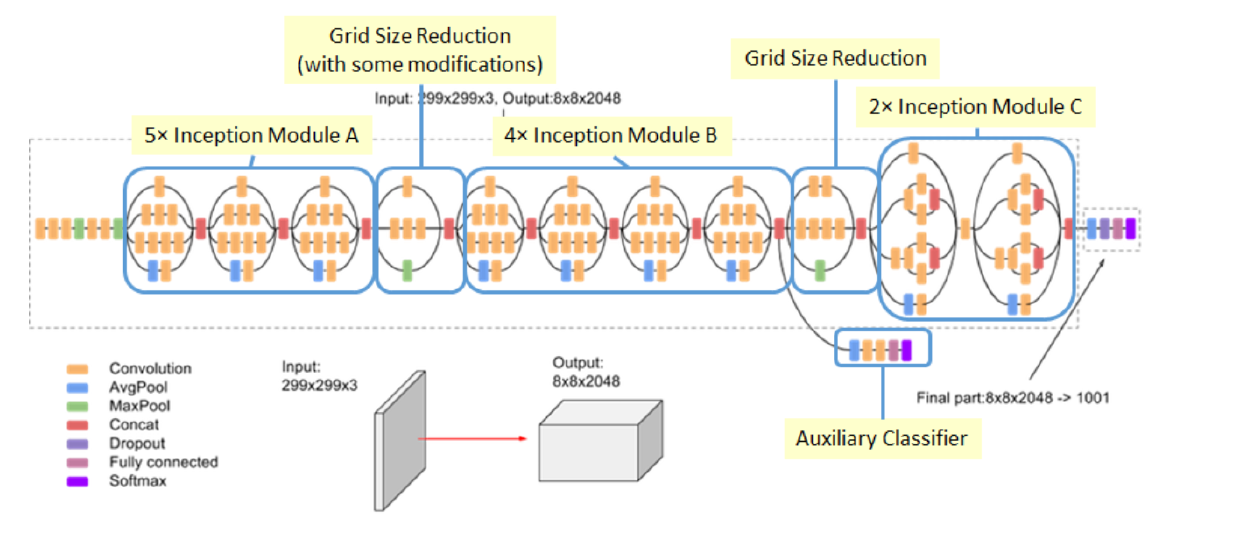
( 참고 : Fastcampus 강의)
[ Inception v1,v2,v3 ]
Inception v1
- Paper: Going deeper with convolutions
- Paper address:https://arxiv.org/pdf/1409.4842.pdf
Inception v2
- Paper: Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Paper address:https://arxiv.org/pdf/1502.03167.pdf
Inception v2
- Thesis: Rethinking the Inception Architecture for Computer Vision
- Paper address:https://arxiv.org/pdf/1512.00567.pdf
1. Inception 등장배경
Going Deeper! 더 좋은 성능
[ Deep Network의 문제점/해결책 ]
문제점 1. 학습이 오래 걸린다
“많은 파라미터 수 & 연산량”
- 문제점 1-1) 많은 파라미터 수
- 해결책 1-1) 1x1 conv & Tensor Factorization
- tensor factorization : 같은 행렬을 다른 여러 행렬로 분해하여 parameter 수 줄이기
- 해결책 1-1) 1x1 conv & Tensor Factorization
- 문제점 1-2) 많은 연산량
- 해결책 1-2) matrix 연산을 Dense하게
문제점 2. 학습이 어렵다
Gradient Vanishing & Overfitting
-
문제점 2-1) Gradient Vanishing ( 깊은 layer까지 전달되면서 정보 손실 )
- 해결책 2-1) auxiliary layer 사용
-
문제점 2-2) Overfitting
- 해결책 2-2) sparse convolution
Sparse Convolution & Dense matrix multiplication을 위해…
GoogLeNet은 아래와 같은 Inception Module을 제안함!
