( 참고 : “FastCampus, 데이터 엔지니어링 올인원” , https://cskstory.tistory.com/entry/맵리듀스-MapReduce-이해하기 [아는 만큼] )
[ Data Engineering ]
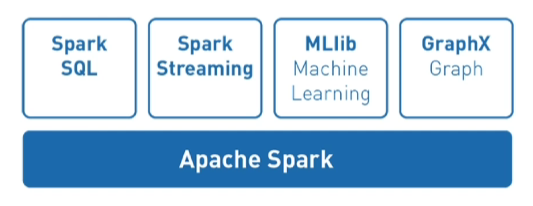
Apache Spark
1. Apache Spark란?
- 빅데이터를 효율적으로 처리하기 위한 시스템
- Python,Java 등 다양한 프로그래밍 언어 API 제공
- ML 관련 다양한 package O
2. Map Reduce (MR)란?
데이터가 방대한 양으로 늘어날 때, 이를 처리해야하는 방식에 문제가 생긴다. (속도/비용 등)
이를 보완하기 위해, 분산 처리 기술 관련 프레임워크인 Map Reduce를 사용한다.
( 핵심 : 데이터를 병렬적으로 분산시켜서 처리 )
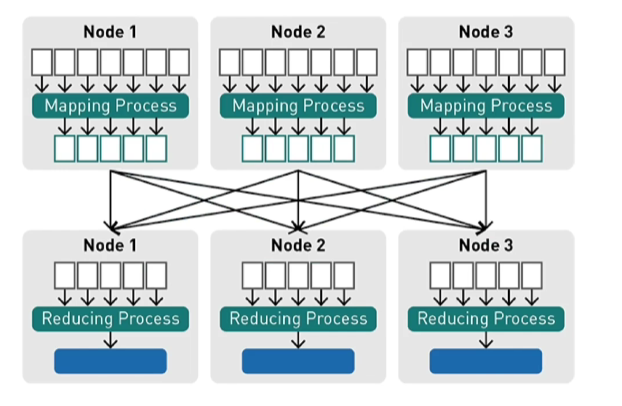
1) Mapping
- Map : 데이터를 담아두는 구조 중 하나로, key & value 쌍을 가짐
- Mapping : 흩어져 있는 데이터를 수직화하여, 그 데이터를 각각의 종류 별로 모으기
2) Reduce
-
위의 Map을 정리해가면서 줄여나가는 과정으로 볼 수 있음
ex) key를 기준으로 count / sum / average …
-
Reduce : Filtering과 Sorting을 통해 데이터 뽑아내기
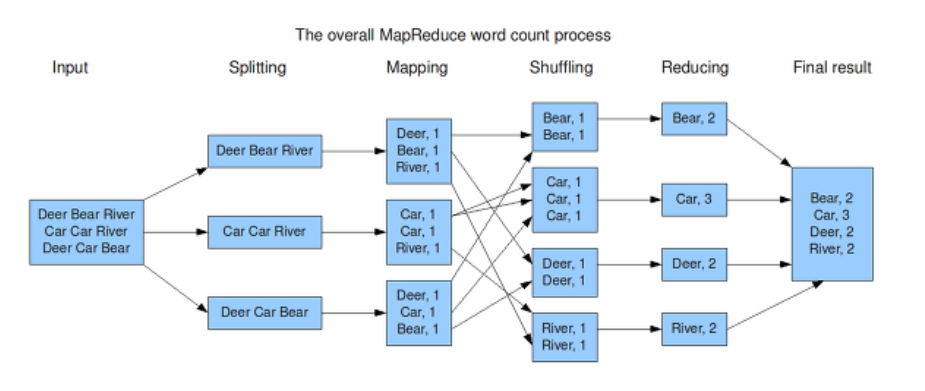
Example ) Word Count
- 특정 글에 나타나는 단어의 개수를 세는 task
- 과정)
- Split) 특정 글 내의 문장을 하나씩 나눠서 읽어가며,
- Map) 해당 문장 내의 각 단어를 일종의 key로, value는 1로 지정하여 나열
- Shuffle) 비슷한 것끼리 모아가면서 정리
- Reduce) 같은 key(=같은 단어)의 경우, value를 서로 더함 ( = word count )
- 출처: https://cskstory.tistory.com/entry/맵리듀스-MapReduce-이해하기 [아는 만큼]
3. Why Map Reduce?
빅데이터는 워낙 방대하기 때문에, 이를 “처리하는 프로세스를 단순화”할 필요가 있다. 그러기 위해서 Map Reduce를 사용한다.
