
GloVe(Global Vectors for Word Representation)
( 참고 : “딥러닝을 이용한 자연어 처리 입문” (https://wikidocs.net/book/2155) )
- 기본의 카운트 기반의 LSA & 예측 기반의 Word2Vec의 단점을 보완!
- word2vec와 비슷한 성능!
1. LSA & Word2Vec의 한계
-
1) LSA = DTM이나 TF-IDF 행렬과 같이 “단어의 빈도수”를 기반으로 한 방법론
-
2) Word2Vec = 실제값 & 예측값의 오차를 줄여나가는 “예측 기반”의 방법론
-
LSA는 단어의 의미를 유추하는 작업에서 성능이 떨어진다는 단점 (ex 왕:남자 = 여왕:?)이,
Word2Vec는 임베딩 벡터가 window 크기 내의 단어만을 고려하기 때문에 corpus의 전체적인 통계정보를 반영하지 못한다는 단점이 있음
이 둘의 단점을 보완하기 위해, 이 두가지 방법론을 모두 사용하는 GloVe!
- LSA의 “단어 빈도수” : Window based Co-occurence Matrix
- Word2Vec의 “예측 기반” : Loss Function
2. Window based Co-occurence Matrix
i 단어의 윈도우 크기(Window Size) 내에서 k 단어가 등장한 횟수를 i행 k열에 기재한 행렬

3. Co-occurence Probability
| 동시 등장 확률 P(k | i) = 동시 등장 행렬로부터 특정 단어 i의 전체 등장 횟수를 카운트하고, |
특정 단어 i가 등장했을 때 어떤 단어 k가 등장한 횟수를 카운트하여 계산한 조건부 확률
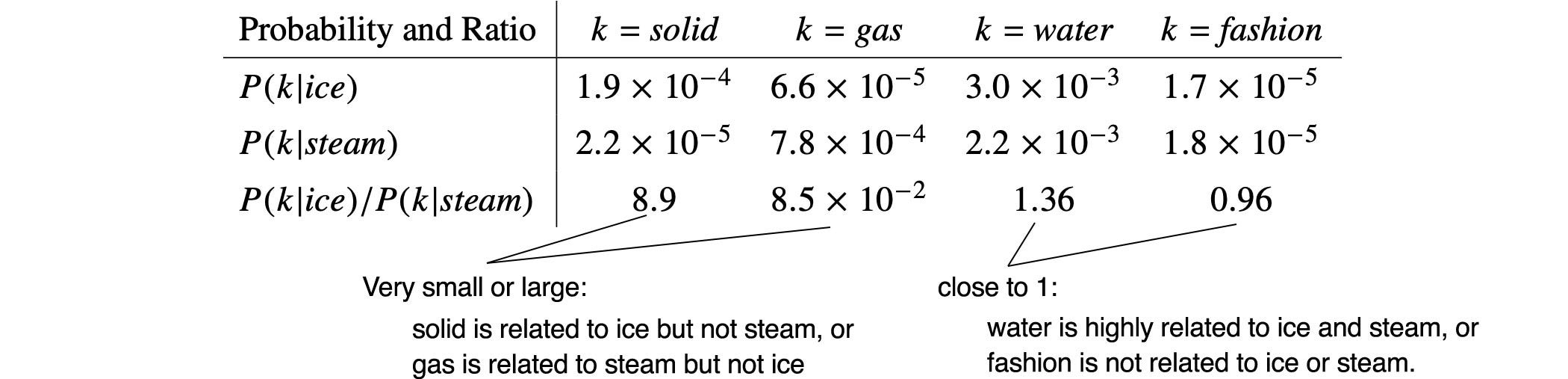 .
.
4. Loss Function
Notation
-
\(X:\) Co-occurrence Matrix
-
\(X_{i j}:\) 중심 단어 \(i\)가 등장했을 때 윈도우 내 주변 단어 \(j\)가 등장하는 횟수
-
\(X_{i}= \sum_{j} X_{i j}:\) Co-occurrence Matrix에서 \(¡\)행의 값을 모두 더한 값
-
\(P_{i k}: P(k \mid i)=\frac{X_{i k}}{X_{i}}:\) 중심 단어 \(i\)가 등장했을 때 window 안에 주변 단어 \(k\)가 등장할 확률
Ex) \(\mathrm{P}(\) solid \(\mid\) ice \()=\) 단어 ice가 등장했을 때 단어 solid가 등장할 확률
- \(w_{i}:\) 중심 단어 \(i\)의 embedding vector
- \(\tilde{w}_{k}:\) 주변 단어 \(k\)의 embedding vector
Main Idea : “임베딩 된 중심 단어와 주변 단어 벡터의 내적이, 전체 코퍼스에서 동시 등장 확률이 되도록 만드는 것”
위의 main idea를 수식으로 표현하자면, 다음과 같다.
-
dot product \(\left(w_{i} \tilde{w}_{k}\right) \approx P(k \mid i)=P_{i k}\)
-
GloVe는 위의 \(P_{ik}\)값에 log를 씌워서 모델링한다.
