( 참고 : Fastcampus 강의 )
[ MobileNet, SqueezeNet, DenseNet ]
1. Introduction
Key Point : 성능이 전부가 아니다! “속도/효율성”도 중요하다!
- ex) MobileNet, SqeezeNet
어떻게 하면 보다 효율적인 Convolution을 할 수 있을까?
Three purposes : 높은 정확도 / 작은 연산량 / 작은 용량
2. MobileNet (2017)
경량화 모델의 대표적인 알고리즘
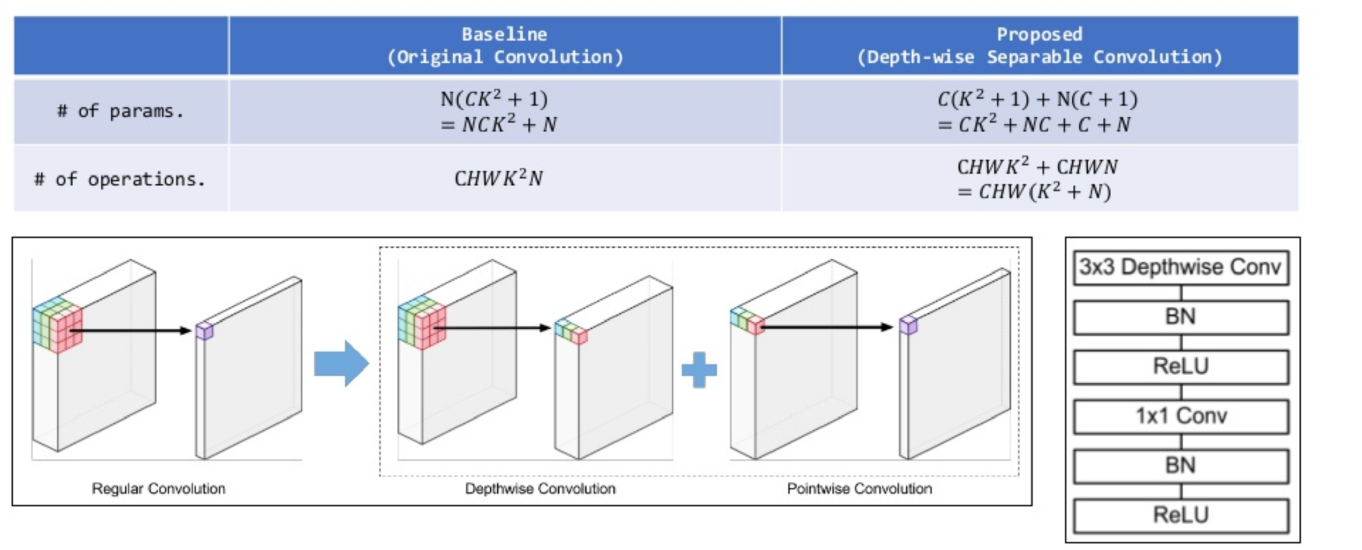
핵심 : Depthwise Convolution & 1x1 conv
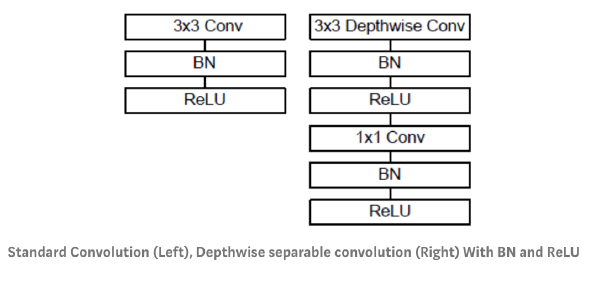
(1) Depthwise Convolution
Mobile Net은 (1) + (2)를 함께 사용한다.