단순한 프로세스?
-
여러 서버를 사용하여 “병렬적”으로 처리
-
key 값(기준 값)이 하나여야 프로세스가 단순
-
key 값을 기준으로, 이들의 value를 연산하는 과정도 단순해야
-
교환법칙 & 결합법칙 성립해야
( $\because$ 임의의 서버에서, 임의의 순서로 두 개의 맵을 선택해서 연산을 수행하더라도 최종 결과는 항상 같아야 병렬 처리 가능 )
-
4. IAM ( Identity and Access Management )
IAM = 리소스에 대한 액세스를 안전하게 제어할 수 있는 서비스.
즉, 서버 사용을 위해, 권한들이 필요한데, 이는 AWS의 “IAM” 를 통해서 관리된다.
( 즉, 누구에 어떠한 권한을 부여할지 총괄하는 역할을 한다 )
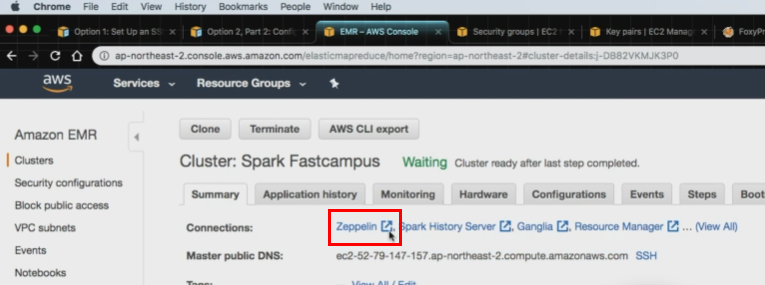
