
( 참고 : Fastcampus 강의 )
[ FCN (Fully Convolution Network for Semantic Segmentation) ]
1. Introduction
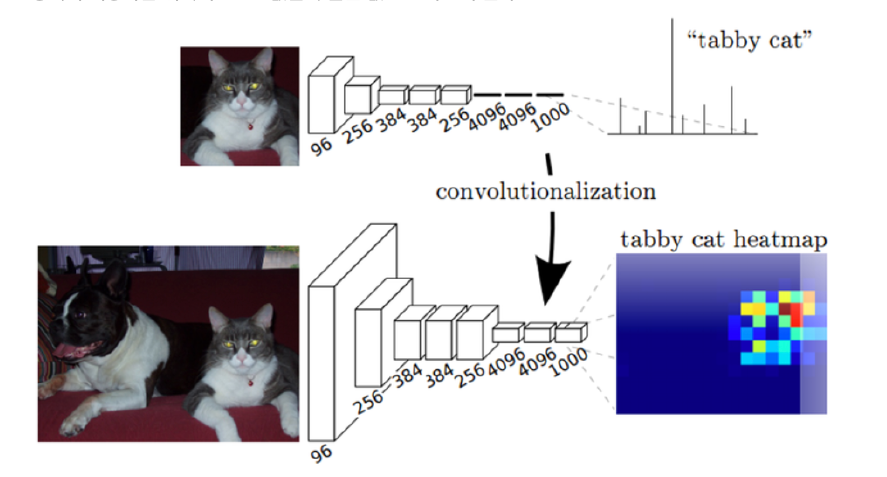
Classification 모델들의 성능은 점차 높아지는데… 이를 사용하여 Segmentation을 할 수 없을까?
생각해보면, Classification을 위한 CNN 모델에서, 중간 중간의 layer에도 분명 물체의 위치와 관련된 정보가 담겨있다. 하지만, 마지막 Fully Connected Layer를 통과하면서 해당 정보는 사라지게 된다.
\(\rightarrow\) FCNN을 \(1\times 1\) convolution으로 대체하자!
실제로 1x1 conv로 대체한 결과, 히트맵을 통해 위치에 대한 정보가 보존됨을 확인하였다.
2. Up & Down sampling
들어온 input 이미지는, 차례로
- 1) down sampling
- 2) up sampling
과정을 거치게 된다.
(1) Down sampling
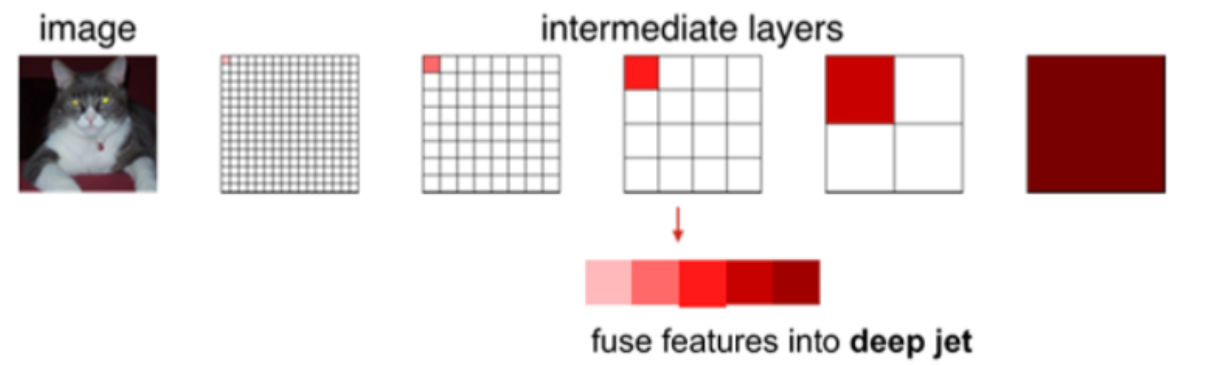
Down sampling은 일종의 정보를 압축하는 encoder로써 볼 수 있다.
SSD 모델에서 중간 중간의 feature map들을 concatenate했던 원리와 마찬가지로, 여기서도 이와 유사한 Deep Jet이란 방법을 사용한다.
각 layer의 feature들의 해상도가 다르기 때문에, 이렇게 중간 중간에 나오게 된 feature들을 마지막 layer에 concatenate해준다.
(2) Up sampling
\(1\times 1\) convolution을 사용한 뒤, 줄어든 dimension을 다시 늘리기 위해 up sampling을 해줘야 한다.
이는 일종의 Decoder로써의 역할을 한다고 볼 수 있다.
