
( 참고 : Fastcampus 강의 )
[ Fast,Faster R-CNN ]
1. R-CNN의 문제점
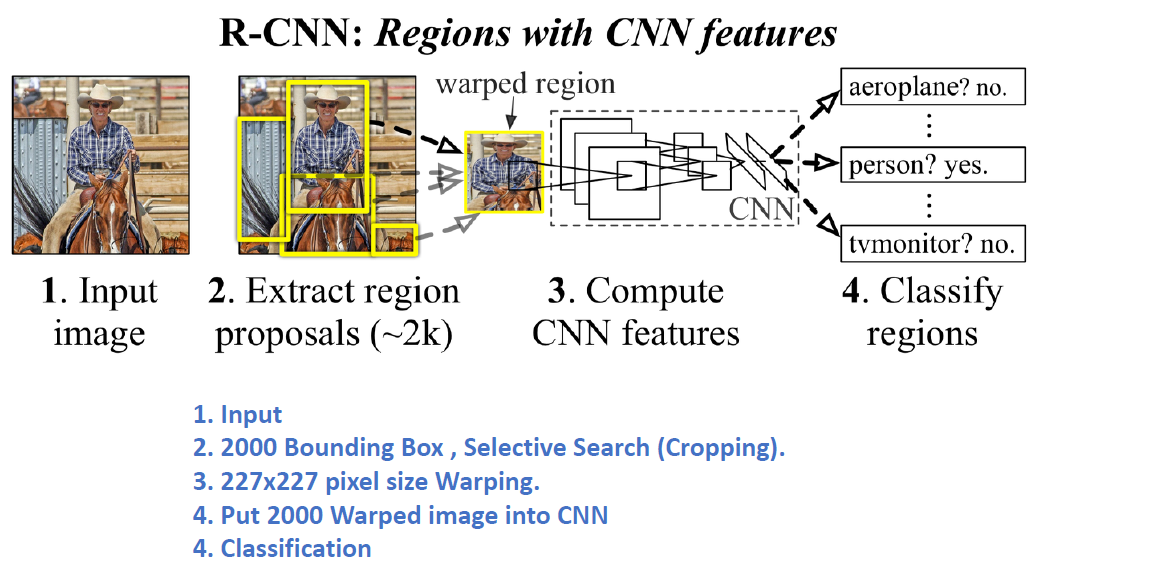
Selective Search를 통해 2000개의 Bounding Box 생성
\(\rightarrow\) 너무 많은 시간 소요! & 복잡하다
2. Fast R-CNN (2015)
(기존) Feature Extractor & Classifier & Regressor를 모두 따로 진행
(제안) 이 셋을 하나로 합침 (Unified Framework)
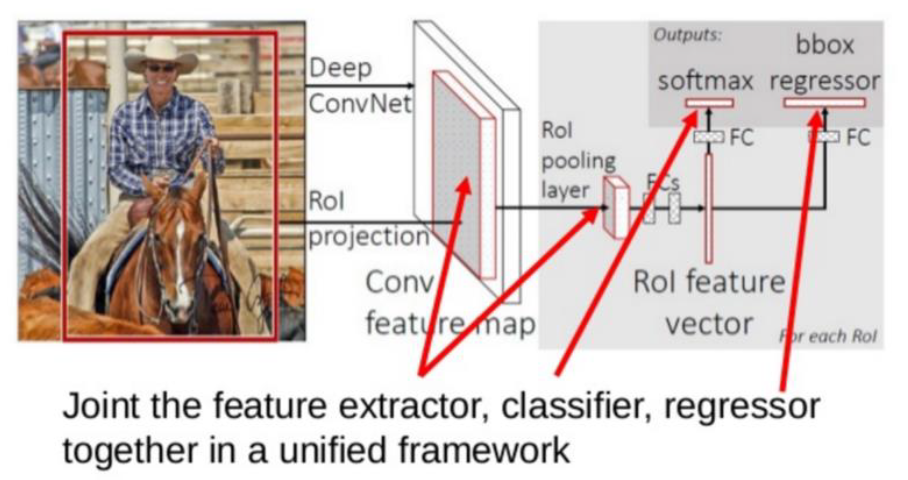
Selective Search를 통해 생성된 2000개의 bounding box들에는 서로 겹치는 영역이 많다. 비효율적!
\(\rightarrow\) (1) Spatial Pyramid Pooling, (2) ROI pooling이 제안됨
(1) Spatial Pyramid Pooling
기존 문제점 )
- 2000여개의 크기가 서로 다른 bounding box들을 warping 하는 과정에 있어서, 왜곡이 발생한다 \(\rightarrow\) 정보 손실
- 그렇다면, 정보 손실 없이, 어떻게 이미지의 차원을 맞출까?