5. AWS의 EMR(Elastic Map Reduce) 통한 Spark 사용
Amazon EMR : AWS에서 Apache Hadoop및 Apache Spark와 같은 빅 데이터 프레임워크 실행을 간소화하는 관리형 클러스터 플랫폼
사용 방법 (Mac/Linux 용)
- AWS의 EMR 클릭
- Create Cluster
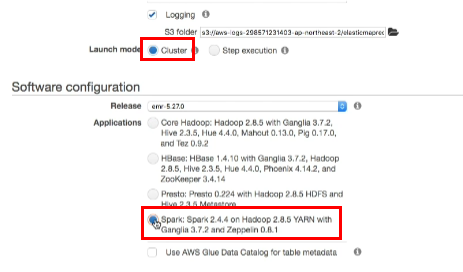
- Launch Mode : Cluster
- Software Configuration : Spark
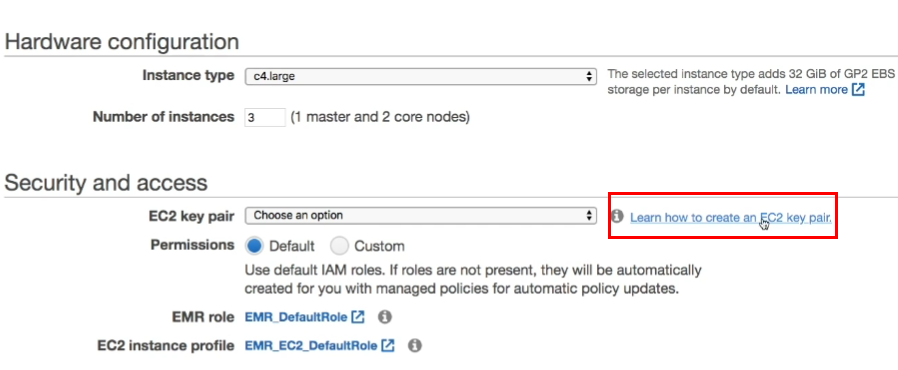
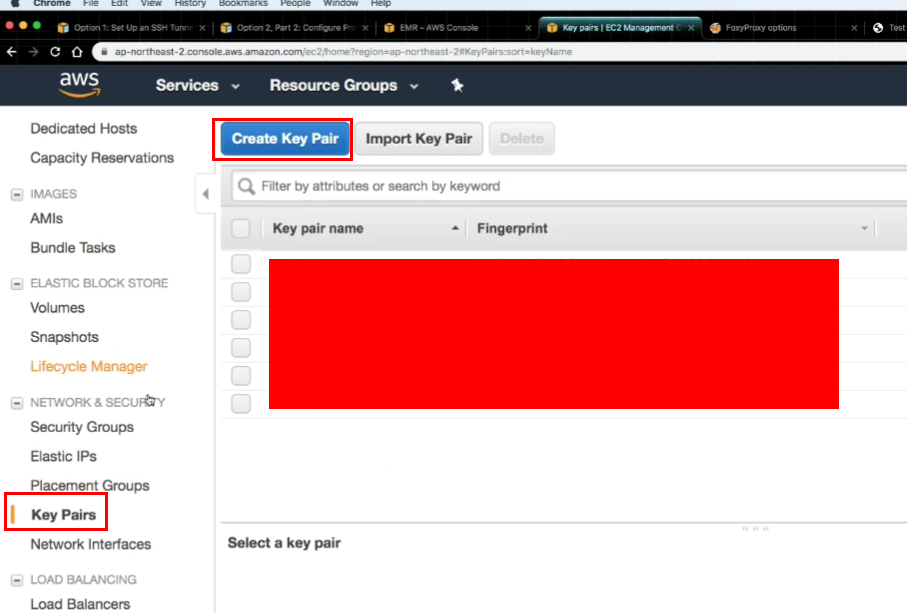
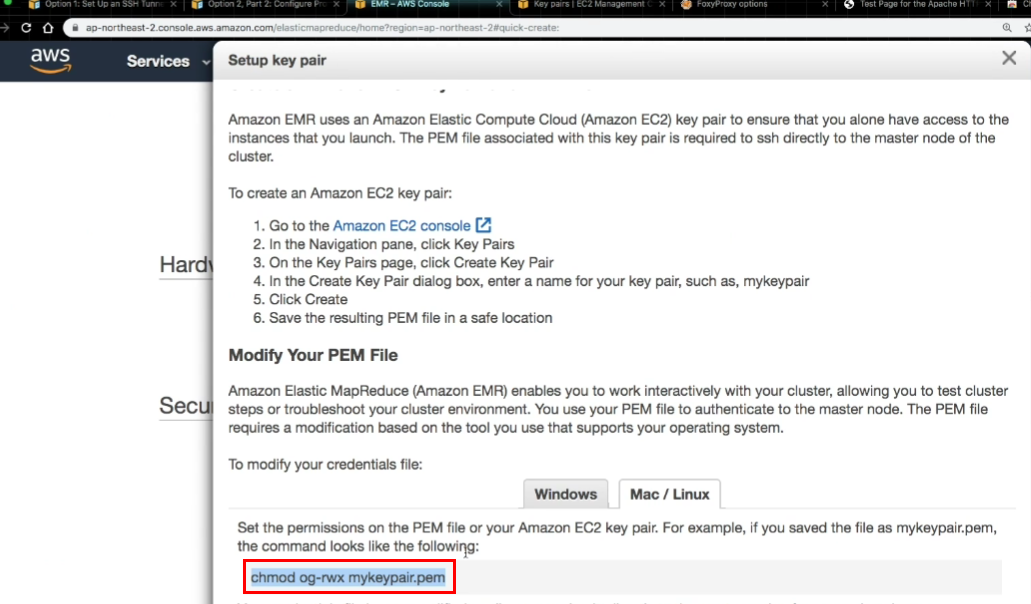
- E2C key pair 생성하기
- 터미널에 아래의 명령어 실행!