2. Inception Module
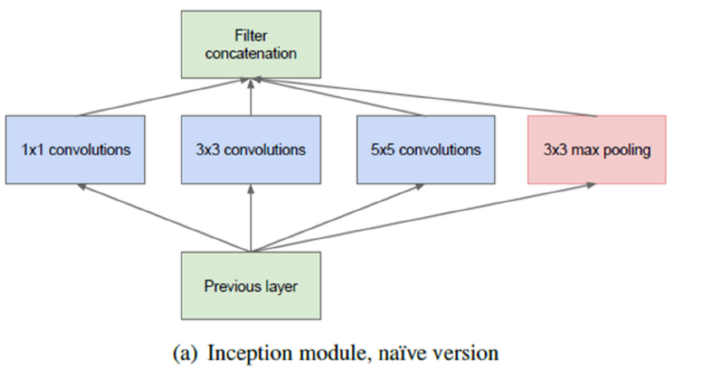

- 다양한 feature를 뽑아내기 위해, 병렬적으로 여러 convolution 사용 ( sparse structure)
- 그런 뒤, 마지막에 이들을 모두 concatenate ( dense matrix )
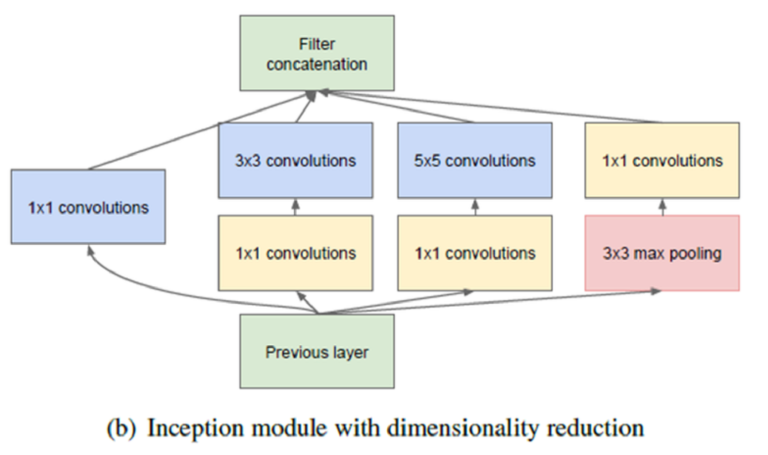
하지만, 위와 같은 Module보다 더 나은 버전은 아래와 같다.
\(\rightarrow\) 1x1 conv 사용
( dimension reduction & MLP 효과 & 채널 수 조절 가능 )
3. Inception V1 ( = GoogLeNet )
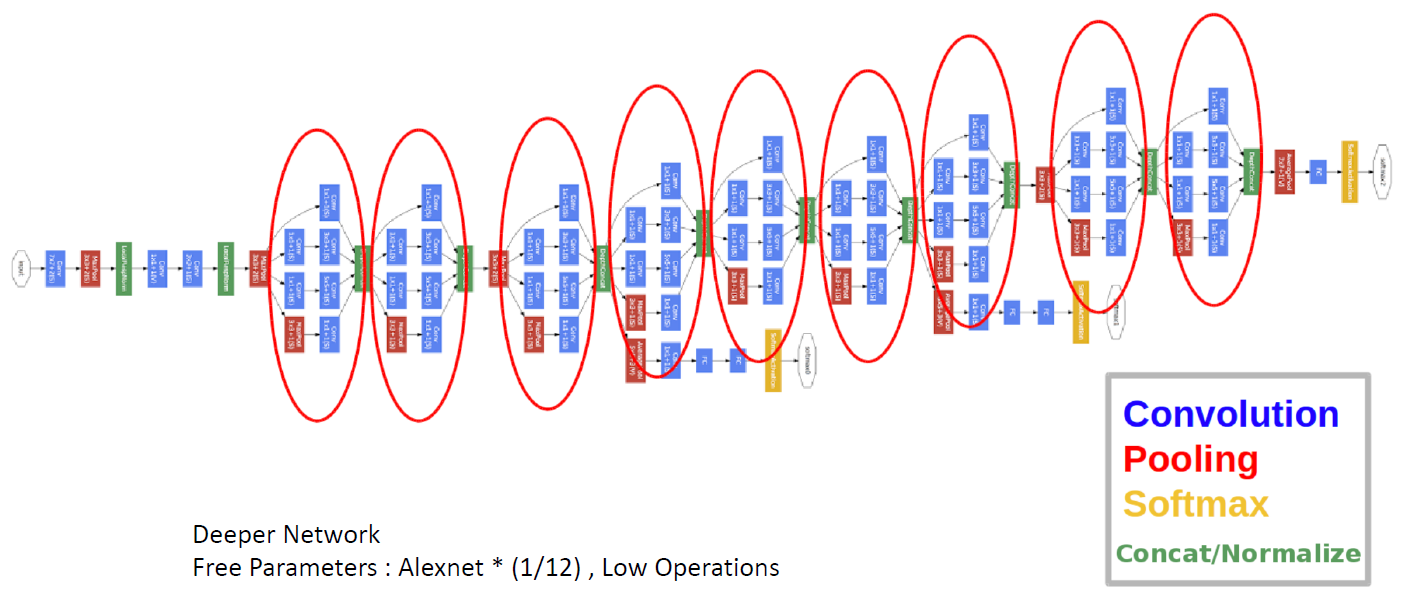
(1) Inception 모듈 사용
- 위에서 언급
