
( 참고 : “FastCampus, 데이터 엔지니어링 올인원” )
[ Data Engineering ]
Introduction to Data Engineering
목차
- Data Engineering의 필요성
- Data Architecture 구축 시 고려사항
- Data Engineering 개념들
- Data Pipeline이란?
- Data Pipeline 구축 시 고려 사항
- 자동화의 이해
- Ad hoc vs Automated
1. Data Engineering의 필요성
문제 해결을 위한 가설 검증의 단계
- step 1) 문제 정의
- step 2) 데이터 분석 (EDA)
- step 3) 가설 수립
- step 4) 실험 및 테스팅
- step 5) 최적화 ( 데이터 기반 자동화 시스템 )
모든 비즈니스가 동일한 데이터 분석 환경을 가지지는 않는다!
따라서, 기업의 성장 단계에 따라, 집중해야 하는 분석 환경 또한 다르다!
Example
-
Facebook : UX (User eXperience)가 중요한 서비스!
-
유저 정보
-
컨텐츠 정보
-
유저의 액션 정보 ( ex. 어느 화면에 몇 초를 머물렀는지, 좋아요 눌렀는지 등 )
“따라서, 서비스 시작 초기부터 데이터 시스템을 잘 구축해야 한다!”
-
-
Ecommerce : MKT/CRM/물류 데이터가 핵심!
- MKT channel 별 비용 데이터
- CRM 데이터
- 각종 물류 데이터
2. Data Architecture 구축 시 고려 사항시
(1) 데이터 확보
무작정 모든 데이터를 다 관리해서는 안된다. 비즈니스 문제를 같이 파악해야한다!
비용 대비 Business Impact가 가장 높은 데이터를 우선적으로 확보
(2) Data Governance
(1) 원칙 (Principle)
- 데이터 유지.관리를 위한 가이드
- 보안, 품질, 변경 관리
(2) 조직 (Organization)
- 데이터를 관리할 조직의 역할/책임
- 데이터 관리자, 데이타 아키텍트
(3) 프로세스 (Process)
- 데이터 관리를 위한 시스템
- 작업 절차, 모니터링 등
(3) 유연하고 변화 가능한 환경을 구축
- 특정 기술/솔루션에 얽매여선 X
- 생성되는 데이터의 형식에 변화할 수 있는 것처럼, 그에 맞는 tool/solution도 빠르게 변화할 수 있는 솔루션을 구축해야 한다!
(4) Real Time(실시간) 데이터 핸들링이 가능한 시스템
-
하루에 한번이든, 1초에 한번이든…
Data Architecture는 모든 Speed의 데이터를 핸들링해야한다!
-
example
- Real Time Streaming Data Processing
- Cronjob ( 뒤에서 scheduling을 공부할 때 자세히 알아볼 것 )
- Severless Triggered Data Processing
(5) Security
- 내부/외부에서 발생할 수 있는 위험 요소들 파악
- 데이터를 어떻게 안전하게 관리할지, Architecture 안에 포함시켜야!
(6) 셀프 서비스 환경 구축
- Data Engineer 한 명만 엑세스 가능한 데이터 시스템은 확장성 X
- Data Analyists, Scientitsts들도 쉽고 편리하게 사용할 수 있어야!
3. Data Engineering 개념들
(1) API
MKT, CRM, ERP 등, 다양한 platform 및 software들은 API를 통해 데이터를 주고 받을 수 있는 환경을 구축한다!
(2) RDB ( Relational DataBase )
- 데이터 관계도에 기반한 DB로써, 처음에는 저장 목적으로 생겨남
- SQL을 사용하여 자료 열람/유지
- 가장 보편적으로 사용되는 데이터 시스템
(3) NoSQL
- NOT ONLY SQL
- 요즈음 데이터는 다양해짐!