- 아래와 같이 Cluster가 생성된 것을 확인할 수 있다.
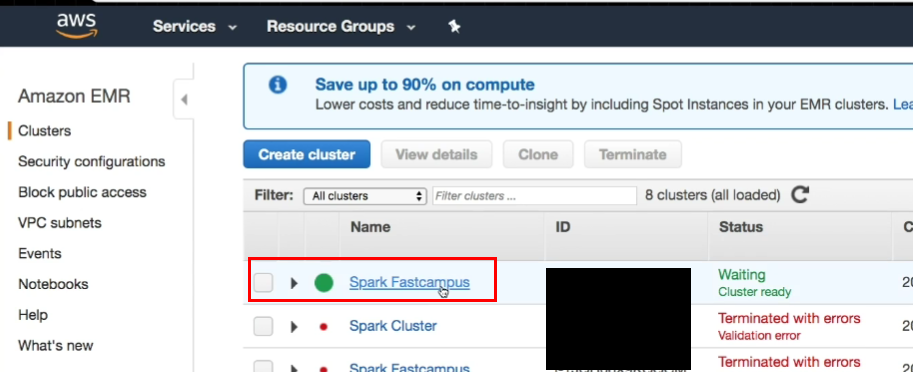
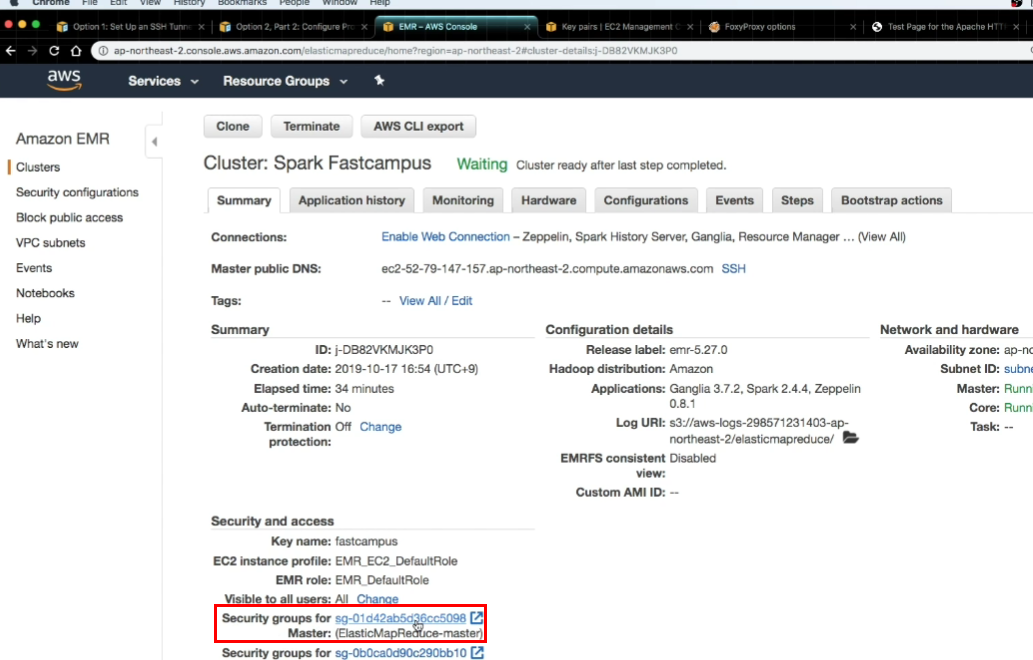
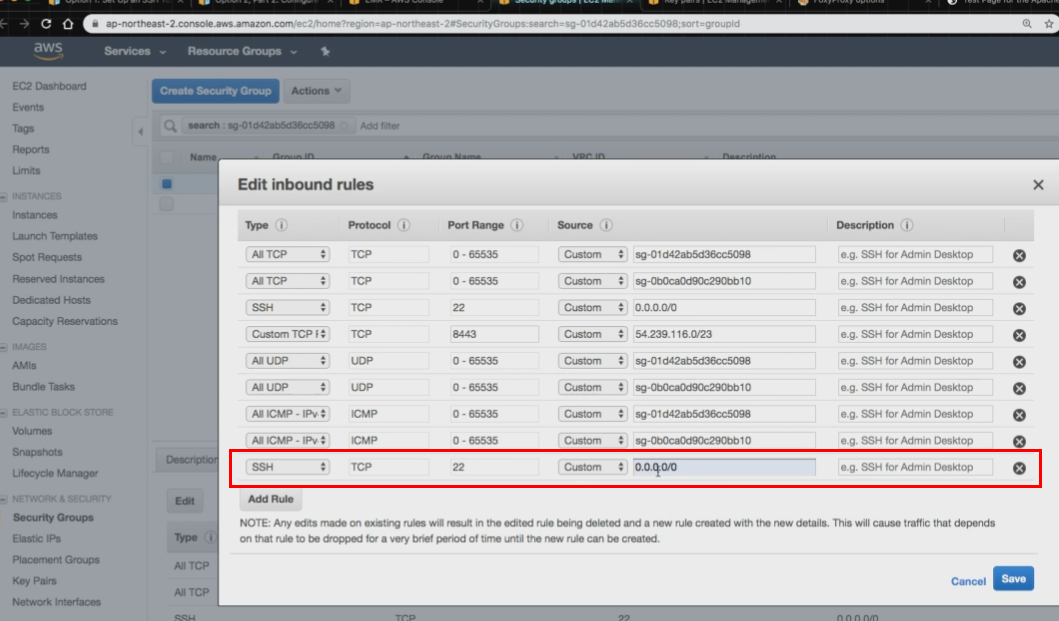
- Security Group에 들어가서, SSH 추가하기