- (1) Depthwise Convolution
- 각 channel 별 정보만을 이용하여 convolution 수행
- (2) Pointwise Convolution ( = 1x1 conv )
- channel 간 weighted sum
- dimension reduction의 효과
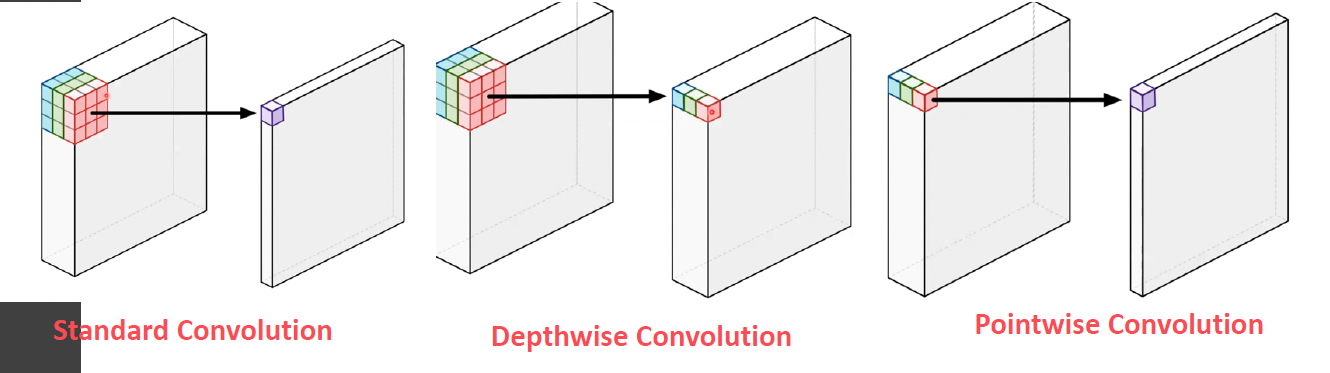
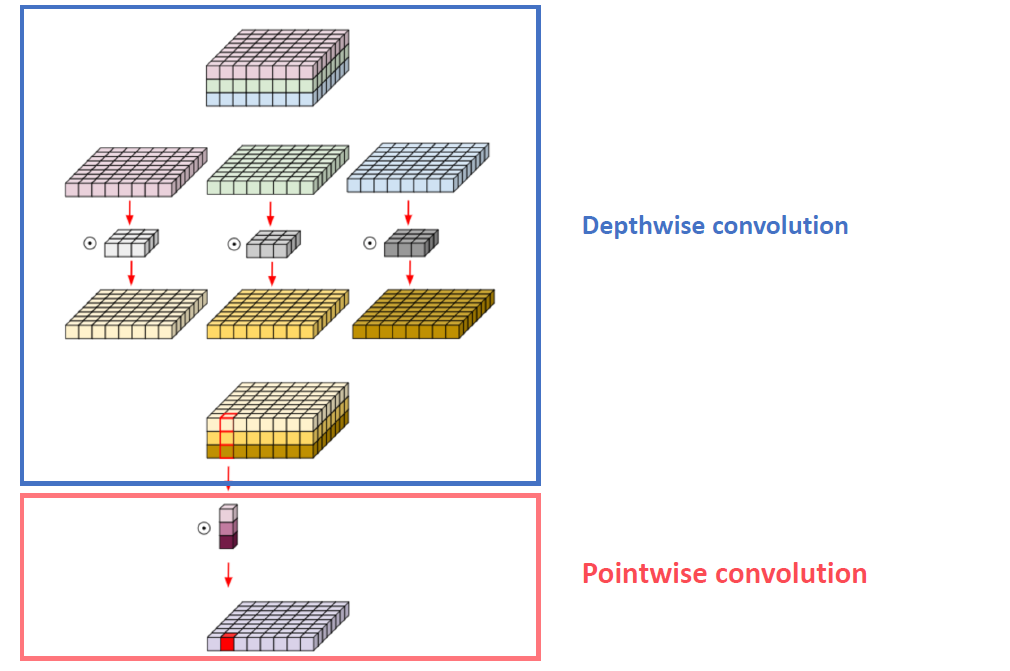
(2) Depthwise Convolution의 장점
필요한 parameter 수의 획기적 감소!
