
Auto Encoder
1. Introduction
Auto Encoder의 목적
- 주어진 데이터의 ‘압축된 표현’ (latent representation) 찾기!
- 입력 데이터에 유용한 변환을 수행하기 위해, 그 속의 ‘내재적인 특징’을 찾기! ex) 잡음 섞인 음성 데이터 -> 잡음을 제거한 ‘원본’데이터 찾아내기
Auto Encoder 개요
- 입력 데이터의 분포를 ‘저차원’으로 인코딩
- 잠재 벡터 ( latent vector ) : 저차원으로 인코딩 된 벡터 ( 이 잠재 벡터가 decoder에 들어가서 디코딩된다 )
- 핵심 : decoder에서 복원된 출력이, 입력과 얼마나 유사한가?
2. Auto Encoder의 원리
Auto Encoder은 다음과 같이 두 부분으로 구성된다
- 1 ) Encoder
- 2 ) Decoder
Encoder
- 입력 데이터를 잠재 벡터로 변환 시키는 역할
- 입력 데이터의 ‘핵심’이 되는 부분만을 잘 담아서 저차원으로 인코딩하는 것이 핵심!
- 잠재 벡터 : \(z = f(x)\)
- 수식 : \(p(z\mid x)\)
Decoder
-
Encoder에서 생성된 잠재 벡터를 입력으로 받아, 최대한 원래의 입력(인코더의 입력)과 유사하게끔 복원해내는 것이 핵심!
-
수식 : \(p(x\mid z)\)
-
손실 함수(Loss Function)을 통해 복원된 입력과, 원래의 입력이 얼마나 다른 지 확인!
\[L = -logp(x\mid z)\]ex) MSE, Binary Cross Entropy(=Log Loss), Structural Similarity Index
위에서 설명하는 Encoder은, 우리에게 낯선 개념이 아니다. PCA(Principal Component Analysis)도 결국 Encoder라고 볼 수 있다. 하지만, Auto Encoder에서 말하는 Encoder은 ‘비선형 함수’가 사용하다는 점에서 (선형 함수만을 이용한) PCA보다 더 나은 성능을 보인다고 할 수 있다. 위에서 말하는 Encoder와 Decoder은 모두 ‘비선형 함수’를 사용하기 때문에, Neural Net을 이용할 수 있다.
Auto Encoder의 핵심적인 내용은 다음 그림을 통해서 쉽게 이해할 수 있다.
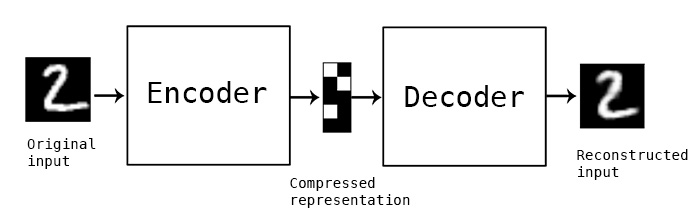
https://blog.keras.io/img/ae/autoencoder_schema.jpg
숫자 ‘2’의 사진을 Encoder의 input으로 넣고, Encoder는 그 사진의 함축된 표현 (latent vector, 잠재 벡터)를 찾아낸다. 그렇게 해서 찾아낸 잠재 벡터를 Decoder의 input으로 넣으면, Decoder은 원본과 유사한 숫자 ‘2’의 사진을 만든다.
3. DAE (Denoising Auto Encoder)
DAE(Denoising AUto Encoder)는 잡음 제거 오토인코더이다. 말 그대로, 잡음을 제거하는 오토인코더이다. 예를 들어, 위의 예시에서 숫자 ‘2’ 사진에 잡음(noise)이 얹혀진 사진이 있다고 해보자. 이러한 지저분한(?) 사진을 Encoder에 넣어서, 최종적으로 (Decoder의 출력으로) 잡음이 제거된 온전한 숫자 ‘2’의 사진이 나오는 것이 이 DAE의 목표라고 할 수 있다.
들어오게 되는 input은 다음과 같다.
\[x = x_{orig} + noise\]따라서, 최소화해야하는 Loss function은 다음과 같다.
\[L = (x_{orig},\widetilde{x}) = MSE = \frac{1}{m} \sum_{i=1}^{m}(x_{orig},\widetilde{x})^2\]( 여기서 \(\widetilde{x}\) 는 Decoder가 만들어낸 출력이다. )
아래의 그림을 통해 쉽게 이해할 수 있을 것이다.