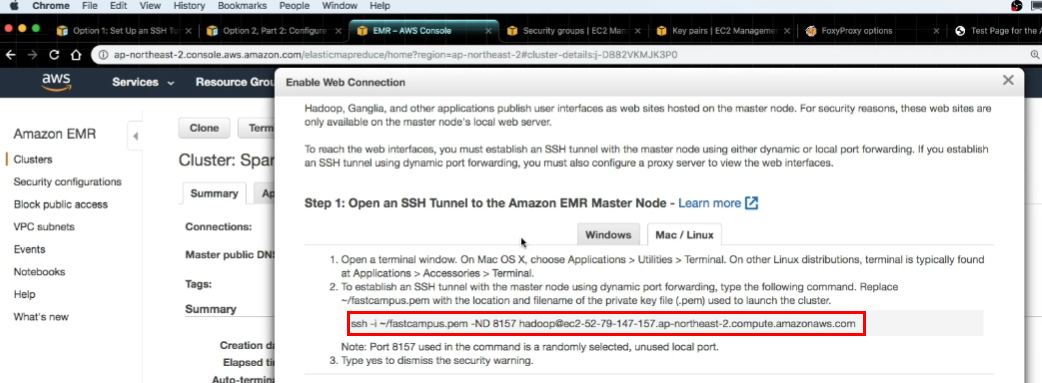
- 터미널에 아래의 명령어 입력
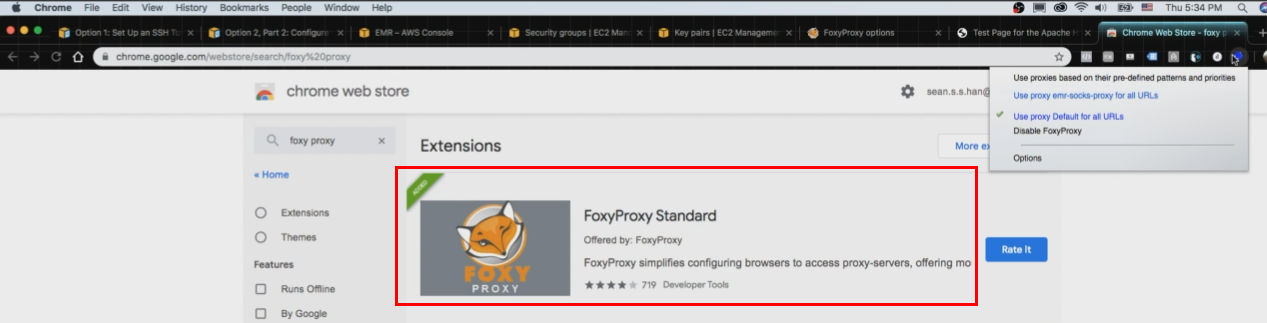
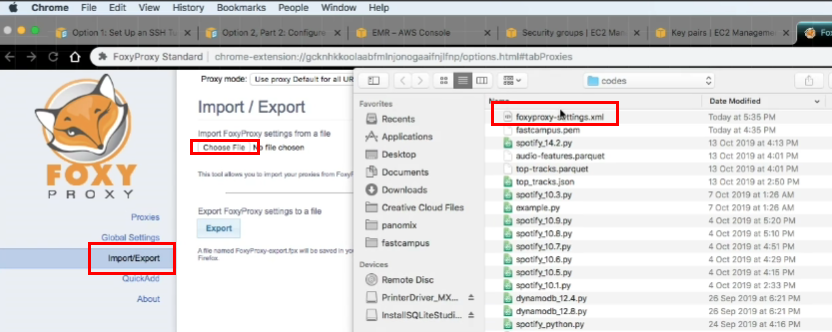
- Foxy Proxy Standard extension 추가
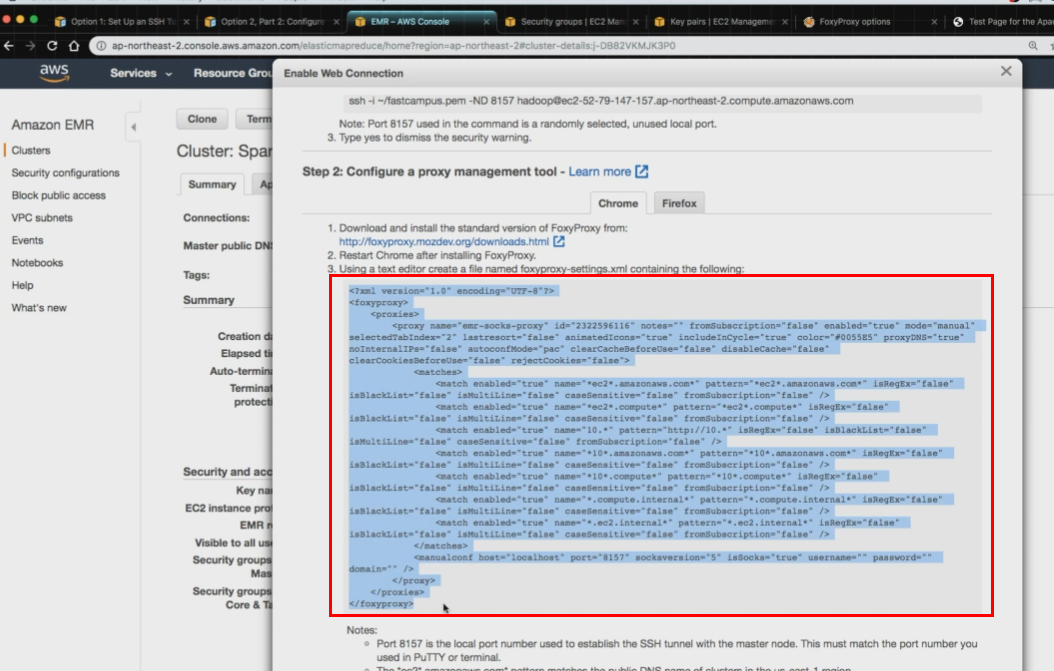