- Unstructured, Schema Less Data를 관리하기 위해
- Scalable HORIZONTALLY
- ex) 메신저에서 많이 사용됨
- Highly Scalable, Less Expensive to maintain
(4) Hadoop/Spark/Presto 등 빅데이터 처리
- Distributed Storage System, Map Reduce를 사용한 병렬 처리
- Spark
- Hadoop의 진화된 버전
- 빅데이터 분석환경에서 Real Time 데이터를 프로세싱하기에 최적화
- Java, Python, Scala를 통한 API를 제공하여 Apps 생성
- SQL Query 또한 OK
(5) Severless Framework
-
서버를 생성하면 유지/관리 비용이 든다. 그런데, 상황에 따라 데이터의 유입/처리 빈도가 다를 수 있음.
따라서, 특정 event에 의해 Trigger되도록!
-
Triggered by requests, DB events, queuing service
-
사용한 만큼만 지불하기
-
3rd Party 앱들 및 다양한 API를 통해 데이터를 수집/정제하는데에 유용!
4. Data Pipeline이란?
Data를 한 장소에서 다른 장소로 옮기는 것
- ex) API에서 DB, DB에서 DB, DB에서 BI Tool…
Data Pipeline이 필요한 경우?
- 다양한 소스로부터 data가 생성/저장되는 서비스
- Data Silo(데이터 사일로) : 각 영역의 데이터가 서로 고립되어 있는 경우
- 실시간/높은 수준의 데이터 분석이 필요한 서비스
- 클라우드 환경으로 데이터 저장
Example
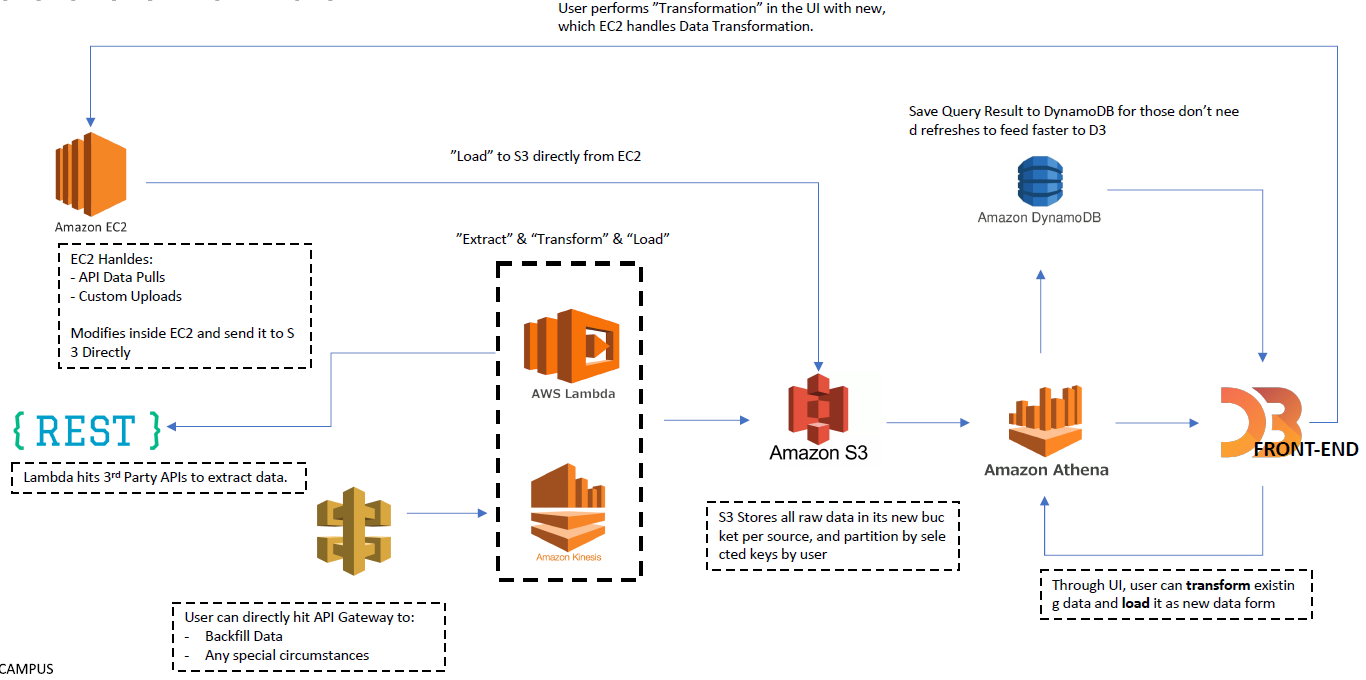
5. Data Pipeline 구축 시 고려 사항
(1) Scalability :
- 데이터가 기하급수적으로 늘어났을때도 잘 작동하는가?