해결책 )
-
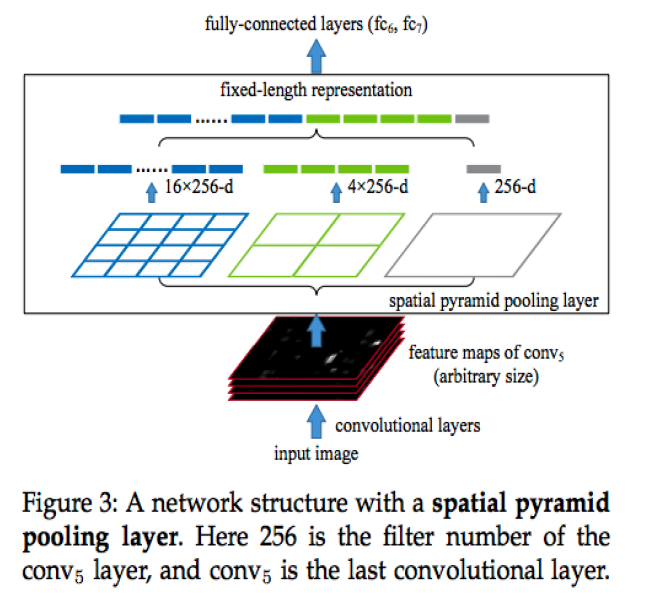
[step 1] Input Image 크기 무관하게, 일단 Conv Layer를 통과시킨 뒤, (output size는 서로 다 다를 것이다),
-
[step 2] FC layer 통과 전에 Feature Map들의 크기를 동일하게 해주는 Pooling Layer를 사용하자!
-
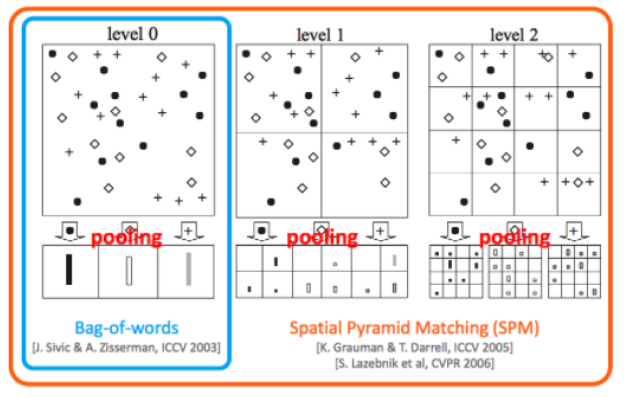
HOW? 이미지를 미리 정해진 일정 구역으로 나눈 뒤, BoW (Bag of Words) 사용!
-
미리 정해진 일정 구역 : 4x4 & 2x2 & 1x1 세 가지 pyramid
( 어떤 image가 들어와도, 해당 구역에 맞게 들어간다 )
-
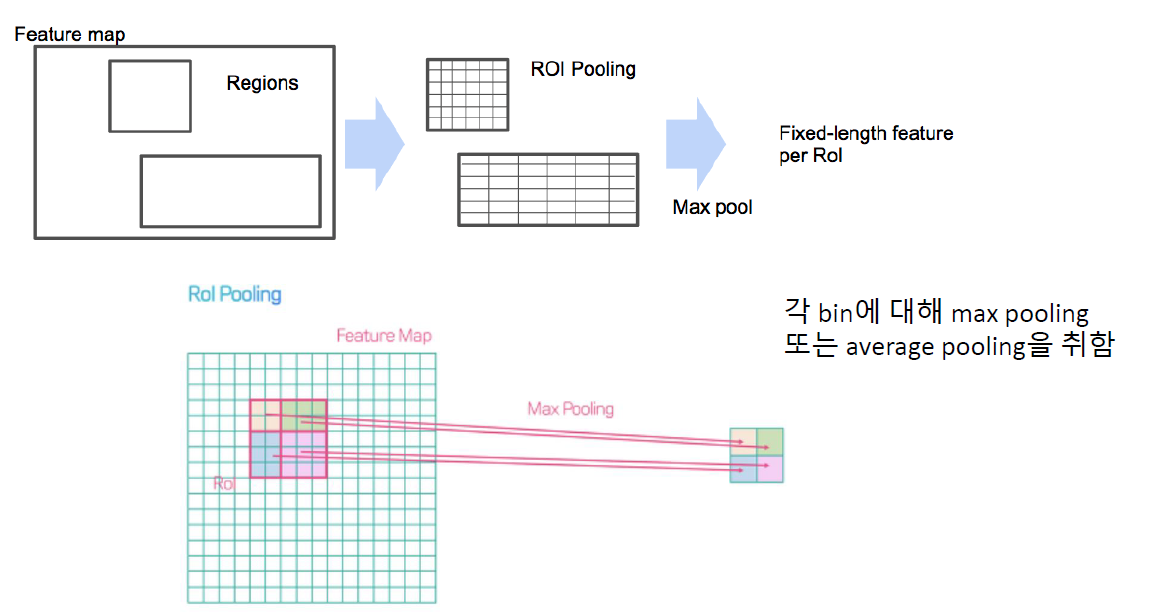
(2) ROI Pooling ( Region of Interest Pooling )
관심 영역 (Region of Interest)
-
