
( 참고 : “FastCampus, 데이터 엔지니어링 올인원” )
[ Data Engineering ]
Pyspark (1)
RDD (Resilient Distributed Dataset)
( 참고 : https://bcho.tistory.com/1027 )
-
여러 분산 노드에 걸쳐서 저장되는 변경이 불가능한 데이타(객체)의 집합
-
각각의 RDD는 여러개의 파티션으로 분리됨
-
쉽게 말해서, Spark 내에 저장된 데이타를 RDD라고 하고, 변경이 불가능하다.
( 변경을 하려면 새로운 데이타 셋을 생성해야 한다. )
1. Spark RDD
Zeplin
- spark / hadoop을 사용해서 쉽게 노트북 형식으로 분석을 가능하게 함!
- spark 코드 & python 코드 모두 사용 가능!
아래와 같은 방식으로 Zeplin에서 새로운 notebook을 생성할 수 있다.
기존의 python에서 하던대로라면, 아래와 같이 script를 작성할 수 있다.
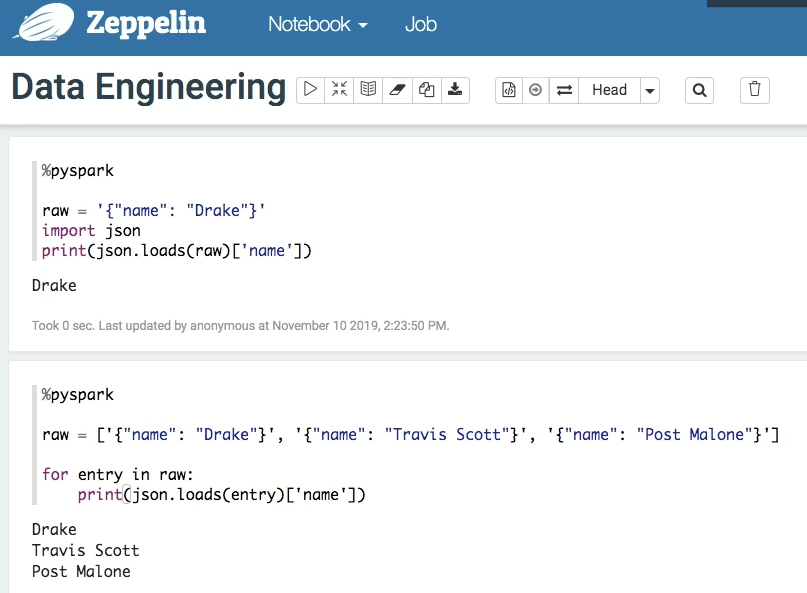
Spark의 RDD는 이와 약간 다르다.
( 데이터가 너무 크기 때문에, 이를 분산시켜서 처리한다 )
- for loop 구조가 아니라, R의 apply와 같이 동시에 병렬적으로 처리한다.

2. Spark Dataframes
이전에 S3에 parquet형식으로 top tracks & audio features 데이터를 저장했었다.
이에 access해서 데이터를 불러올 것이다.
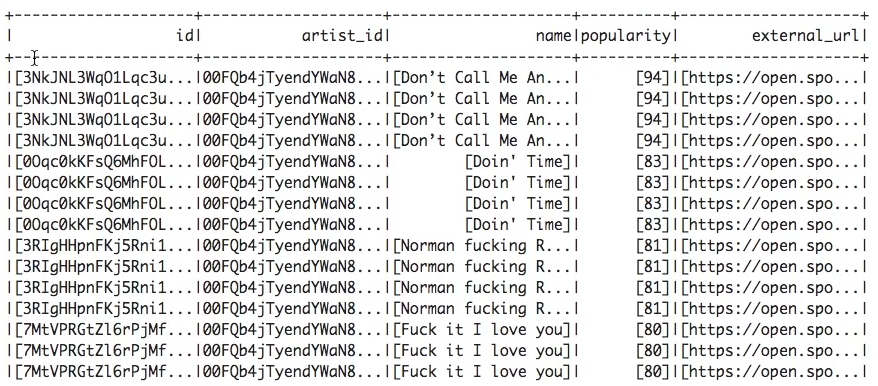
data.printSchema()를 통해, 해당 데이터의 스키마를 아래와 같이 확인할 수 있다.


data.toDF(key값들)를 통해, 해당 데이터를 dataframe 형태로 변환할 수 있다.

3. Select Subset Columns
이번엔 audio features 데이터를 사용해볼 것이다.

다음과 같이 일부의 column만을 선택하여 새로운 df를 생성할 수 있다.

4. Filter Rows
condition 부여를 통해 일부의 row를 추출할 수 있다.

.distinct()를 통해 duplicate rows를 제거할 수 있다.

