
3.Supervised Learning of Universal Sentence Representations from Natural Language Inference Data (2018)
목차
- Abstract
- Introduction
- Related work
- Approach
- NLI task
- Sentence encoder architecture
Abstract
focus on representation of sentences! ( = sentence embeddings )
Show how “universal sentence representations” trained using the supervised data of SNLI can outperform unsupervised methods ( ex. SkipThough vectors )
1. Introduction
word embedding : carry meaning of word
sentence embedding : not only the meaning of word, but also its relationship!
use sentence encoder model!
- Q1 ) what is the preferable NN architecture?
- Q2 ) how & what task should such a network be trained?
sentence embeddings, generated from models trained on NLI task reach the best result!
2. Related work
Most approaches for sentence representations are unsupervised.
3. Approach
combine 2 research directions
- 1) explain how NLI task can be used to train universal sentence encoding models, using SNLI task
- 2) describe the architectures for sentence encoder
3-1. NLI task
SNLI data :
- 570k human-generated English sentence pairs
- three categories )
- 1) entailment
- 2) contradiction
- 3) neutral
Models can be trained on SNLI in 2 different ways.
-
1) sentence encoding-based models,
that explicitly separate the encoding of individual sentence
-
2) joint methods that allow to use encoding of both sentence
\(\rightarrow\) use 1) model
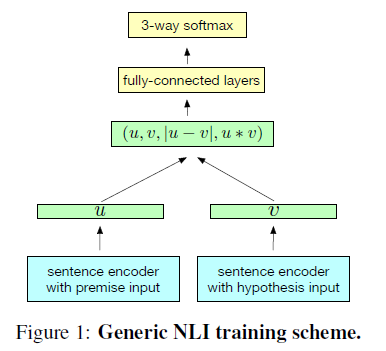
3-2. Sentence encoder architecture
7 different architectures
3-2-1. LSTM & GRU
-
use LSTM or GRU modules in seq2seq
-
for sequence of \(T\) words, network computes a set of \(T\) hidden representations \(h_1,...,h_T\), with \(h_{t}=\overrightarrow{\operatorname{LSTM}}\left(w_{1}, \ldots, w_{T}\right)\)
- a sentence is represented by the last hidden vector, \(h_T\)
- also use BiGRU
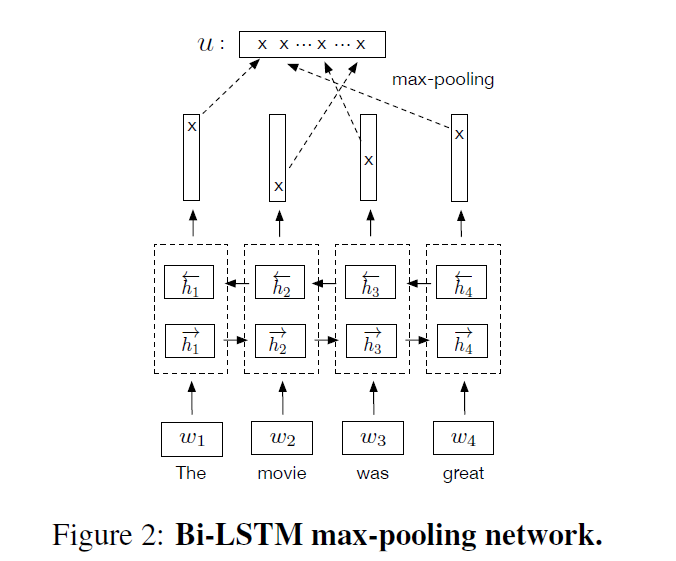
3-2-2. BiLISTM with mean/max pooling
-
For a sequence of T words \(\left\{w_{t}\right\}_{t=1, \ldots, T},\)
-
\(\begin{aligned} \overrightarrow{h_{t}} &=\overrightarrow{\operatorname{LSTM}}_{t}\left(w_{1}, \ldots, w_{T}\right) \\ \overleftarrow{h_{t}} &=\overleftrightarrow{\operatorname{LSTM}}_{t}\left(w_{1}, \ldots, w_{T}\right) \\ h_{t} &=\left[\overrightarrow{h_{t}}, \overleftarrow{h_{t}}\right] \end{aligned}\).
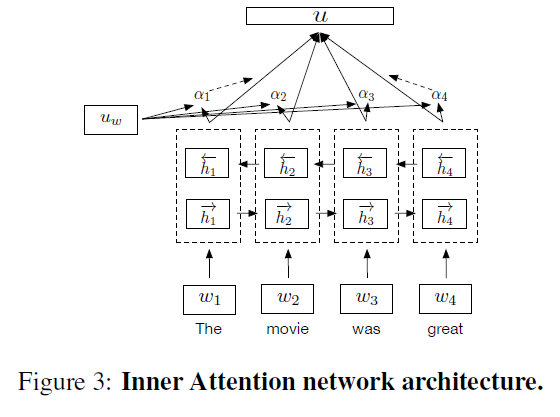
3-2-3. Self-attentive network
-
use attention mechanism over hidden states of BiLSTM
-
\(h\) : output hidden vector
\(\alpha\) : score of similarity
\(u\) : weighted linear combintation
\(\begin{aligned} \bar{h}_{i} &=\tanh \left(W h_{i}+b_{w}\right) \\ \alpha_{i} &=\frac{e^{\bar{h}_{i}^{T} u_{w}}}{\sum_{i} e^{\bar{h}_{i}^{T} u_{w}}} \\ u &=\sum_{t} \alpha_{i} h_{i} \end{aligned}\).
3-2-4. Hierarchical ConvNet
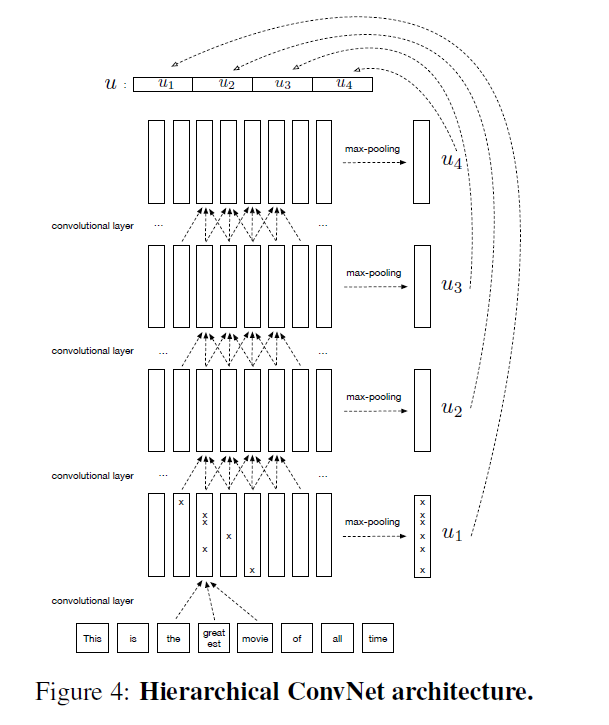
- final representation \(u = [u_1,u_2,u_3,u_4]\) concatenates representations at different levels of input sentence.