( 참고 : Fastcampus 강의 )
[ Deep Lab v3 + (2017) ]
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
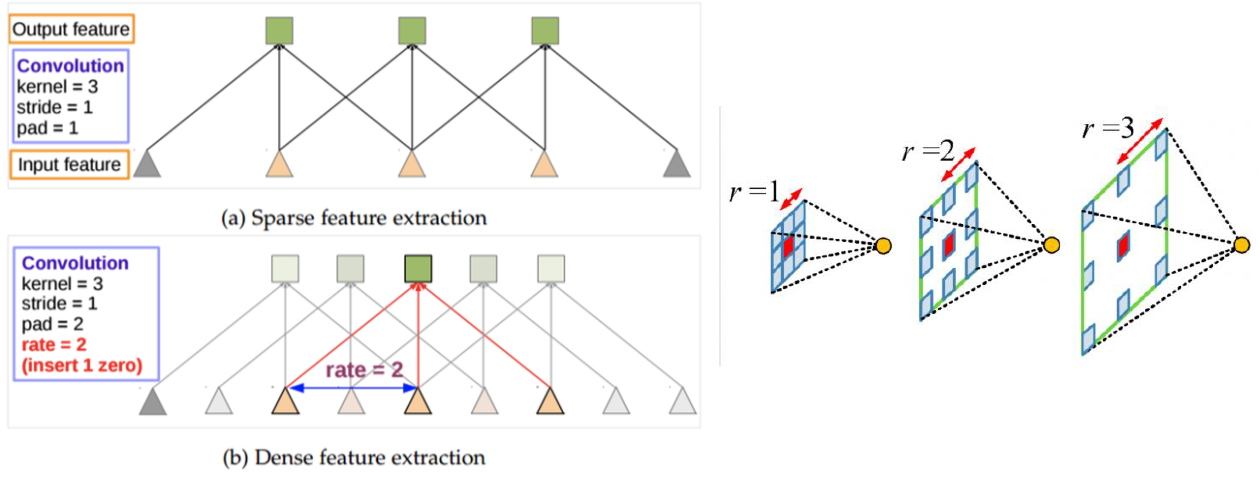
1. Atrous Convolution
-
wavelet 신호 분석에서 주로 사용된다
-
expanding receptive field!
( cnn filter로써 캐치할 수 있는 영역이 넓어진다 )
-
rate 조절을 통해 건너띄는 정도 조절
( 보다 넓게 보기 위해 )
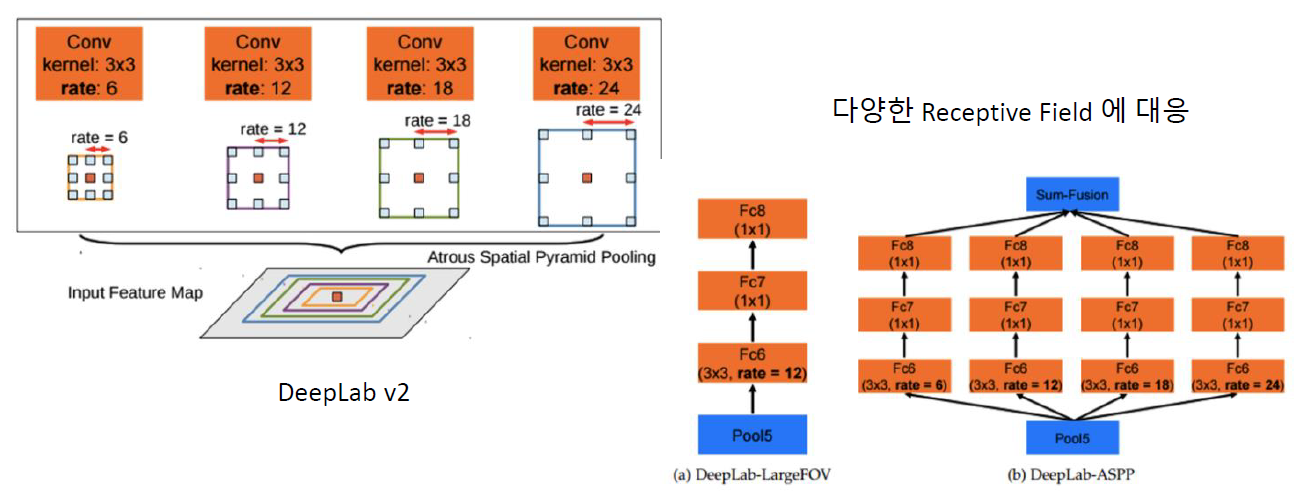
2. Atrous Spatial Pyramid Pooling
Deep Lab v2
Receptive Field의 rate를 다양하게 설정하여 합치기! ( rate = 6,12,18,24 )
- 병렬적으로 합치기
- DeepLab v2부터 사용
Deep Lab v3 +
Encoder-Decoder 방식과 결합해서 사용하면, 보다 나은 성능을 보임을 확인
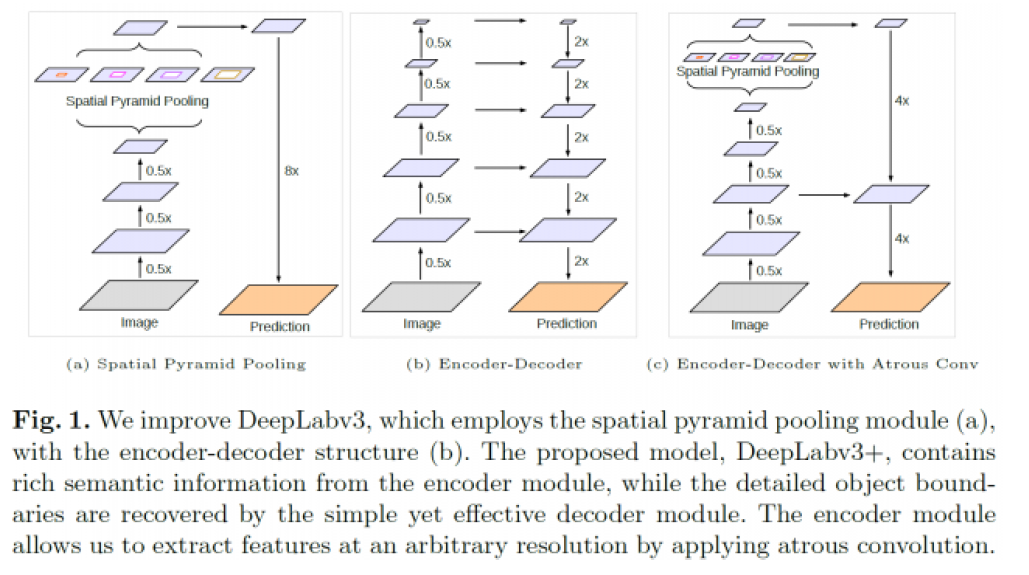
[ Encoder 구조 ]