( 출처 : https://www.slideshare.net/NaverEngineering/designing-moreefficient-convolution-neural-network-122869307)
(3) Multiplier
(1) Width Multiplier (\(\alpha\))
- 네트워크의 width를 결정하는 파라미터
- 각 layer의 input & output channel의 크기를 \(\alpha\) 비율만큼 조절
(2) Depth Multiplier (\(\rho\) )
- input resolution(해상도)를 결정하는 파라미터
3. Squeeze Net (2016)
(1) Fire Module
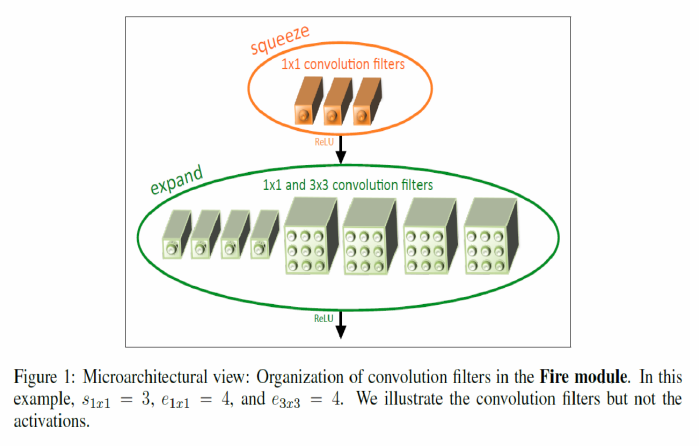
a) Squeeze Layer
- 1x1 conv layer를 사용하여 channel reduction (원하는 채널 수로 줄이기)
b) Expansion Layer
-
위 (1)의 1x1 conv layer 뿐만 아니라, 3x3 conv layer를 함께 사용 ( 병렬적으로 사용 )
-
Padding을 사용하여, 두 layer의 output size가 서로 일치하도록 맞춰줌
c) Squeeze Ratio
- squeeze layer에서 expansion layer로 갔을 때 input channel수가 얼마나 줄어드는지를 조절하는 파라미터
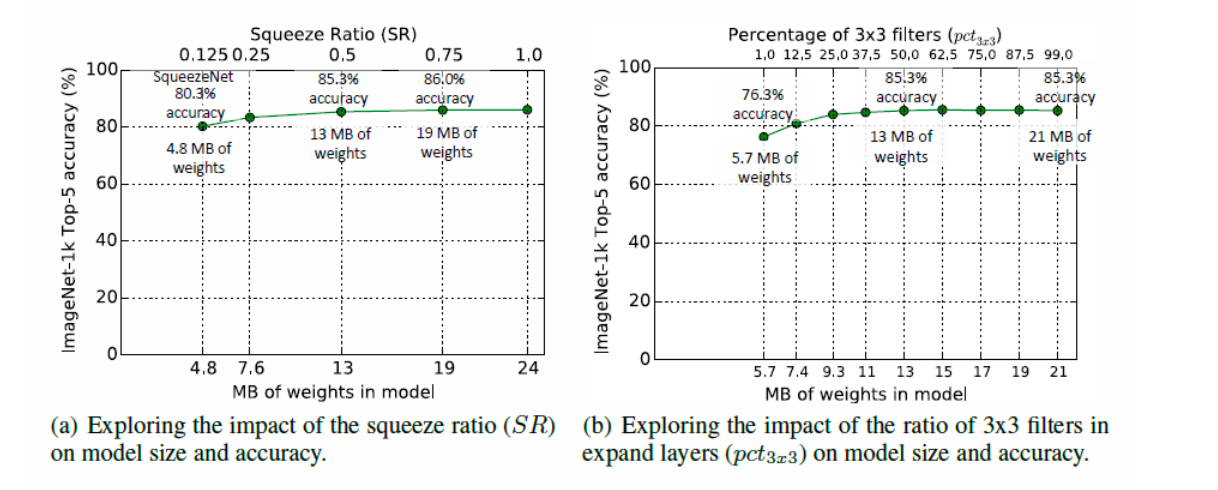
(2) Bypass
보다 성능을 높이기 위해 사용하는 방식
- single / complex bypass
- single bypass가 조금 더 나은 성능을 보인다.
