
( 참고 : Fastcampus 강의 )
[ Deconvolutional Network (2010) ]
1. FCN의 문제점
사전에 정해놓은 receptive field를 사용하기 때문에, 너무 작은 물체는 인식되지 않을 수 있고, 너무 큰 물체는 여러 개의 작은 물체로 인식될 수도 있다.
즉, 여러 번의 “convolutional layer + pooling” 과정을 통해 해상도가 줄어들고, 이를 다시 upsampling하는 방식을 사용함으로 인해, detail이 사라질 수 있다.

2. Architecture of Conv & Deconv Network
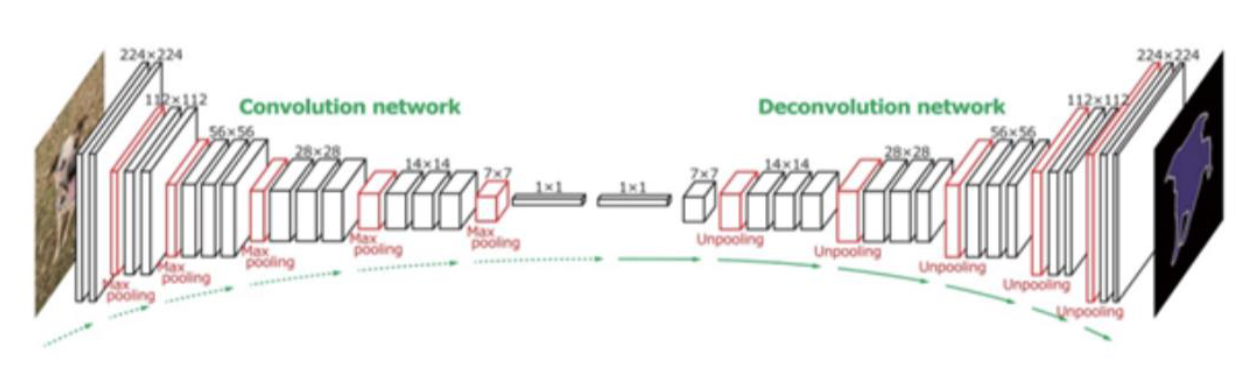
-
대칭적 구조 ( VGG-16를 2개 붙인 구조 )
-
Max pooling 시, 최대값의 위치를 저장한다 (switch variable)
( ZF Net에서 살펴본 적이 있다 )
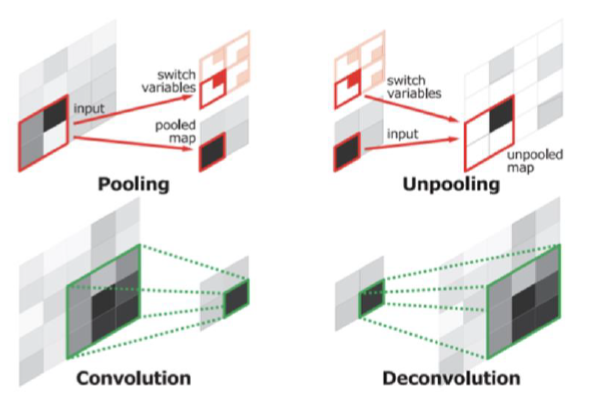
3. Switch Variable
Max pooling시,
- (1) 최대값 뿐만 아니라
- (2) 최대값의 위치 또한 사용한다.
여기서 (2)를 저장하는 variable이 switch variable이다.
4. FCN vs Conv&Deconv
FCN보다 더 세부적으로 segmentation이 잘 이루어진 것을 확인할 수 있다.

5. Other Techniques
VGG 두개를 붙이면…too heavy한 모델! overfitting 염려
이를 해결하기 위한 테크닉으로…
- (1) Batch Normalization
- (2) Data Augmentation
- Pascal VOC 데이터를 300만장으로!
- (3) 2-stage training
- ( Pre-train ) 쉬운 image : centered, small object size variance (20만 장)
- ( Fine-tuning ) 어려운 image : various position, size variance (270만 장)
6. Results
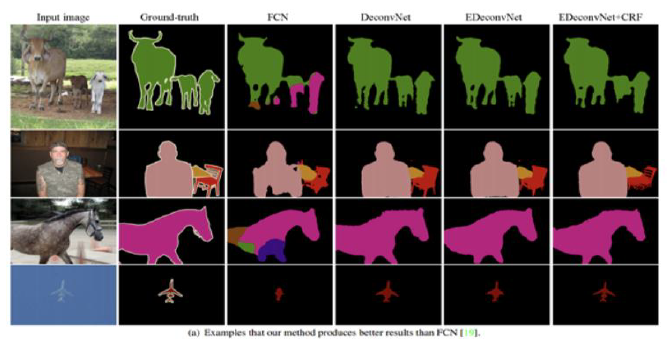
( EDeconvNet : FCN과 DeconvNet을 앙상블한 모델 )