(2) Stability :
- error, data flow 등 다양한 모니터링 관리
(3) Security :
- 데이터 이동 간 보안에 대한 리스크는?
6. 자동화의 이해
Data Processing 자동화 :
- 필요한 data를 “추출,수집,정제”하는 프로세싱을 최소한의 사람 input으로 머신이 운영하는 것을 의미
- ex) Spotify data를 하루에 한번, AIP를 통해서 클라우드 DB로 가져온다고 했을 때, 매번 사람이 데이터 파이프라인을 작동하는 것이 아니라, Crontab등 머신 Scheduling을 통해 자동화
자동화를 위한 고려 사항
- 데이터 프로세싱 step들
- Error handling & Monitoring
- Trigger / Scheduling
Error Handling
import logging
loggig.basicConfig(filename='example.log', level=logging.DEBUG)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too!')
Cloud Logging System
- AWS Cloudwatch
- AWS Data Pipeline Errors
Trigger / Scheduling
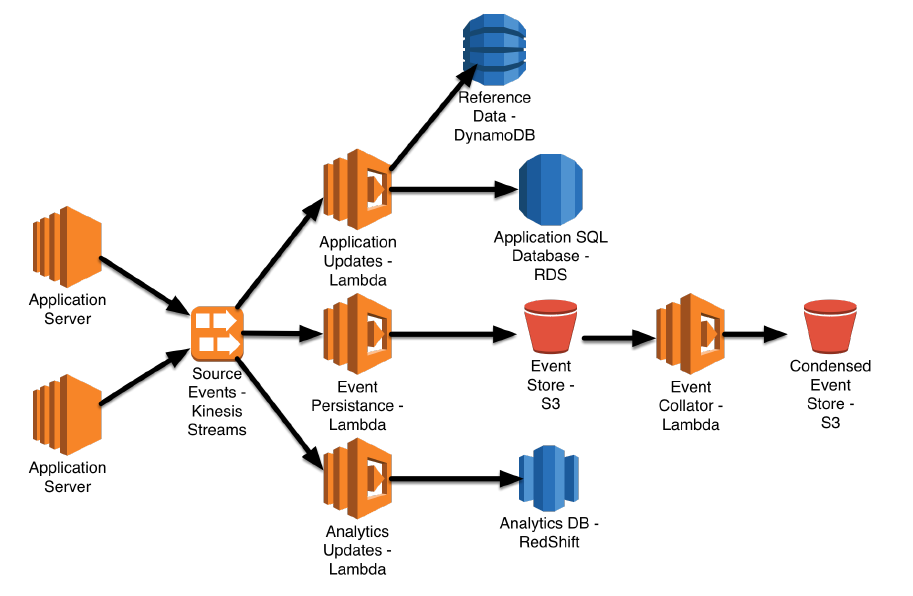
7. Ad hoc vs Automated
Ad hoc : 분석을 하고 싶을 때마다 하는 것! (비정기적)
- Ad hoc 분석 환경 구축은 서비스를 지속적으로 빠르게 변화시키기 위해 필수적인 요소
- Initial data 삽입, 데이터 Backfill 등을 위해 Ad hoc 데이터 프로세싱 시스템 구축 필요
Automated : 자동화 (정기적)
- event, schedule 등 Trigger를 통해 자동화 시스템 구축