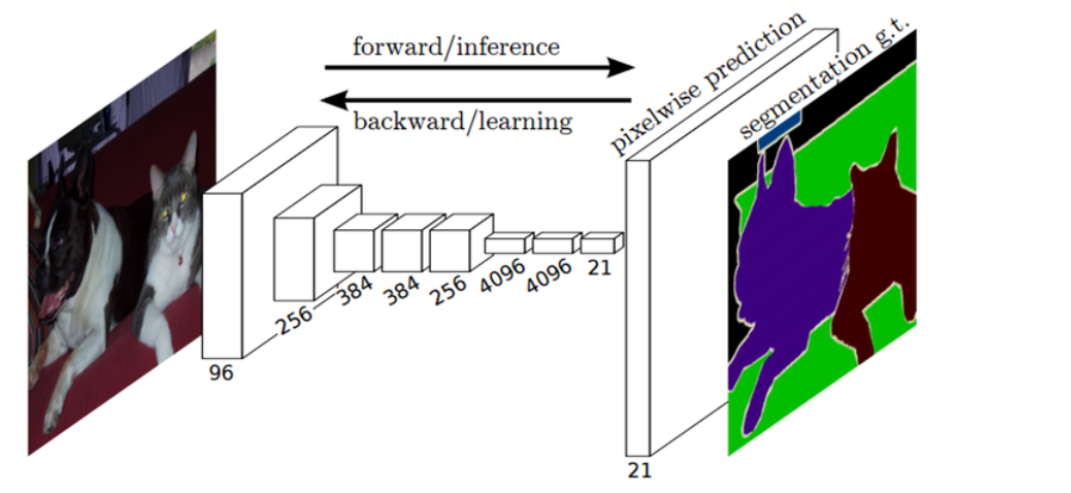
Up sampling에는 아래와 같은 두 가지 방법이 있다.
- 방법 1) Bilinear interpolation
- 해상도를 높이기 위해, 중간 값들을 보간
- 주로 2차원일 때 사용
- 방법 2) Deconvolution
- ZFNet에서 사용했던 deconvolution
- 장점) 필터 계수를 학습할 수 있다.
3. Skip Connection
중간에 해상도가 낮아지는 문제를 해결하기 위해, 아래와 같이 skip connection을 사용한다. ( Deconvolution 할 때, 앞서 convolution 할 때의 정보를 받을 수 있음 )
아래 그림을 통해, Skip connection이 늘어날 수록, segmentation이 더 세밀해짐을 알 수 있다.
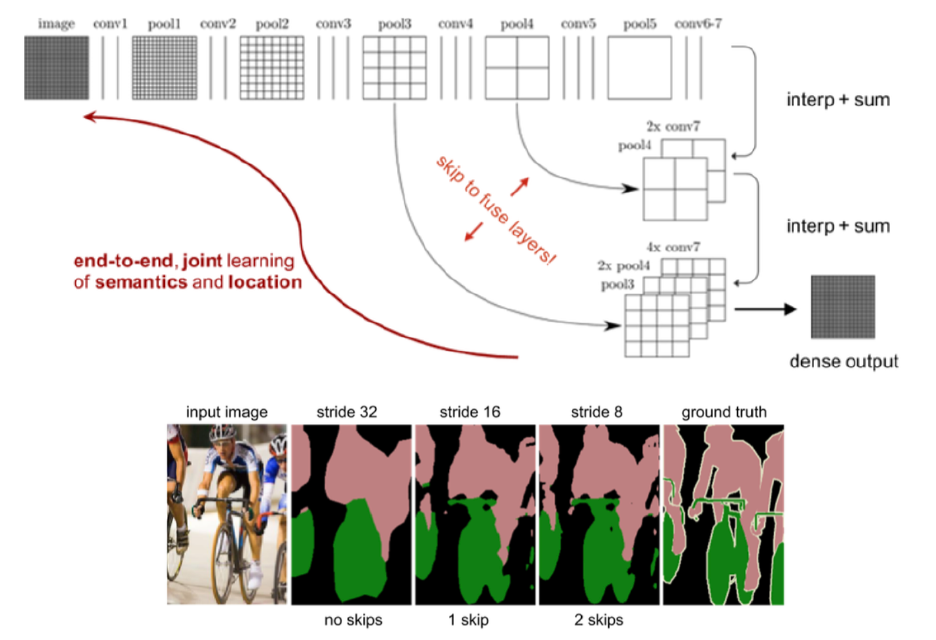
아래 그림은, skip connection이 이루어지는 것을 시각화한 것이다.
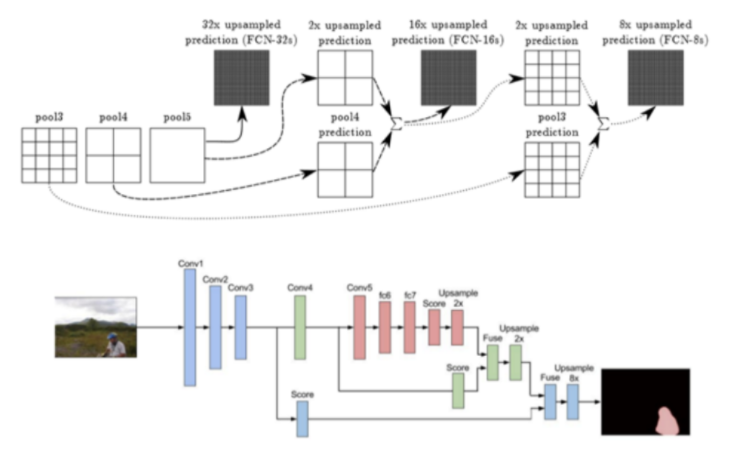
FCN-32s : pool5에서 (skip connection 없이) 바로 32배
FCN-16s : ( (a) + (b) )를 16배
- (a) pool5를 2배 upsampling
- (b) pool4
FCN-8s : ( (c) + (d) )를 8배
- (c) ( (a) + (b) )를 2배 upsampling
- (d) pool3