(2) Auxiliary Classifier
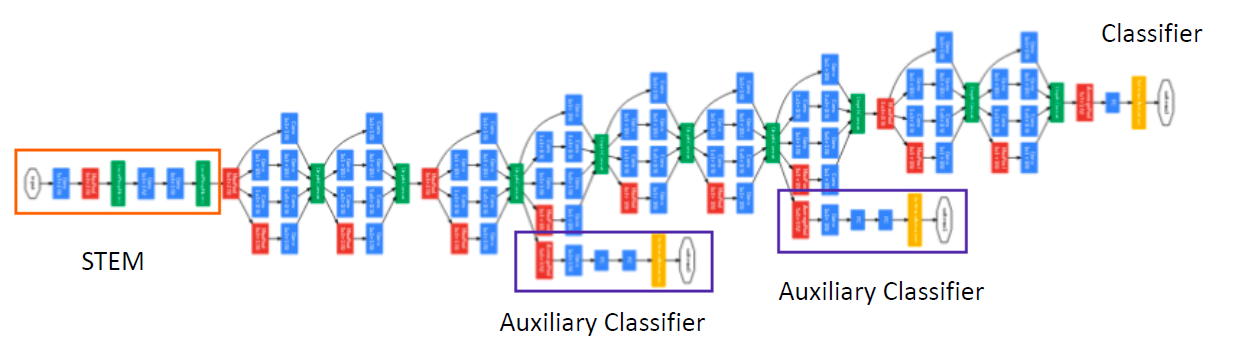
- layer 중간 중간에, 보조 분류기(Classifier)를 둔다
- Training 단계에서 사용하는 loss function에는, auxiliary classifier의 loss도 포함된다
- total_loss = real_loss + 0.3 * aux_loss_1 + 0.3*aux_loss_2
- Test(Inference) 단계에서는 사용 X
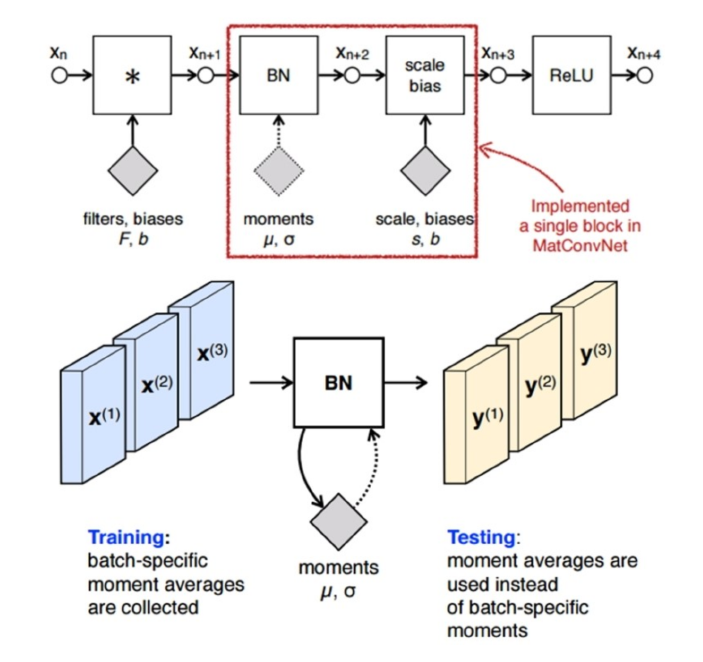
3. Inception V2 ( = BN-Inception )
Batch Normalization을 사용한 Inception
- (주로) Non-linear activation을 거치기 이전에 (mini-batch 단위로) normalize를 수행한다.