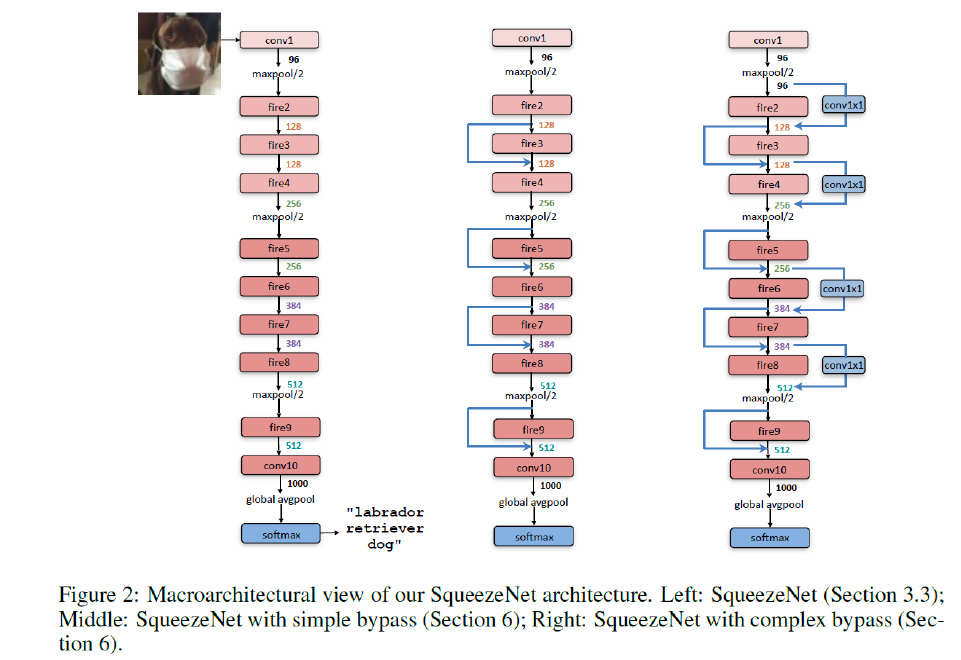
(3) Summary
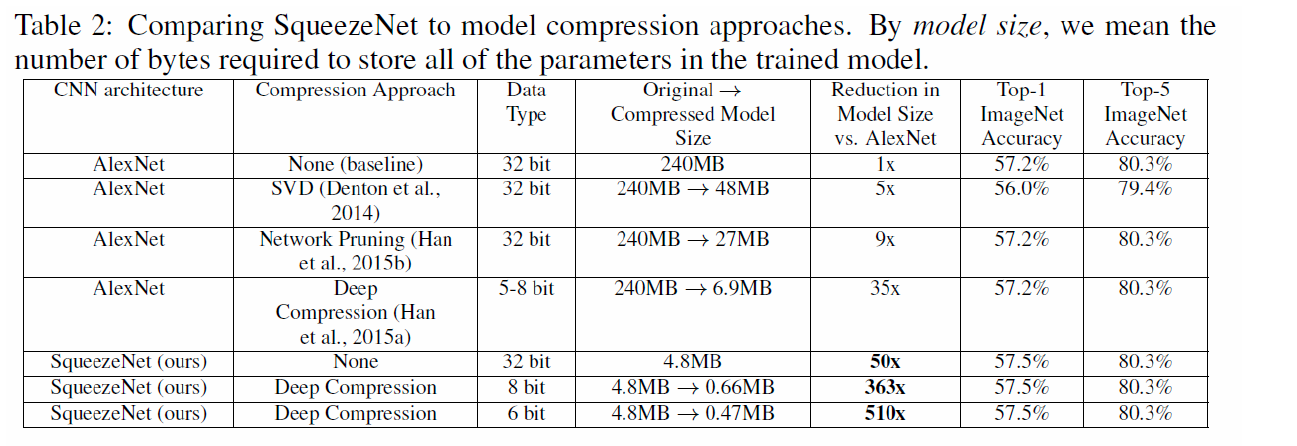
AlexNet에 여러 compression 방법론을 사용한 것들과 Squeeze Net을 비교한 결과이다.