어떠한 다른 크기의 image가 들어와도, 동일한 \(a \times b\)의 box로 나눈 뒤 (=bin),
각 bin에 max/average pooling을 수행함
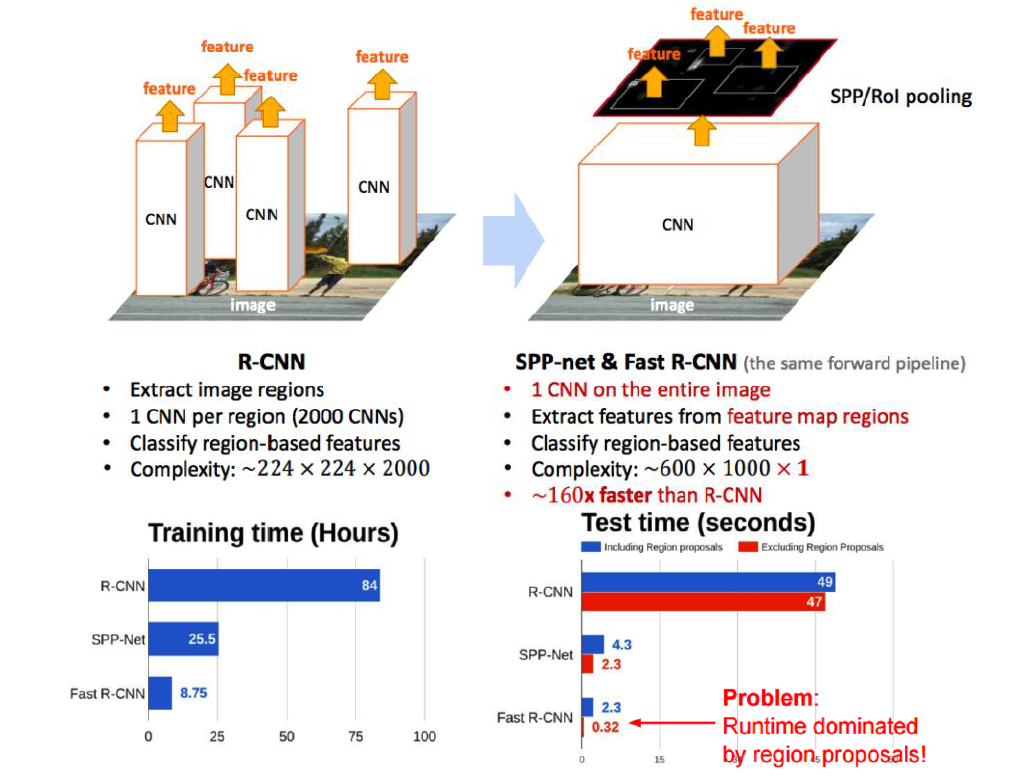
Summary (R-CNN vs Fast R-CNN)
R-CNN
-
selective search한 2000개 각각에 대해 CNN
\(\rightarrow\) 1개의 image에 대해서 2000개의 CNN을 돌려야함
Fast R-CNN
-
ROI pooling을 사용한다는 점
\(\rightarrow\) 1개의 image에 대해서 1개의 CNN만을 돌리면 됨
-
R-CNN보다 160배 빨라짐
3. Faster R-CNN (2015)
(1) Fast R-CNN의 Region Proposal 문제점
Fast R-CNN에는 여전히 Region Proposal에서의 한계점이 있었다.
많은 연산량을 차지하는 region proposal 생성 방식을 새롭게 대체!