- scale & shift도 하는데, 이 값 또한 학습과정에서 update된다

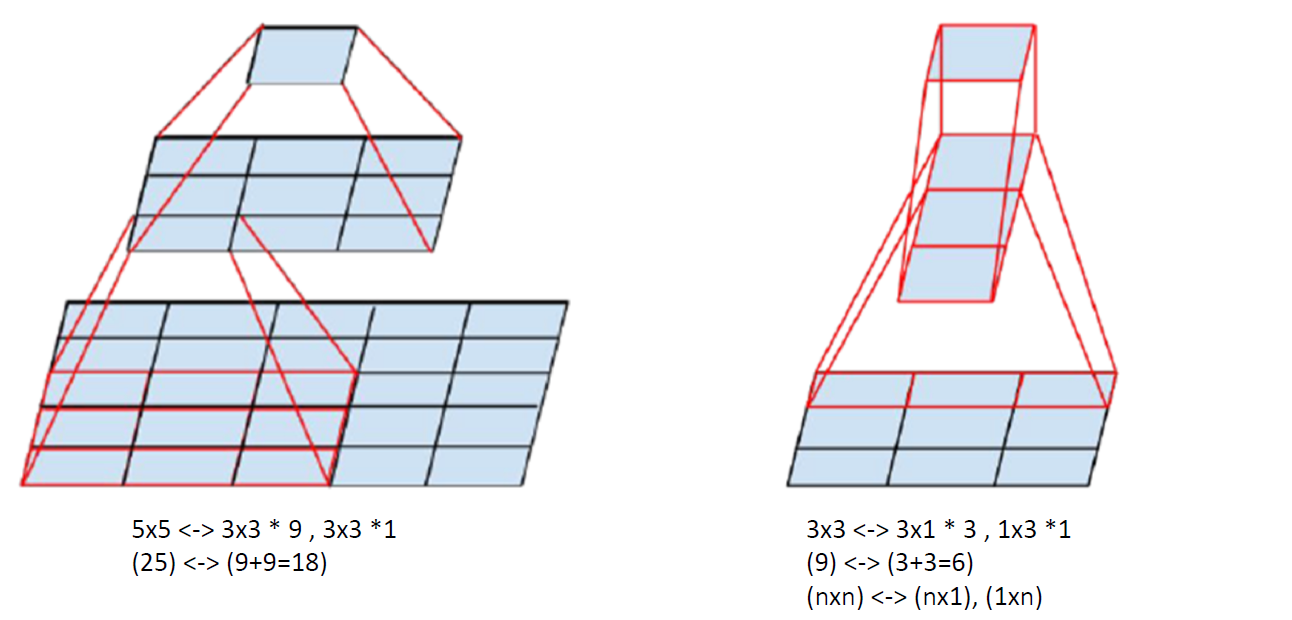
4. Tensor-Factorization
아래 그림을 통해, parameter 수가 얼마나 줄어들 수 있는지를 알 수 있다.
-
ex) \(n \times n\) 대신에, \(n\times 1\)와 \(1\times n\)으로 나눔!
\(\rightarrow\) \(n^2\)에서 \(2n\)으로 줄어듬
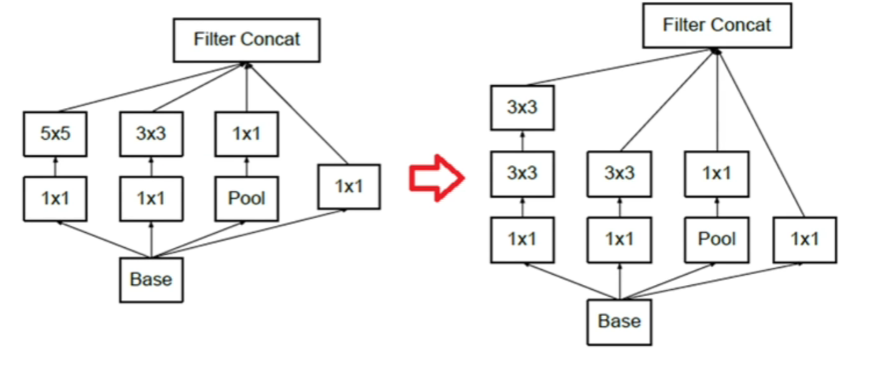
5. Inception v2의 module
(1) Inception Module A
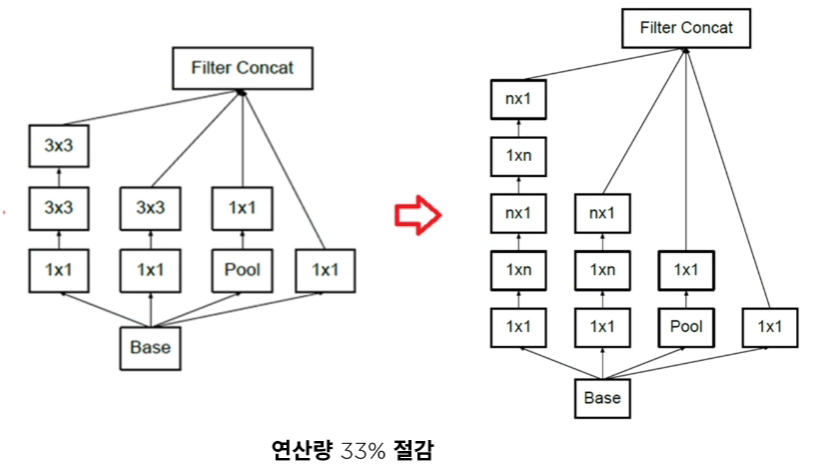
아래 Inception V2에서는, tensor factorization을 사용하여 \(5 \times 5\) convolution을 \(3 \times 3\) 두 번에 걸쳐서 한 것을 확인할 수 있다.
