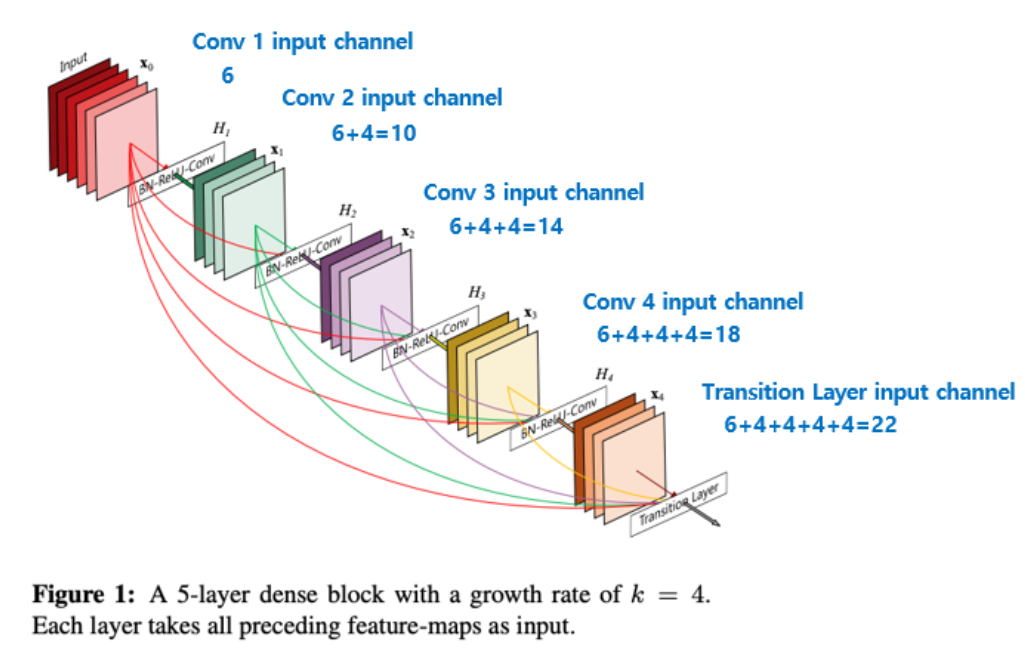
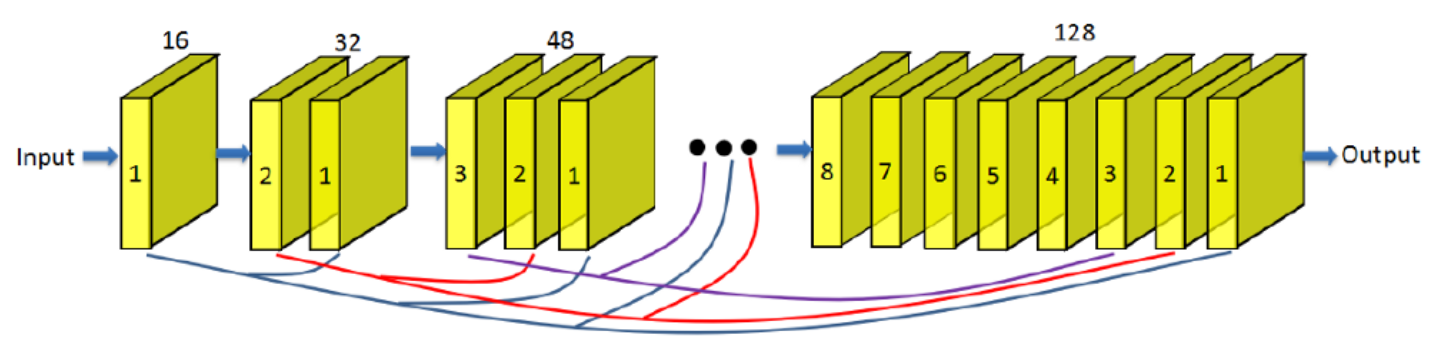
class DenseUnit(tf.keras.Model):
def __init__(self, filter_out, kernel_size):
super(DenseUnit, self).__init__()
self.bn = tf.keras.layers.BatchNormalization() # 1) Batch Norm Layer
self.conv = tf.keras.layers.Conv2D(filter_out, kernel_size, padding='same') # 2) Convolutional Layer
self.concat = tf.keras.layers.Concatenate() # 3) Concatenate
def call(self, x, training=False, mask=None): # x: (Batch, H, W, Ch_in)
# 여기서도 ResNet처럼 "pre-activation" 구조 ( BN - ReLU - Conv 순 )
h = self.bn(x, training=training)
h = tf.nn.relu(h)
h = self.conv(h) # h: (Batch, H, W, filter_output)
return self.concat([x, h]) # (Batch, H, W, (Ch_in + filter_output))
class DenseLayer(tf.keras.Model):
def __init__(self, num_unit, growth_rate, kernel_size):
super(DenseLayer, self).__init__()
self.sequence = list()
for idx in range(num_unit):
self.sequence.append(DenseUnit(growth_rate, kernel_size))
def call(self, x, training=False, mask=None):
for unit in self.sequence:
x = unit(x, training=training)
return x
class TransitionLayer(tf.keras.Model):
def __init__(self, filters, kernel_size):
super(TransitionLayer, self).__init__()
self.conv = tf.keras.layers.Conv2D(filters, kernel_size, padding='same')
self.pool = tf.keras.layers.MaxPool2D()
def call(self, x, training=False, mask=None):
x = self.conv(x)
return self.pool(x)
class DenseNet(tf.keras.Model):
def __init__(self):
super(DenseNet, self).__init__() # ex. 28*28*n의 input
self.conv1 = tf.keras.layers.Conv2D(8, (3, 3), padding='same', activation='relu') # 28x28x8
self.dl1 = DenseLayer(2, 4, (3, 3)) # 28x28x16 ( = 8개 filter +(2개 unit *4의 growth rate) )
self.tr1 = TransitionLayer(16, (3, 3)) # 14x14x16 ( max pooling )
self.dl2 = DenseLayer(2, 8, (3, 3)) # 14x14x32 ( = 16개 filter + (2개 unit*8의 growth rate) )
self.tr2 = TransitionLayer(32, (3, 3)) # 7x7x32 ( max pooling )
self.dl3 = DenseLayer(2, 16, (3, 3)) # 7x7x64 ( = 32개 filter + (2개 unit*16의 growth rate))
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(128, activation='relu')
self.dense2 = tf.keras.layers.Dense(10, activation='softmax')
def call(self, x, training=False, mask=None):
x = self.conv1(x)
x = self.dl1(x, training=training)
x = self.tr1(x)
x = self.dl2(x, training=training)
x = self.tr2(x)
x = self.dl3(x, training=training)
x = self.flatten(x)
x = self.dense1(x)
return self.dense2(x)
# Implement training loop
@tf.function
def train_step(model, images, labels, loss_object, optimizer, train_loss, train_accuracy):
