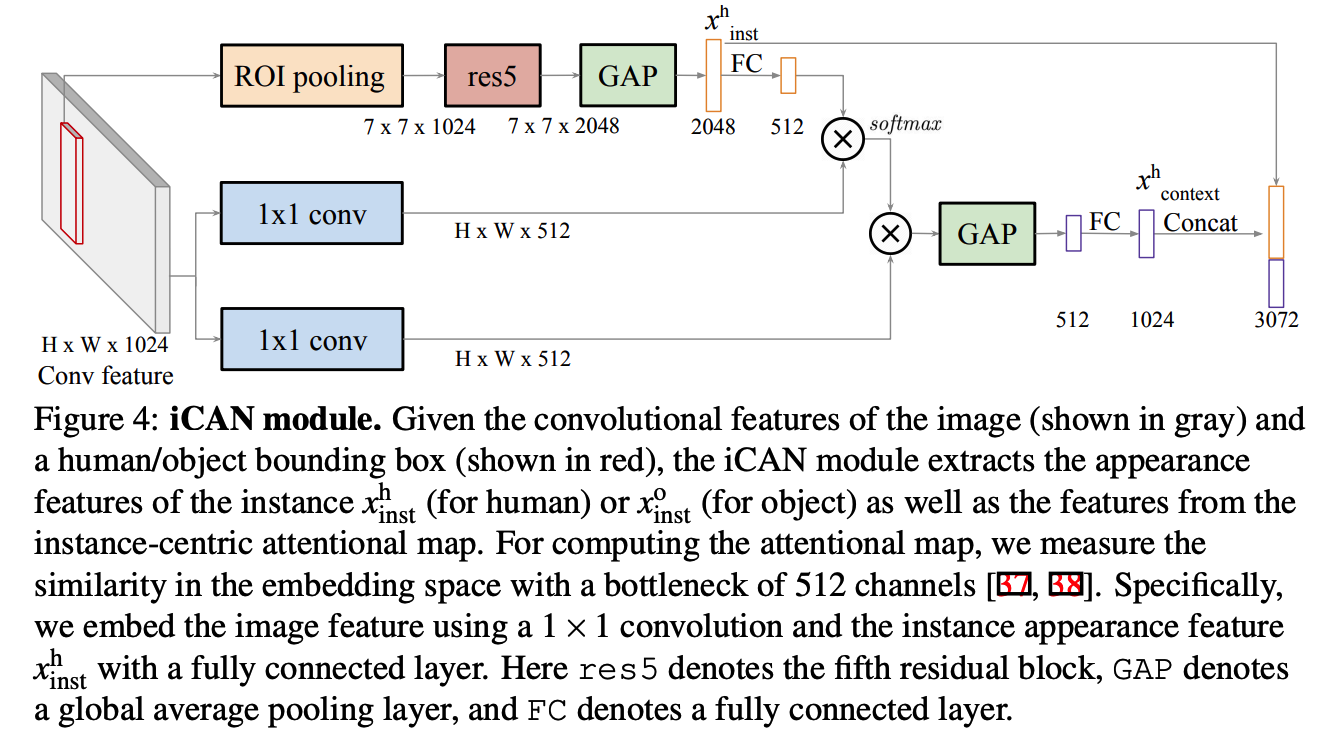
(3) Human / Ojbect stream
extract both..
- (1) instance-level appearance feature
- for a person : $x_{\text{inst}}^h$
- for an object : $x_{\text{inst}}^o$
- (2) contextual features
- for a person : $x_{\text{context}}^h$
- for an object : $x_{\text{context}}^o$
based on attentional map
with 2 feature vectors ( (1) instance-level appearance feature & (2) contextual features )..
- step 1) concatenate them
- step 2) pass it to 2 FC layers
- step 3) get actions cores $s_h^a$ & $s_o^a$
(4) Pairwise Stream
To encode spatial relationship between person & object
$\rightarrow$ adpot the 2-channel binary image representation, to characterize the interaction patterns
4. UnionDet
-
previous works : Sequential HOI detectors
-
proposed method : Parallel HOI detectors
5. HOTR
python train.py --gaf_mid_channel 32 --num_graphs 3 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 64 --num_graphs 3 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 128 --num_graphs 3 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 256 --num_graphs 3 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 32 --num_graphs 6 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 64 --num_graphs 6 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 128 --num_graphs 6 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 256 --num_graphs 6 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 32 --num_graphs 9 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 64 --num_graphs 9 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 128 --num_graphs 9 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 256 --num_graphs 9 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 32 --num_graphs 12 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 64 --num_graphs 12 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 128 --num_graphs 12 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12
python train.py --gaf_mid_channel 256 --num_graphs 12 --data 'data/METR-LA' --adjdata 'data/sensor_graph/adj_mx_metr.pkl' --num_nodes 207 --gaf 'data/METR-LA/GAF_metr.txt' --epochs 120 --input_dim 2 --input_length 12 --output_length 12