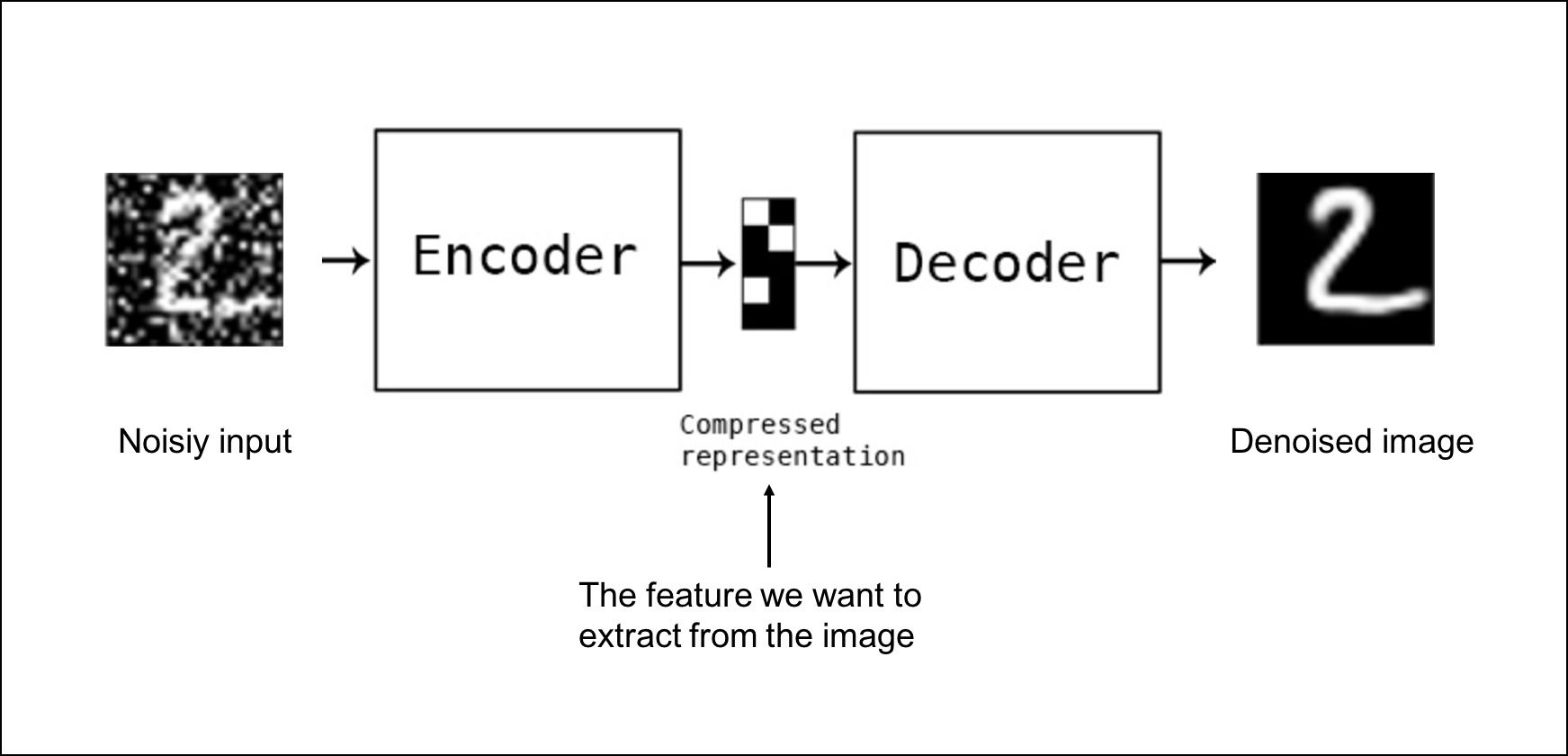
4. Conclusion
Auto Encoder는 잡음 제거 및 채석 등의 변환을 하기 위해 입력 데이터의 함축된 표현(저차원 벡터, latent vector)로 나타낸다. 이를 통해 latent vector를 찾아내면, 입력 복원은 물론이고, 아예 새로운 데이터 및 사진 또한 생성할 수 있다. (GAN) 다음 포스트에서는 GAN에 대해 다룰 것이다.