with tf.GradientTape() as tape: # 자동 미분 & 연산 기록해줌
predictions = model(images, training=True) # (1) prediction result
loss = loss_object(labels, predictions) # (2) calculate loss
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, predictions)
# Implement algorithm test
@tf.function
def test_step(model, images, labels, loss_object, test_loss, test_accuracy):
predictions = model(images, training=False)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train[..., tf.newaxis].astype(np.float32)
x_test = x_test[..., tf.newaxis].astype(np.float32)
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
for epoch in range(EPOCHS):
for images, labels in train_ds:
train_step(model, images, labels, loss_object, optimizer, train_loss, train_accuracy)
for test_images, test_labels in test_ds:
test_step(model, test_images, test_labels, loss_object, test_loss, test_accuracy)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print(template.format(epoch + 1,
train_loss.result(),
train_accuracy.result() * 100,
test_loss.result(),
test_accuracy.result() * 100))
train_loss.reset_states()
train_accuracy.reset_states()
test_loss.reset_states()
test_accuracy.reset_states()
Epoch 1, Loss: 0.11222333461046219, Accuracy: 96.69999694824219, Test Loss: 0.051826879382133484, Test Accuracy: 98.29999542236328
Epoch 2, Loss: 0.08431833237409592, Accuracy: 97.55833435058594, Test Loss: 0.052275653928518295, Test Accuracy: 98.3699951171875
Epoch 3, Loss: 0.07055088877677917, Accuracy: 97.97944641113281, Test Loss: 0.059118326753377914, Test Accuracy: 98.28666687011719
Epoch 4, Loss: 0.06249263882637024, Accuracy: 98.22666931152344, Test Loss: 0.06738369911909103, Test Accuracy: 98.18999481201172
Epoch 5, Loss: 0.0574798583984375, Accuracy: 98.3846664428711, Test Loss: 0.06918792426586151, Test Accuracy: 98.2280044555664
Epoch 6, Loss: 0.05322617292404175, Accuracy: 98.51972198486328, Test Loss: 0.06587052345275879, Test Accuracy: 98.32833099365234
Epoch 7, Loss: 0.049832653254270554, Accuracy: 98.62833404541016, Test Loss: 0.06826455891132355, Test Accuracy: 98.36714172363281
Epoch 8, Loss: 0.04693884775042534, Accuracy: 98.71583557128906, Test Loss: 0.06756298989057541, Test Accuracy: 98.42124938964844
Epoch 9, Loss: 0.04515141248703003, Accuracy: 98.77925872802734, Test Loss: 0.07314397394657135, Test Accuracy: 98.36333465576172
Epoch 10, Loss: 0.04279949143528938, Accuracy: 98.84683227539062, Test Loss: 0.07374981045722961, Test Accuracy: 98.39399719238281