아래의 내용들을 복사한 뒤 xml 파일에 새로 생성
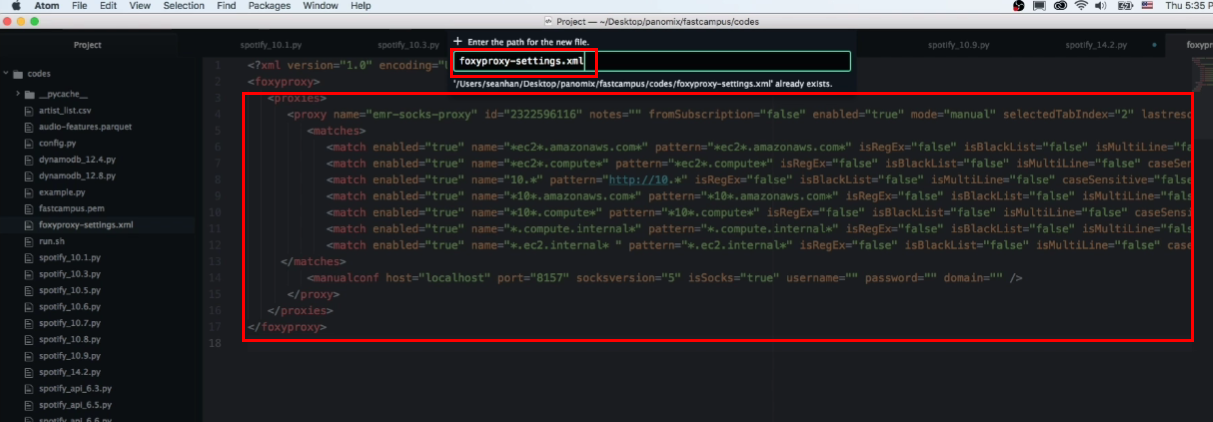
- 파일명 : foxyproxy-settings.xml
- 우측 상단의 여우 모양 & option 클릭
- 위에서 만든 foxyproxy-settings.xml를 import