5. Create UDF
Pyspark의 function을 사용할 수 있다
- danceability의 평균과, acousticness의 최대값 구하기

다음과 같이, 생성된 summary data에 naming을 할 수 있다 ( alias )

이처럼 기본적으로 제공되는 패키지 내의 function들을 사용할 수 있다. 하지만 이 외에도, 우리의 필요에 따라 새로운 함수를 사용할 필요가 있을 때가 있다. ( = User Defined Function, UDF )
udf1: 대문자화 … pyspark의 udf 함수udf2: sign(x>0.06) … python에서의 일반적인 함수 정의


6. JOIN
이전에 top tracks와 audio features를 S3에 parquet형식으로 저장했었다.
이번에는 artists 정보들을 마찬가지 방식으로 S3에 저장할 것이다. 코드는 이전과 비슷하다.
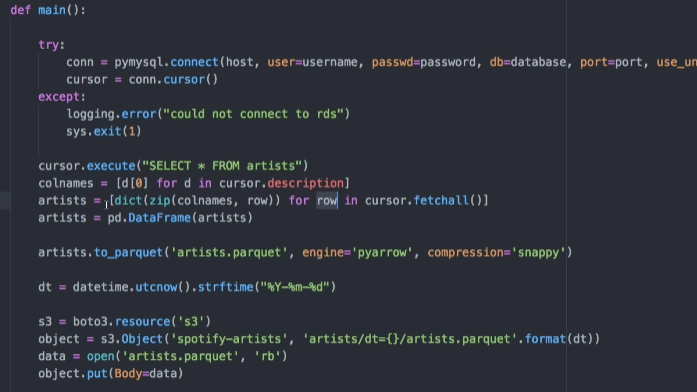
이전과 같이 pymysql을 사용해서 데이터를 가져온뒤, pandas DF으로 변형한 뒤, spark DF 형태로 변형한다.
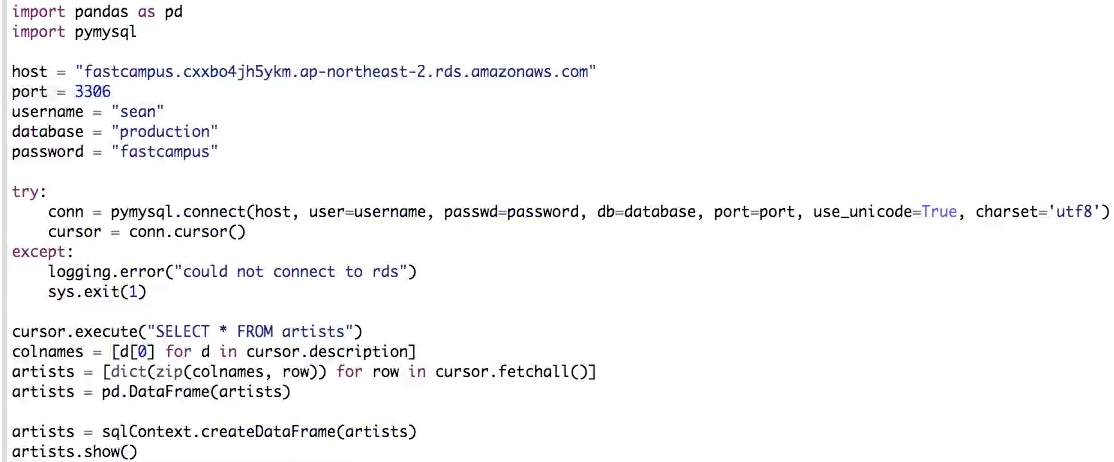
변형된 artists df를, audio features와 join할 것이다. ( default : inner join )

지금까지 2가지 방법에 대해서 살펴 봤다.
- 1) S3에 저장한 데이터를 불러오기
- 2) pymysql을 사용하여 mysql DB에서 데이터 불러오기
7. SQL
위에서 join된 테이블로 temp 테이블 만들기
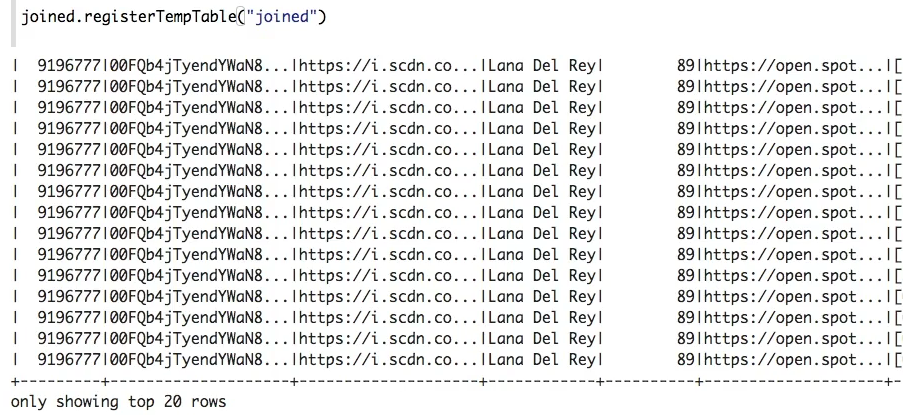
그런 뒤, SQL문을 사용해서 분석 할 수 있다!