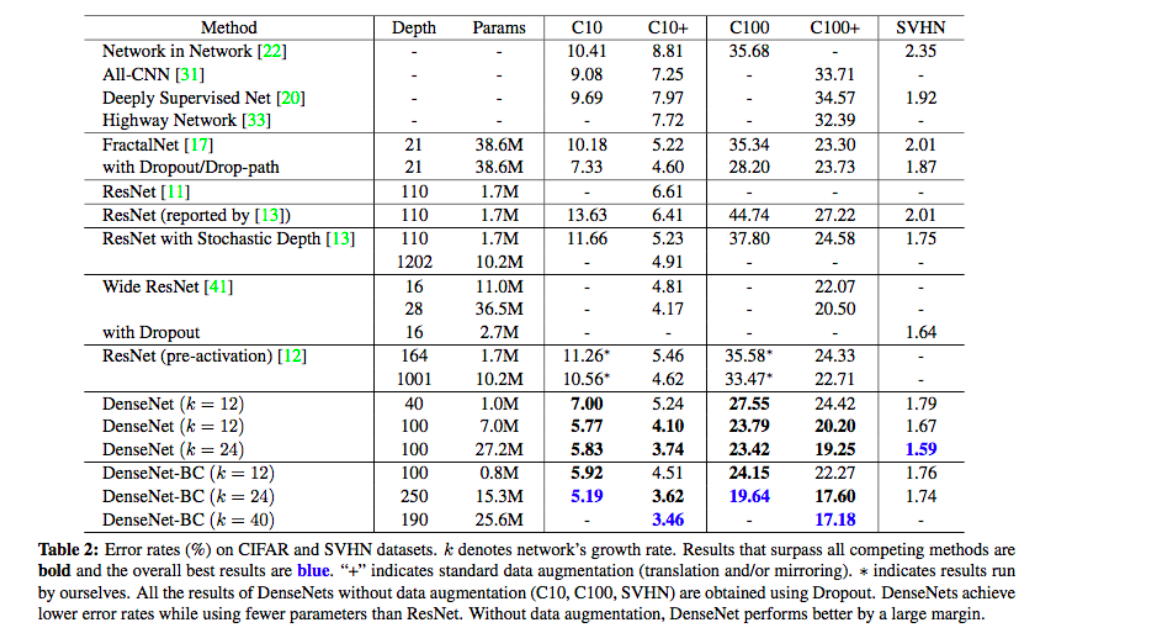
4. DenseNet (2016)
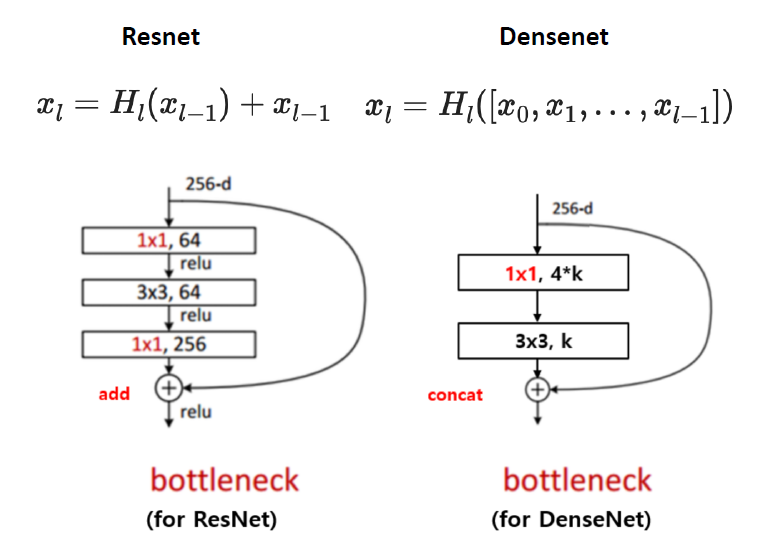
(1) ResNet vs DenseNet
-
ResNet : residual connection을 사용하여, function이전 값을 “더해줌”
-
DenseNet : ~ function이전 값을 “concatenate 해줌”
-
concatenate하여 늘어나게 되는 정도를 growth rate를 통해 조절한다
-
“bottle neck layer 뒤 1x1 conv”의 과정으로 expansion을 따로 하지 않음
( 그것을 대신 concatenation으로 확장/늘려줌 )
-
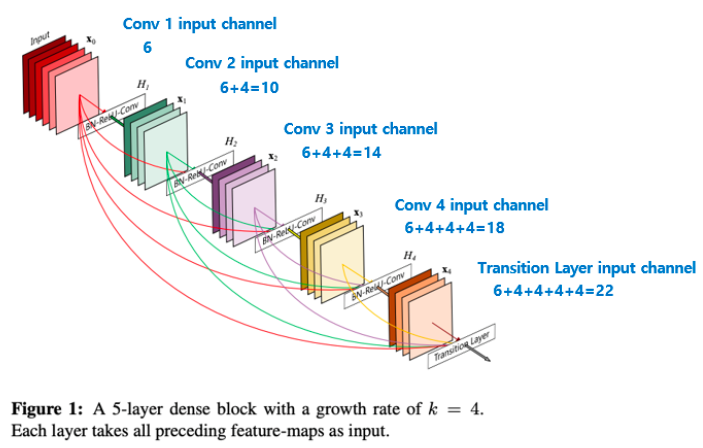