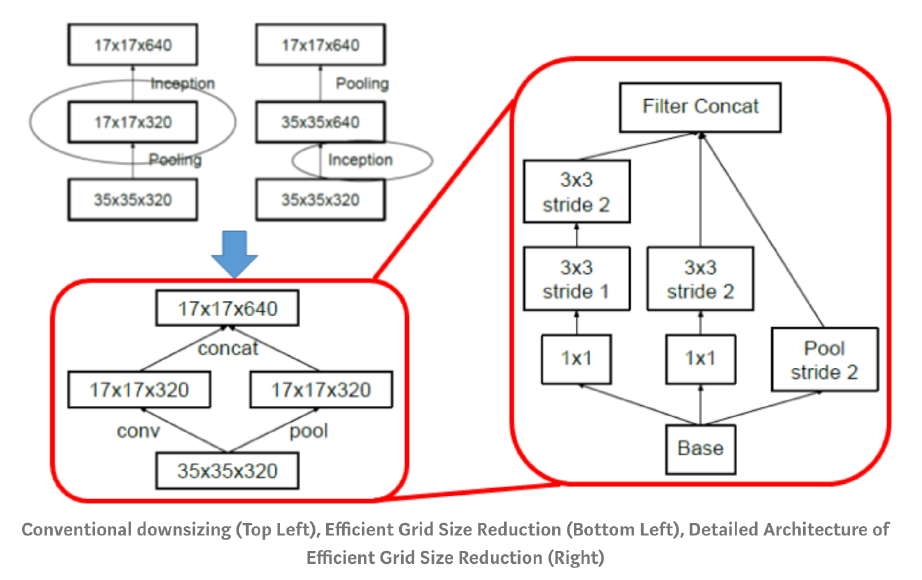
6. Grid Reduction module
CNN에서 해상도를 줄이기 위해서 주로 사용하는 방식
- 1) stride 2 이상
- 2) pooling
Pooling 먼저? Convolution 먼저?
-
Pooling 먼저할 경우 : 정보 손실 문제 (Representational Bottle Neck)
-
CNN 먼저할 경우 : 연산량 과다 문제
각각의 장/단이 있다!
\(\rightarrow\) 이 둘을 섞어 쓰기 위한 Grid Reduction
7. Inception v3의 module
(1) Inception Module B
Inception V3에서는, V2에서와 마찬가지로, 아래와 같이 tensor factorization을 통해 연산량을 절감한다.
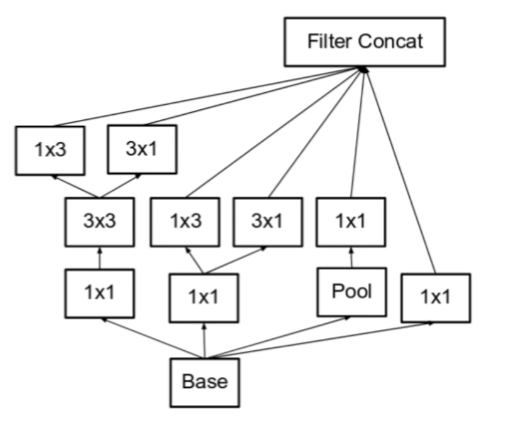
(2) Inception Module C
Representation Bottleneck 문제를 줄이기 위해, 아래 그림과 같이 더 깊게 말고 더 넓게 expand 한 형태이다.
이는 주로 output layer 부근에서 사용된다
Summary
Inception V3 = “Inception Module A+B+C & Grid Reduction module”
( + Auxiliary Layer가 줄어듬. 그닥 효과가 X을 확인함 )