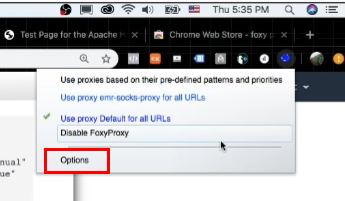
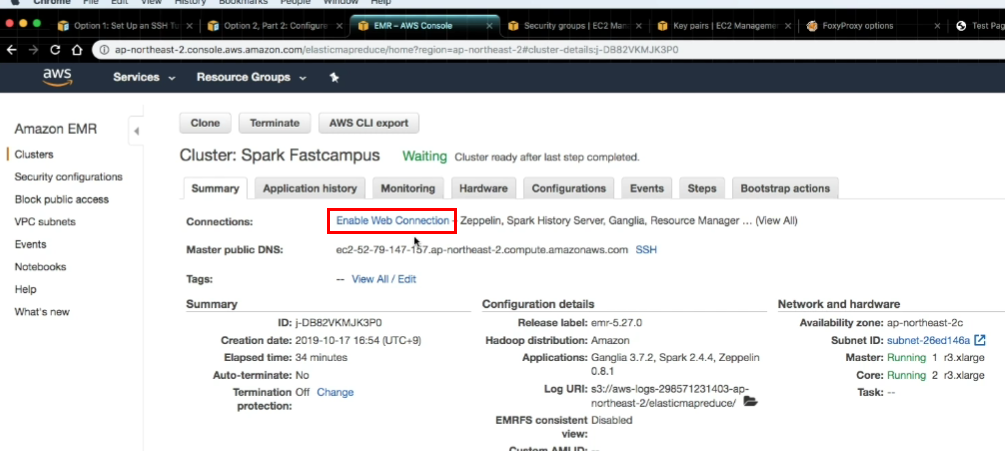
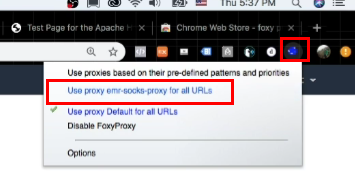
- 우측 상단의 여우 모양 & Use proxy emr-socks-proxy for all URLs 클릭
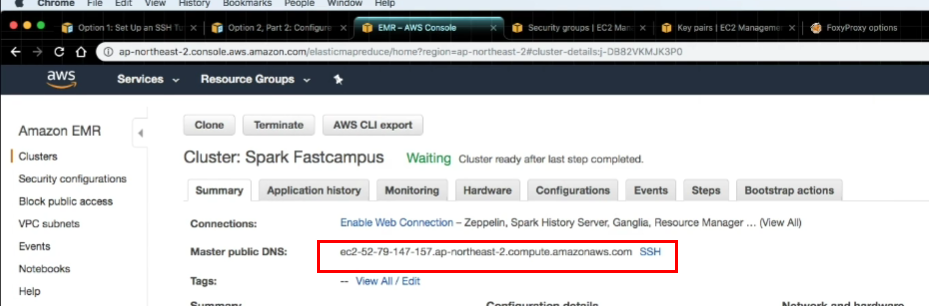
