
( 참고 : “FastCampus, 데이터 엔지니어링 올인원” )
[ Data Engineering ]
Spotify Project - Pagination
이번 프로젝트에서는 특정 artists의 album을 가져오는 것을 해볼 것이다.
해당 데이터를 가져오기 위해 필요한 endpoint, method 및 parameter등은 아래와 같다.
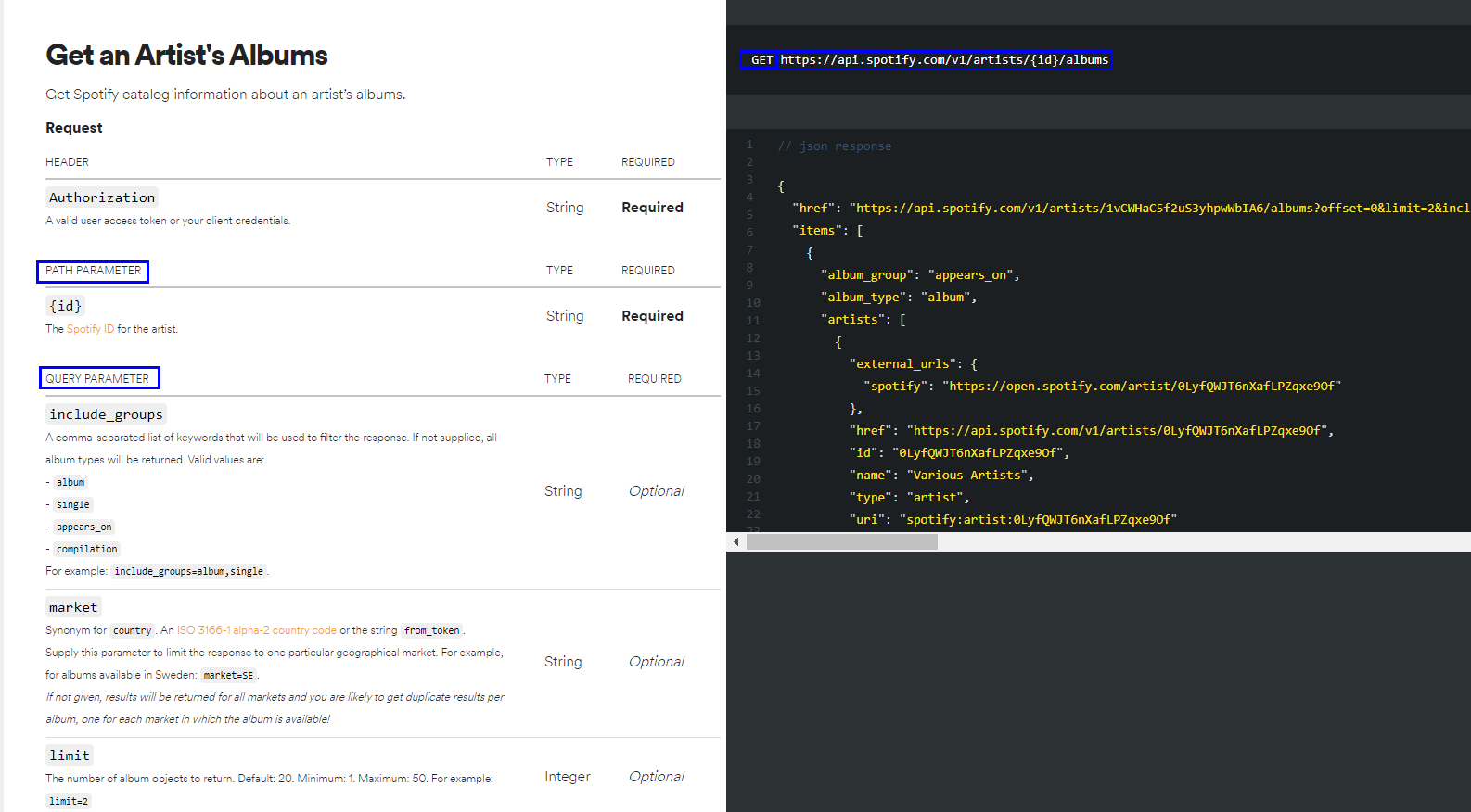
여러 page를 차례로 넘어가며 데이터를 가져올 것이다. ( Pagination )
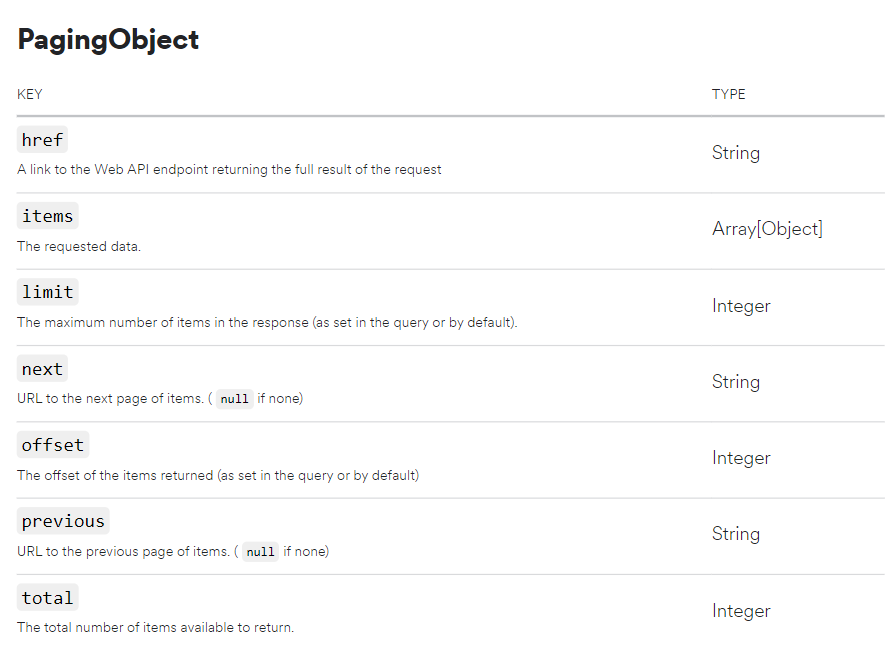
이를 위한 paging object는 아래와 같다.
BTS의 id값 가져오기
headers = get_headers(client_id, client_secret)
params = {
"q": "BTS",
"type": "artist",
"limit": "5"
}
r = requests.get("https://api.spotify.com/v1/search", params=params, headers=headers)
print(r.text)
그 결과, BTS의 id값은 3Nrfpe0tUJi4K4DXYWgMUX임을 파악 가능!
BTS의 Album들 가져오기
r = requests.get( "https://api.spotify.com/v1/artists/3Nrfpe0tUJi4K4DXYWgMUX/albums", headers = headers)
raw = json.loads(r.text)
total = raw['total'] # 70
offset = raw['offset'] # 0
limit = raw['limit'] # 20
next_ = raw['next'] # 다음 url
- BTS의 모든 앨범 가져오기
while next_:
albums = []
albums.extend(raw['items']) # (1) 앨범 +20
while next_:
r = requests.get(raw['next'], headers=headers)
raw = json.loads(r.text)
next_ = raw['next'] # 다음 url
albums.extend(raw['items']) # (2) 앨범 +20 , (3) 앨범 +20, (4) 앨범 +10
- 100개의 앨범만 가져오기
while count < 100 or not next_:
albums = []
albums.extend(raw['items']) # (1) 앨범 +20
count =0
while count < 100 or not next_:
r = requests.get(raw['next'], headers=headers)
raw = json.loads(r.text)
next_ = raw['next'] # 다음 url
albums.extend(raw['items']) # (2) 앨범 +20 , (3) 앨범 +20, (4) 앨범 +10
count = len(albums)