(2) Overall Architecture
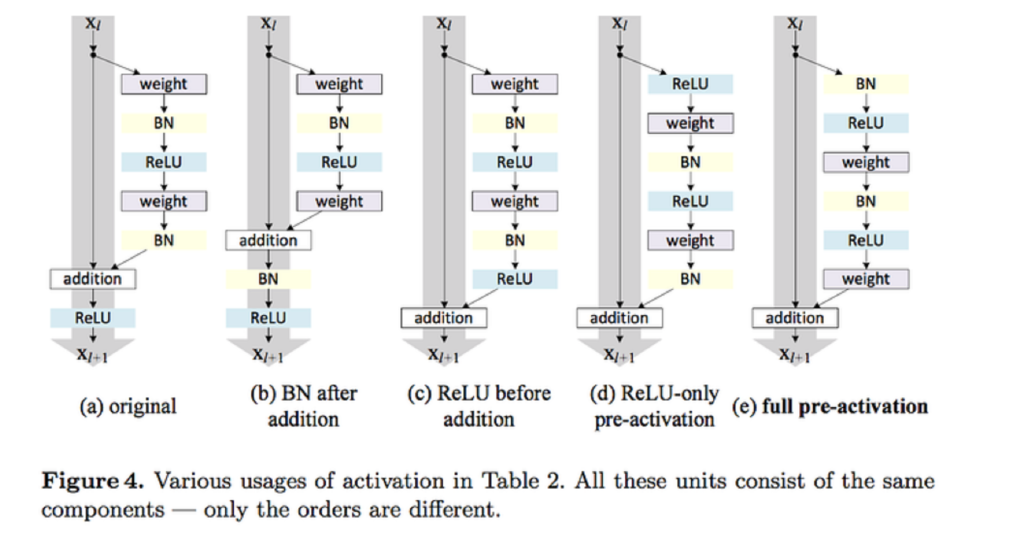
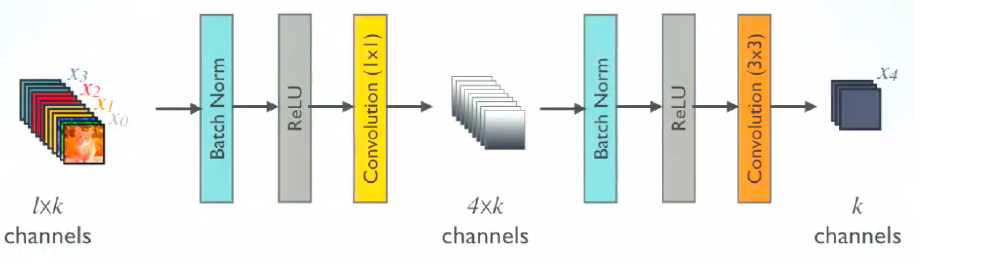
(3) Pre-activation
-
Weight/Activation/Batch Normalization의 순서 관련한 문제
-
일반적) weight가 먼저
-
Pre-activation) BatchNorm 먼저
( BatchNorm \(\rightarrow\) ReLU \(\rightarrow\) Convolution 순으로 )
-
(4) Bottle Neck Architecture
마찬가지로 1x1 conv (=bottle neck 구조)를 사용하여 dimension을 reduction한 뒤 output들을 concatenate한다.
(5) Experiment