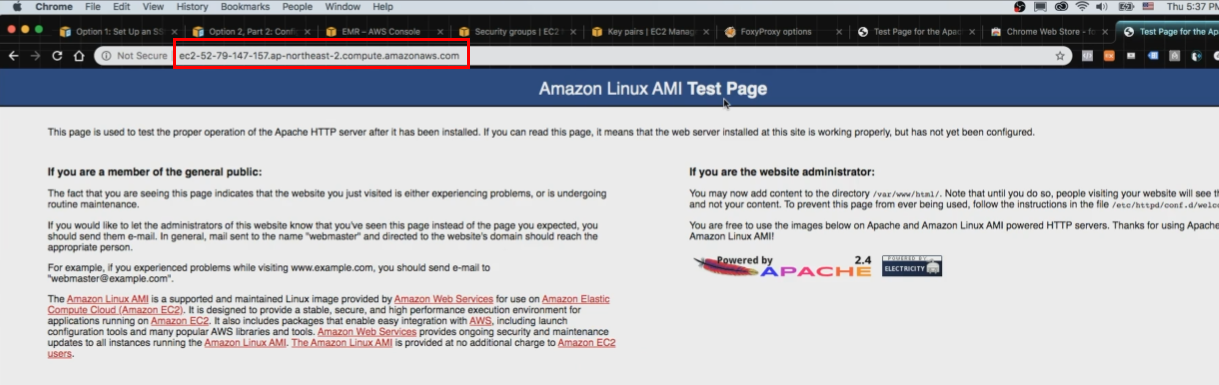
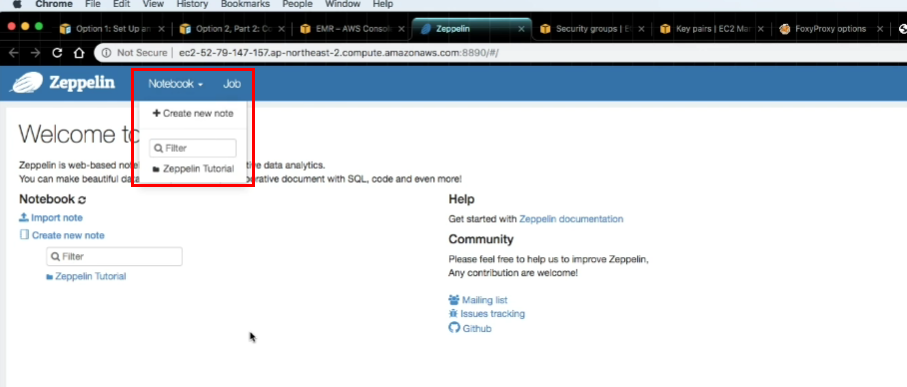
- 완료! Zepplin 사용 가능!
Apache Zeppelin : Spark를 통한 데이터 분석의 불편함을, Web기반의 Notebook을 통해서 사용하기 위한 애플리케이션