\(\rightarrow\) \(\operatorname{dot} \operatorname{product}\left(w_{i} \tilde{w}_{k}\right) \approx \log P(k \mid i)=\log P_{i k}\)
위의 3. Co-occurence Probability에서의 idea대로, GloVe는 아래의 식을 손실함수로 정의한다.
\(F\left(w_{i}, w_{j}, \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}}\).
\(F\left(w_{i}-w_{j}, \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}}\) .
\(F\left((w_{i}-w_{j})^T \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}}\).
위의 함수\(F\) 는 “Homomorphism”(준동형)을 만족시켜야 하는데, 쉽게 말해 \(F(a+b)=F(a)F(b)\)를 만족시켜야 한다는 것이다. 그 이유는, 우리가 중심단어 \(w\)와 주변 안더 \(\tilde{w}\)를 무작위로 선택을 하더라도 자유롭게 교환 가능해야하기 때문이다.
이를 만족시키는 \(F\)는 아래와 같이 표현할 수 있다.
\(F\left(\left(w_{i}-w_{j}\right)^{T} \tilde{w}_{k}\right)=F\left(w_{i}^{T} \tilde{w}_{k}-w_{j}^{T} \tilde{w}_{k}\right)=\frac{F\left(w_{i}^{T} \tilde{w}_{k}\right)}{F\left(w_{j}^{T} \tilde{w}_{k}\right)}\).
위 조건을 만족시키는 대표적인 함수 \(F\)가 바로 exponential function이다. \(F\)를 이와 같이 지정하고, 위 식을 다시 적으면 아래와 같다.
\(\exp \left(w_{i}^{T} \tilde{w}_{k}-w_{j}^{T} \tilde{w}_{k}\right)=\frac{\exp \left(w_{i}^{T} \tilde{w}_{k}\right)}{\exp \left(w_{j}^{T} \tilde{w}_{k}\right)}\).
\(\exp \left(w_{i}^{T} \tilde{w}_{k}\right)=P_{i k}=\frac{X_{i k}}{X_{i}}\).
이를 통해, 우리는 아래와 같은 식을 얻을 수 있다.
\(w_{i}^{T} \tilde{w}_{k}=\log P_{i k}=\log \left(\frac{X_{i k}}{X_{i}}\right)=\log X_{i k}-\log X_{i}\).
위 식에서, 우리는 어떠한 단어 \(w_{i}\) 와 \(\tilde{w}_{k}\)를 고르던지 위 식이 성립해야 한다. 따라서, \(w_{i}\) 와 \(\tilde{w}_{k}\) 또한 위 식에서 교환가능해야 하지만, 이를 막는 것이 \(\log X_{i}\) term이다. ( \(\log X_{i k}\)의 경우, \log X_{k i}와 동일하므로 상관없다 )
따라서, 위의 \(\log X_{i}\) term을 없애고, 이 대신 bias term을 추가하여 아래와 같은 식을 완성한다.
\(w_{i}^{T} \tilde{w}_{k}+b_{i}+\tilde{b_{k}}=\log X_{i k}\).
위의 과정들을 통해 산출한 최종적인 Loss Function은 다음과 같다.
- Loss function \(=\sum_{m=n=1}^{V}\left(w_{m}^{T} \tilde{w}_{n}+b_{m}+\tilde{b_{n}}-\log X_{m n}\right)^{2}\).
위의 Loss Function을 보완한 더 나은 Loss Function이 있다. 이는, 동시 등장 빈도가 낮은 \(X_{ik}\)값의 경우, 학습에 거의 도움이 되지 않기 때문에, 이를 고려하여 weight를 부여하기 위해 다음과 같은 weighting function \(f(X_{ik})\)를 도입한다.
- \(f(x)=\min \left(1,\left(x / x_{\max }\right)^{3 / 4}\right)\).
 .
.
따라서, 최종적인 Loss Function은 아래와 같다.
- Loss Function : \(\sum_{m, n=1}^{V} f\left(X_{m n}\right)\left(w_{m}^{T} \tilde{w}_{n}+b_{m}+\tilde{b_{n}}-\log X_{m n}\right)^{2}\).
5. 실습
from glove import Corpus, Glove
- word2vec 실습에서 사용한 데이터로
import re
from lxml import etree
from nltk.tokenize import word_tokenize,sent_tokenize
targetXML = open('ted_en-20160408.xml','r',encoding='UTF8')
target_text = etree.parse(targetXML)
parse_text = '\n'.join(target_text.xpath('//content/text()')) # <content> ~ </content> 사이 내용 가져오기
# (Audio), (Laughter) 등의 배경음 부분을 제거
content_text = re.sub(r'\([^)]*\)','',parse_text)
# 문장 토큰화
sent_text = sent_tokenize(content_text)
# 구두점 제거 & 소문자화
normalized_text = []
for string in sent_text:
tokens = re.sub(r'[^a-z0-9]+', ' ', string.lower())
normalized_text.append(tokens)
result = [word_tokenize(sentence) for sentence in normalized_text]
corpus = Corpus()
corpus.fit(result,window=5)
glove = Glove(no_components=100, learning_rate=0.05)
glove.fit(corpus.matrix, epochs=20, no_threads=4, verbose=True)
glove.add_dictionary(corpus.dictionary)
model_result1 = glove.most_similar('university')