
LLM 성능 판단하기
Contents
- 모델 성능의 기점
- 가정 1,2의 문제점
- 모델 성능 측정 방법론
- LLM Judge
- Human Evaluation
- Multiple Choice
- Linguistic Calibration
1. 모델 성능의 기점
Evaluation loss가 가장 작은 것 선택!
\(\rightarrow\) Q) Evaluation loss는 무엇으로 (어떤 데이터로) 선정?
세 가지 가정:
Evaluation용 데이터를 ..
- 가정 1) Ratio 기반으로 구성
- 가정 2) 따로 구성하지 않고, Train loss로 사용할때
- 가정 3) 새롭게 구축 (for 원하는 task의 목적에 맞게!)
비용의 관점에서 봤을 때, 가정 3)이 가장 안좋기는 함.
\(\rightarrow\) 하지만, 가정1), 가정2)를 따르는 것도 큰 문제점이 있음!
2. 가정 1,2의 문제점
가정 1) Ratio 기반으로 구성
- CRD (Completely Random Design)을 따르는 접근법
- 다만, 무작위로 뽑는 방법 자체가 너무 heuristic하다!
가정 2) 따로 구성하지 않고, Train loss로 사용할때
- 눈 가리고 훈련하기
\(\rightarrow\) 두 가정 모두 Eval loss가 낮을 수 있으나, 우리의 목적대로 학습되지 않을 수도!
3. 모델 성능 측정 방법론
(1) LLM Judge
- 가장 간편한 방법 & 많이 사용되는 방식
-
Instruction에 대한 “답변의 적절성을 평가”
- SOTA LLM 사용
- Ex) GPT4, HyperClova X, Gemini 등을 활용
한계점?
-
같은 시행마다 매번 다른 점수(평가)가 나올 수 있음 (due to randomness)
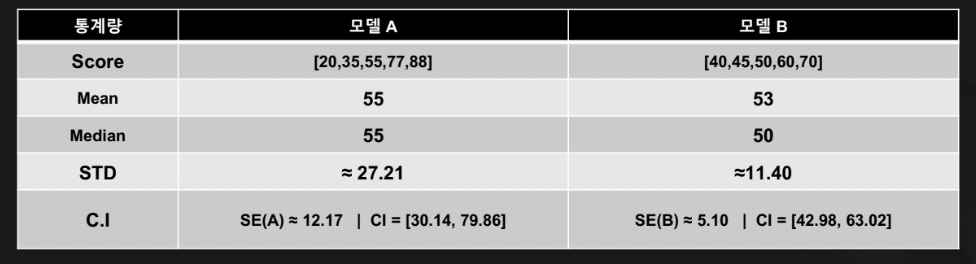
\(\rightarrow\) 시행 횟수를 키워서, 통계적 방법 (평균,분산,신뢰 구간)등을 활용하기!
(2) Human Evaluation
- 가장 비싼 방법 (전문가 필요)
- 정성적인 평가 (인간의 선호를 기반으로 평가)
- 대표적인 방식: Chatbot Arena
Chatbot Arena
- (1) Pairwise Comparison: 익명 모델 A vs. 익명 모델 B
- (2) Elo rating: Pairwise comparison 결과 기반으로, 모델의 점수를 부여하여 순위화
- 한계점) 모델의 템플릿 & 답변 형식에 따라 익명성 오염 될 수도! (모델 유추 가능)
(3) Multiple Choice
- 객관식 풀기
- Metric: accuracy, f1-score
Task 종류
- Comprehensive Korean Benchmarks: KMMLU, HAERAE-Bench
- Common Reasoning: Hellaswag, Winogrande, PlQA. ARC, CommonsenseQA
- World Knowledge and Factuality: Natural Questions, TrivaOA, CLIcK, Factscore
- Mathematics GSM8k, MATH
- Coding Capabilitiess HumanEval, MBPP
- Instruction-Following and Chatting Abilltes: MT-Bench
- Harmlessness: TruthfulaA BOLD
Q) 모델 마다 답변 방식이 다를 수도 있는데?
- ex) 모델 A: “ ~~해서 ~~ 해서 정답은 5야!”
- ex) 모델 B: “정답은 5야. 왜냐하면 ~~야!!”
A) Few-shot으로 prompt에 “예제 문제 &답변 형식”을 준 뒤에 비교하기!
(4) Linguistic Calibration
- DL 모델의 흔한 문제점: Over-confidence
- Calibration을 통해 조절해주기
\(E C E=\sum_{j=1}^N \frac{ \mid B_j \mid }{N} \mid \operatorname{Acc}\left(B_j\right)-\operatorname{Conf} \left(B_j\right) \mid\).
- \(\operatorname{Acc}\left(B_j\right)=\frac{1}{ \mid B_j \mid } \sum_{i \in B_j} 1\left[y^{(i)}=\arg \max _y f\left(x^{(i)}, z^{(i)}\right)_y\right]\).
- \(\operatorname{Conf}\left(B_j\right)=\frac{1}{ \mid B_j \mid } \max _y f\left(x^{(i)}, z^{(i)}\right)_y\).
\(\rightarrow\) 예측 확률 & 실제 결과 사이의 불일치를 측정하는 지표
Reference
https://fastcampus.co.kr/data_online_gpu