-
Deep Lab v3와 동일
- astrous convolution을 통해 “보다 넓게 본다”
- up sampling 직전에, 1x1 conv 통한 dimension reduction
[ Decoder 구조 ]
-
low level feature를 1x1 conv를 사용하여 뽑아냄
-
Encoder를 통해 encoding된 정보를 concatenate
( U-net의 구조와 유사 )
-
Upsampling하여 최종 prediction
3. Changed Xception Backbone
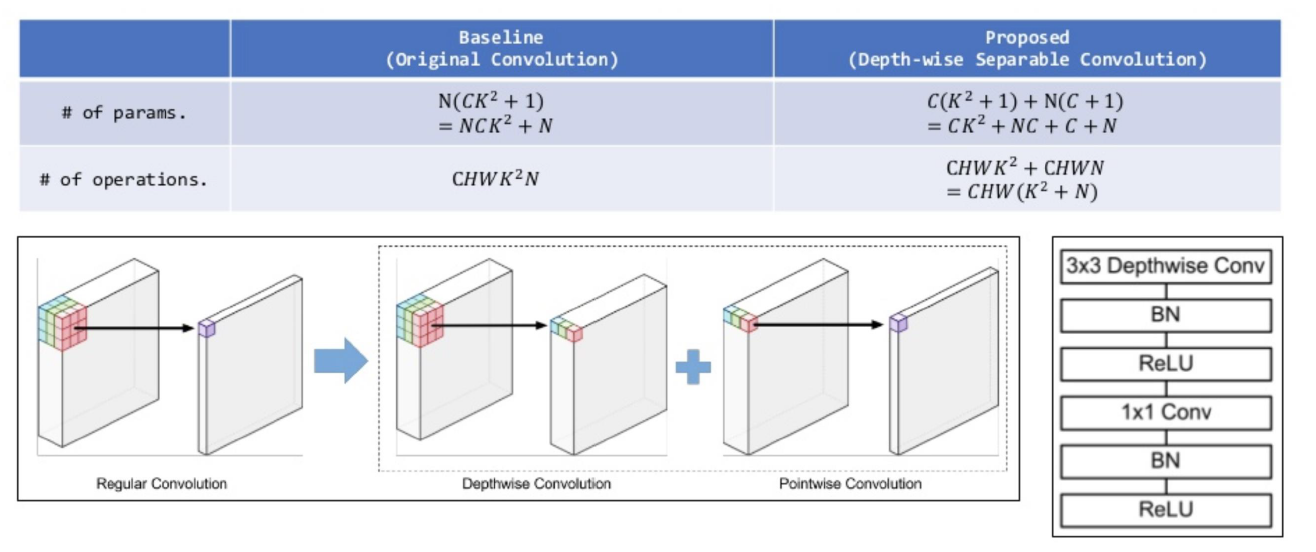
Astrous Separable Convolution을 적용하기 위해, pooling을 depth-wise separable convolution으로 대체함
depth-wise separable convolution
- 경량화를 위해, MobileNet에서 사용하던 convolution
- Deep Lab v3에서는, depth-wise convolution이후, point wise convolution하기 이전에, (1) batch normalization과 (2) ReLU를 추가함