\(\rightarrow\) 모델 내부로 통합시키기! Region Proposal Networks (RPNs)
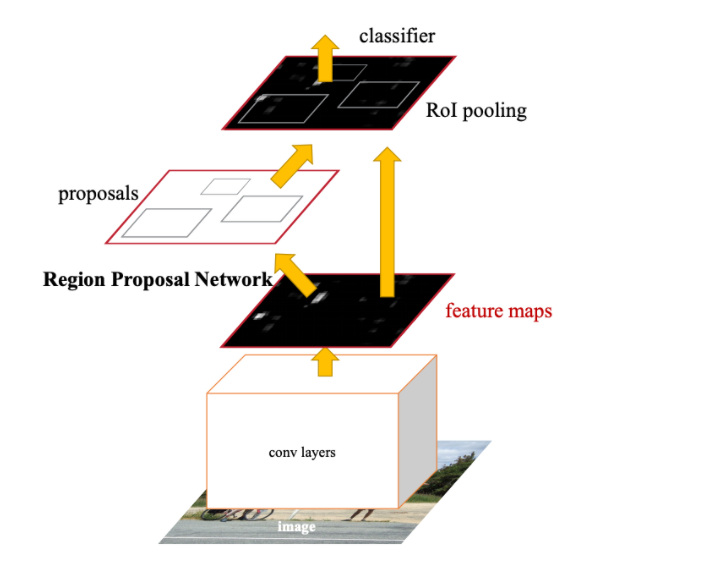
selective search 대신, RPN을 사용하여 RoI를 계산하자!
- Proposal 이전에 (1) Feature Map을 추출한 뒤, RPN을 통해 ROI를 찾는다!
- ROI Pooling 이후 Classification을 수행
(2) Region Proposal Networks (RPNs)
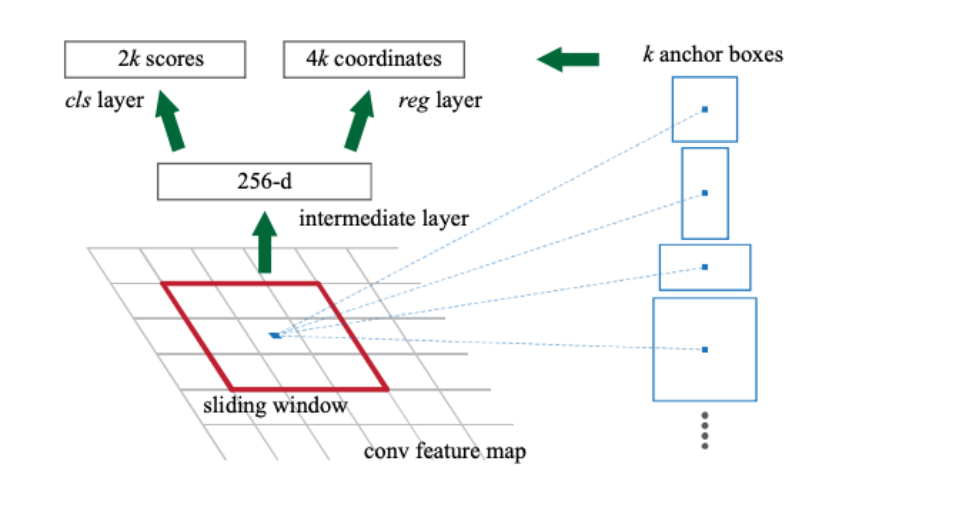
- [Input] 이미지의 feature map
- (아직 proposal region이 정해지 않은, 하나의 통째의 image다)
- [Output] (1) & (2)
- (1) 사각형의 Object Proposal
- (2) Objectness Score
a) Anchor Box
- (기존) 각각의 grid는 오직 한 개의 물체만을 인식할 수 있었음
- “물체의의 midpoint”를 포함하는 grid에 할당
- (Anchor Box 사용 시) 각각의 grid에 여러 개의 물체 인식 가능!
- '’물체의 midpoint”를 포함하는 grid 중, Anchor box들과 가장 큰 IoU를 가지는 grid에 할당
- \(k\)개의 Anchor Box 사용 ( 일반적으로 5 ~ 10 )
- paper ) 3가지 크기 x 3가지 비율 ( 128,256,512 x 2:1,1:1,1:2 ) 제안
b) Details of RPN
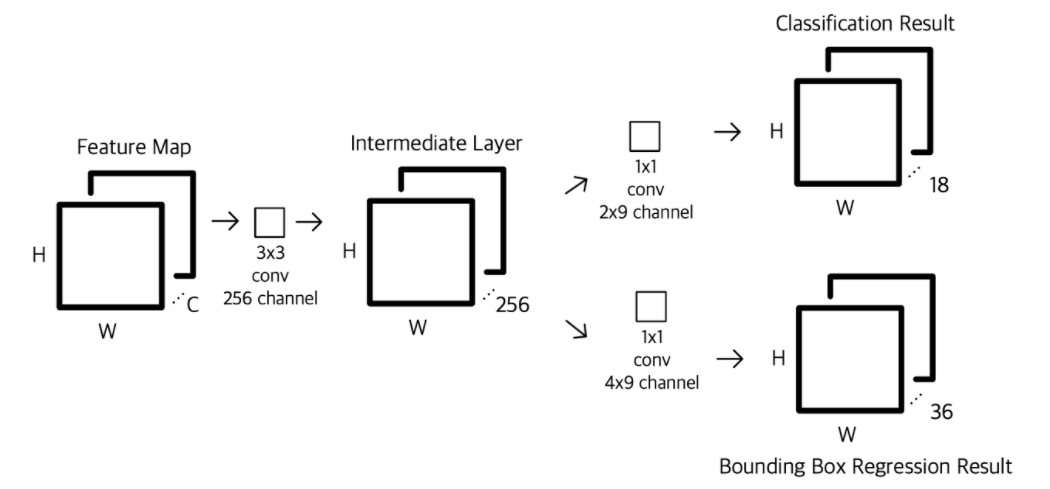
( 출처 : https://yeomko.tistory.com/17?category=888201 )
-
step 1) Feature Map (A) 을 input으로 받는다
-
step 2) 3x3x256 conv layer ( = intermediate layer ) 를 통과 하여 Feature Map (B)를 얻는다
-
step 3) Feature Map (B)를 input으로 입력받아서,
- 3-1) classification
- 3-2) bounding box regression
값을 계산한다 ( with 1x1 conv )
3-1) classification 상세
- 1 x 1 conv을, 2 (Object 존재 여부 0/1) x \(k\) (Anchor 개수) 채널 수 만큼 수행
- 그 결과, \(H \times W \times 2k\)의 feature map을 얻는다
- (1) \(H \times W\) : Feature Map의 좌표
- (2) \(2k\) 개의 channel : \(k\)개의 Anchor Box들이 Object인지 여부를 예측하는 값
- 마지막으로 softmax 수행하여 classification 수행
- 결론 : 1 x 1 conv 한번 만으로도, \(H \times W\)개의 Anchor 좌표 값들에 대한 예측 수행!
3-2) bounding box regression 상세
- 1 x1 conv을, \(k\) (Anchor 개수) 채널 수 만큼 수행
- 그 결과, \(H \times W \times k\)의 feature map을 얻는다
c) Loss Function
총 4가지의 loss를 결합하여 최종 loss function 사용
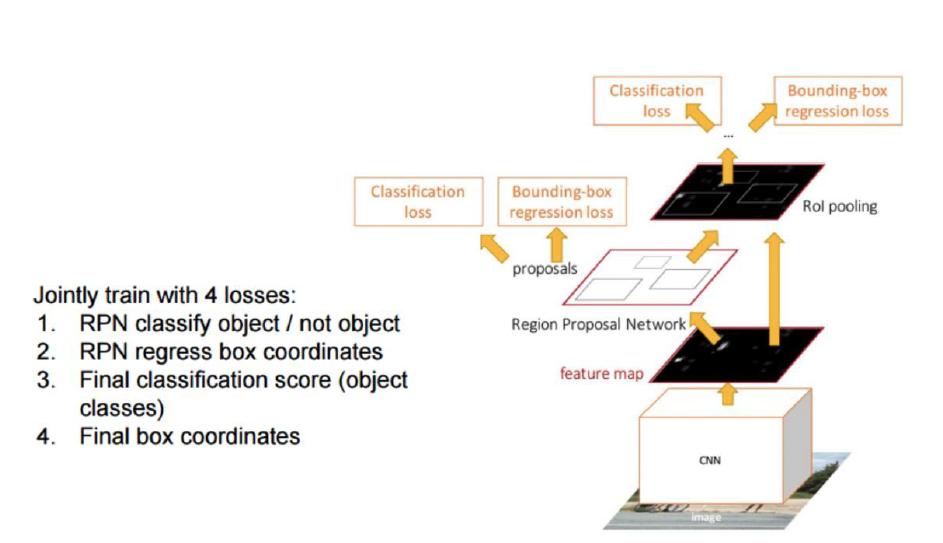
- Loss 1) RPN에서 Classification loss (Object 유무 예측 loss)
- Loss 2) RPN에서 Regression loss (Bounding box regression의 loss)
- Loss 3) 최종 Classification loss (Object 유무 예측 loss)
- Loss 4) 최종 Regression loss (Bounding box regression의 loss)